同事最近想在新版本的SQL Server追蹤異常的SQL登入(SQL Login Fail),不過同事在舊版本SQL Server都用SQL Trace,來推薦同事改用擴充事件(Extended Event)追蹤登入失敗的錯誤碼18456。
2018-07-06
[SQL Server][擴充事件]稽核SQL Server Login Fail
- 1636
- 0
- SQLExtendedEvent
同事最近想在新版本的SQL Server追蹤異常的SQL登入(SQL Login Fail),不過同事在舊版本SQL Server都用SQL Trace,來推薦同事改用擴充事件(Extended Event)追蹤登入失敗的錯誤碼18456。
上一篇先筆記Realtime的評分預存程序sp_rxPredict給同事看,這篇來筆記SQL 2017推出的原生(Native)述詞- PREDICT,更直覺簡單的寫法。
測試環境訓練好模型,正式上場預測前,我們會需要再建立一段R的評分程式碼,並且以字串的方式包在外部預存程序介面內(sp_execute_external_script),透過讀取序列化後的模型在R的環境執行預測。
但這樣的方式還是多了點麻煩,第一個是程式的可讀性,第二個則是正式環境的資料庫必需依賴R的環境作運算,要解決這個問題,也許可以試試看SQL2016就推出的Realtime評分(sp_rxPredict)或是SQL 2017推出的原生(Native)評分方式,更即時更原生的方式執行。
為了避免SQL Server與AP伺服器傳輸時的內容被攔截竊取後容易解析,我們可以採用加密的傳輸通道,一來可以增加傳輸封包安全性,二來也避免源碼檢測工具打小報告。
以前都是在DB Server手動裝憑證,然後DB匯出,AP伺服器匯入再設定連線字串啟用加密,才能啟用加密連線(大誤)。最近和同事討論,意外發現,即使沒有額外處理憑證,單只要AP連線字串加上TrustServerCertificate=true;Encrypt=true,實際連線時,SQL會自動產生憑證,重要的TDS封包就被加密了,而且專案中的組態檔還可以通過源碼檢測的盤查。
我們有時在SQL Server監控CPU的效能時,會額外多觀察每秒陳述式重新編譯次數(SQL Re-Compilations/sec)的效能計數,透過收集的資訊及後續的調校來降低生產環境出現大量的重新編譯。
最近專案裡,奉旨把SQL程式也加入持續整合(CI)的測試項目內,在掃描SQL程式時發現幾位成員在頻繁的線上交易語法中,使用了少許的暫存資料表(#TABLE),解釋給同事聽,順便筆記可能引發的大量持續不斷的重新編譯。
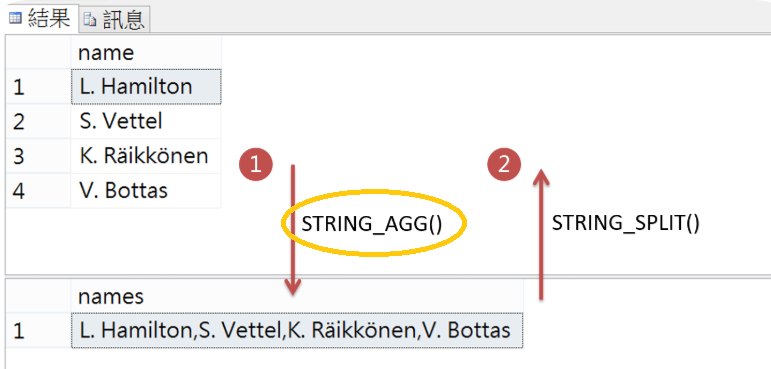
SQL Server 2017推出STRING_AGG 字串集合的串接函式,但限制是SQL2017的版本。上個月重新加入一個大型專案中,專案的版本要求是SQL 2016,Code Review時發現同事改用For Xml Path再Distinct的替代,T-SQL閱讀起來多了點複雜,捲手來救援T-SQL程式的可讀性。
最近同事的程式在兩個專案陸續發生SQLCLR無法載入檔案或組件問題,一個發生在測試環境因為備份還原的場景,另一個則是正式環境突發性的發生,自己太少用SQL CLR了,來試試解題然後筆記。
最近同事在匯入大量資料常碰到SQL Msg 8152, String or binary data would be truncated,中文訊息是是字串或二進位資料會被截斷。
除了找出有問題的資料行與列或是將欄位型別改為varchar(max)兩個方法外,能不能在SQL裡自動截斷過長的資料,不要讓SQL出現錯誤?
