在SQL 2016以前,Insert Into Select一直都只能用一條執行緒執行資料表插入,SQL Server先在2014版本時優化了Select Into新增了平行,到了SQL 2016版本也優化了Insert Into Select,只要資料庫相容性層級設置為130(SQL 2016),搭配WITH (TABLOCK)的Table Hint,我們也可以在非叢集索引資料表平行執行Insert Into Select了。來筆記實驗過程。

測試機器的CPU有16核心,分別使用新舊的相容性層級在user db執行寫入。
建立環境
新增一個InsertIntoSelectDb
CREATE DATABASE [InsertIntoSelectDb]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'InsertIntoSelectDb1', FILENAME = N'F:\Data\InsertIntoSelectDb1.mdf' , SIZE = 4GB , FILEGROWTH = 1GB),
( NAME = N'InsertIntoSelectDb2', FILENAME = N'F:\Data\InsertIntoSelectDb2.ndf' , SIZE = 4GB , FILEGROWTH = 1GB),
( NAME = N'InsertIntoSelectDb3', FILENAME = N'F:\Data\InsertIntoSelectDb3.ndf' , SIZE = 4GB , FILEGROWTH = 1GB),
( NAME = N'InsertIntoSelectDb4', FILENAME = N'F:\Data\InsertIntoSelectDb4.ndf' , SIZE = 4GB , FILEGROWTH = 1GB)
LOG ON
( NAME = N'InsertIntoSelectDb_log', FILENAME = N'F:\Data\InsertIntoSelectDb.ldf' , SIZE = 4GB , FILEGROWTH = 1GB)
GO
新增100萬筆資料
USE [InsertIntoSelectDb]
CREATE TABLE T1
(ID INT IDENTITY,C2 CHAR(100),C3 uniqueidentifier, PRIMARY KEY(ID))
SET NOCOUNT ON