最近在駐點的客戶端遇到一個很神奇的問題,剛匯入大筆資料的隔天(50%以上的異動量),同事有一支程式跑了很久都沒執行完,想辦法和AP人員清理舊資料、加索引,更新統計值後,程式瞬間秒殺,但過沒多久,同事另一支類似功能的程式又塞住,這次即使更新統計值、清除plan cache 、Recompile SQL都沒效。
在SQL2016以前,當自動更新統計值選項啟用後,20% + 500筆是一般資料表觸發重新統計的門檻(RT),資料異動累積量達標後,第一個使用統計值的交易會先更新統計值才完成編譯後再實際執行,在某些資料表比較胖的時候,也許先更新統計值再查詢資料的順序可能就會影響OLTP個案交易的執行效能,此時可以試試非同步更新統計值。
上一篇我們注意到統計值(Statistics)不夠即時可能造成SQL Optimizer無法產生最佳的執行計畫,另外也發現自動更新統計值並不是發生在資料更新的同時,而是發生在更新後第一次使用統計值的SQL指令作編譯前,那麼多少的異動量條件會觸發統計值更新?
去年底上線前的一次系統轉換演練,碰到某支轉檔SQL執行變慢,表象是執行計畫改變(plan change),進一步找原因則發現是不太即時的統計值造成Query Optimizer產生較差的執行計畫。
去年底的跨年,終於把駐點14個月的專案上線了,這個客戶和幾年前上線的客戶最近都遇上統計值影響效能,來記錄問題,順便重修統計值(Statistics)。
統計值是描述欄位值與索引欄位值的分佈統計,也是SQL Query Optimizer進行基數估計(cardinality estimate)的分析來源,透過基數預估,進而決策出優秀的執行計畫來擷取或更新資料。
統計值統治的範圍包含一般資料表、#臨時資料表以及幾個新的企業版本@資料表變數都有統計值。
資料庫因為胖胖的讓公司測試環境很擠,但想透過上個月月初備份檔(.bak)還原幾個資料表來比較測試結果,測試環境的空間及資源都不足,當初也沒把幾個資料表放在指定檔案群組(File Group),這次不能使用還原檔案群組招式。
來筆記付費的Third party工具,透過ApexSQL Recover工具,不需要還原整個資料庫就能還原單一資料表。
在SQL 2016以前,Insert Into Select一直都只能用一條執行緒執行資料表插入,SQL Server先在2014版本時優化了Select Into新增了平行,到了SQL 2016版本也優化了Insert Into Select,只要資料庫相容性層級設置為130(SQL 2016),搭配WITH (TABLOCK)的Table Hint,我們也可以在非叢集索引資料表平行執行Insert Into Select了。來筆記實驗過程。

在SQL Server 2014以前,Select Into一直都只能用一條執行緒執行資料表插入,即使Into到tempdb也是;不過到了SQL 2014之後,只要資料庫相容性層級設置為120(SQL 2014)就可以在成本大的語法平行執行Select Into了。來筆記實驗過程。
維護SQL2000的系統要作資料移轉時,除了寫AP程式或是用ETL工具轉換資料,其實也能繼續用舊機卸離 x 新機附加直接移轉user databse的資料庫檔案。
上一篇實驗了移轉SQL2005的檔案到SQL2017,實驗結果可以直升;這次實驗SQL2000的user database,事前從ms blog的討論發現需要先轉到SQL2005或SQL2008,再跳到SQL2017。
這次不用升級SQL Instance版本(就地升級),但要移轉幾個User Database到新機器上新版本的SQL Instance。在學校曾上過SQL 2000的課,幾年前重新接觸SQL Server,已經是SQL 2008R2 ,幾年下來慢慢也從SQL 2008移轉到2012/2014/2016,好在SQL資料庫的相容性,每次都很順利,不過這次是自己沒使用過的SQL 2005,試試SQL2005到SQL2017,一個12生肖的距離。
經過上一篇的實驗,磁碟資料表(Disk-based table)啟用讀取認可快照(RCSI)或是快照隔離(Snapshot isolation)都能到使用資料列版本讀取到前一版的資料而避免封鎖(blocked),特別兩者在處理”資料一致性的層級”以及”交易發生衝突的處理上”有些不同;那麼到了記憶體資料表(Memory-optimized table)?
SQL Server在磁碟資料表(Disk-Base)提供了兩種與快照有關的樂觀鎖定機制: RCSI(Read Committed Snapshot Isolation)及Snapshot Isolation,他們都是減少查詢交易被封鎖的武器之一,當資料被其他交易更新時,這兩種機制都可以透過Tempdb加上row version查詢到資料的前一版,讓交易免於被封鎖(blocked)的命運。明晚要參加SQL Pass,Rico大的主題是進擊的In-Memory OLTP,學習記憶體資料表交易前,先來預習傳統磁碟資料表在這兩種機制下的查詢一致性。