DECLARE @I INT = 0
BEGIN TRAN
WHILE @I < 5000000
BEGIN
INSERT INTO T1
VALUES (CONVERT(VARCHAR,@I),NEWID())
SET @I = @I + 1
END
COMMIT
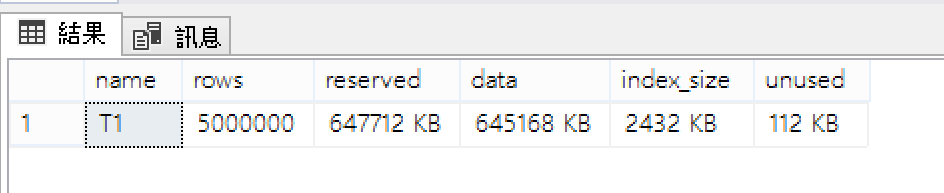
查看測試資料表T1
EXEC sp_spaceused 'T1'
我們有一個600MB的測試資料表了
1.對照組測試(未啟用平行)
設定相容性層級退到110(SQL Server 2012)
ALTER DATABASE [InsertIntoSelectDb] SET COMPATIBILITY_LEVEL = 110;
GO
執行Insert Into Select 測試
USE InsertIntoSelectDb
SET STATISTICS IO ON
SET STATISTICS TIME ON
CREATE TABLE T1_1
(
ID INT ,
C2 CHAR(100),
C3 uniqueidentifier,
)
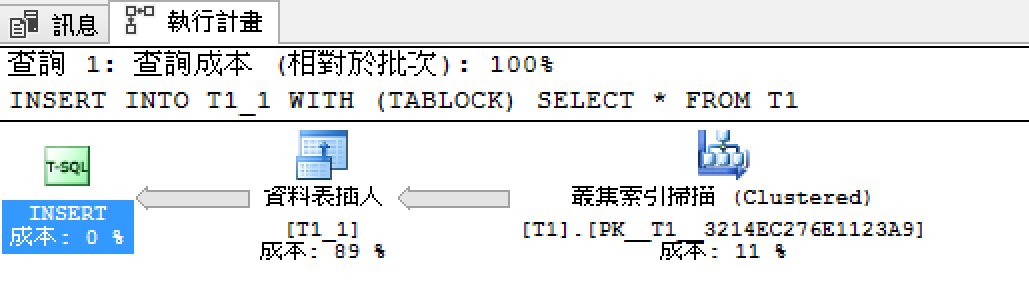
INSERT INTO T1_1 WITH (TABLOCK) SELECT * FROM T1
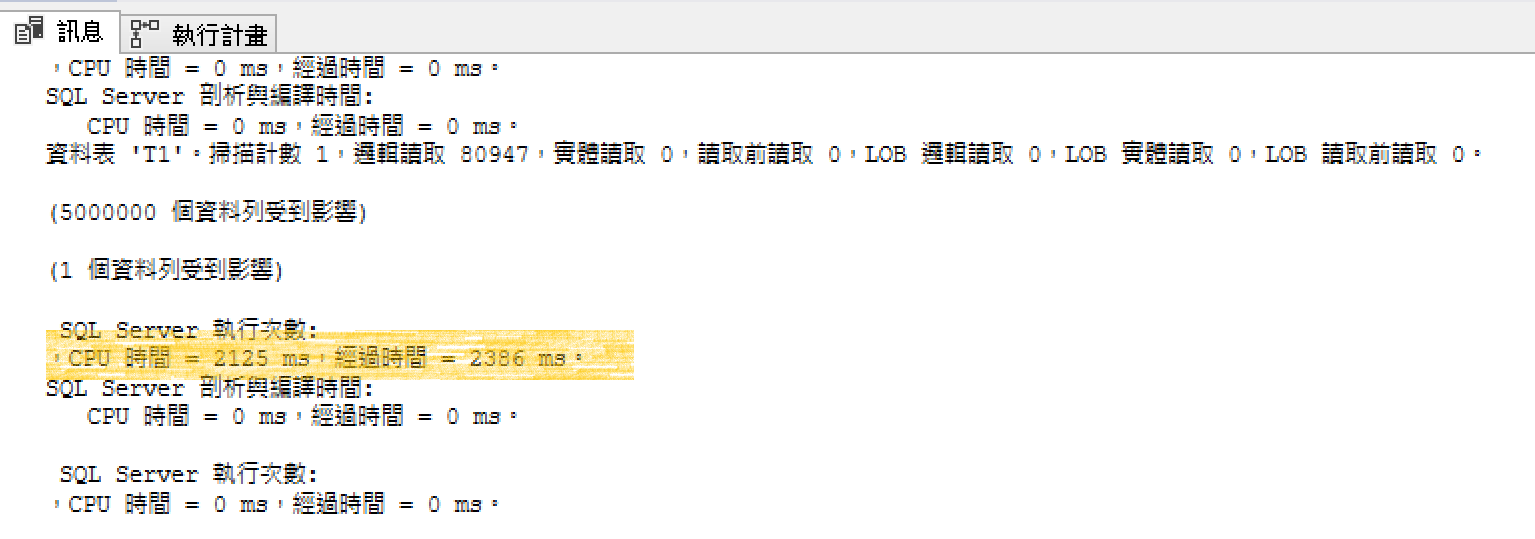
CPU TIME 2125ms,經過時間2386ms
執行計畫中資料表插入沒有平行符號
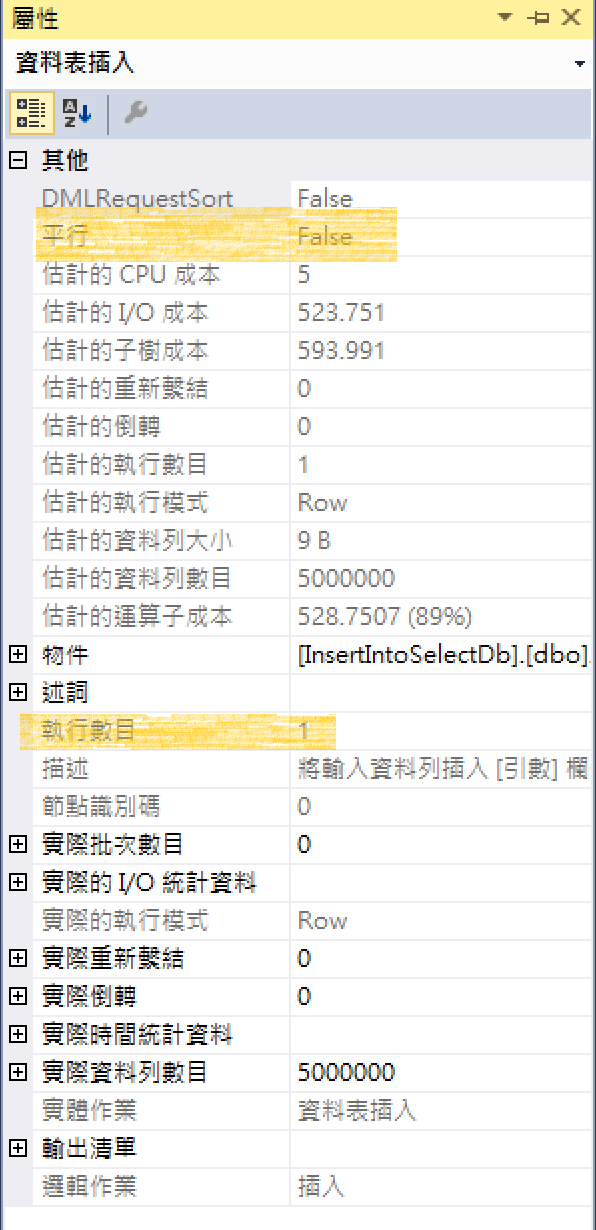
未啟用平行
2.實驗組測試(啟用平行)
設定相容性層級到130(SQL Server 2016)
ALTER DATABASE [InsertIntoSelectDb] SET COMPATIBILITY_LEVEL = 130;
GO
執行Insert Into測試,要加上WITH (TABLOCK) 才會啟用平行
USE InsertIntoSelectDb
SET STATISTICS IO ON
SET STATISTICS TIME ON
CREATE TABLE T1_2
(
ID INT ,
C2 CHAR(100),
C3 uniqueidentifier,
)
INSERT INTO T1_2 WITH (TABLOCK) SELECT * FROM T1
CPU TIME 4560ms,經過時間1315ms
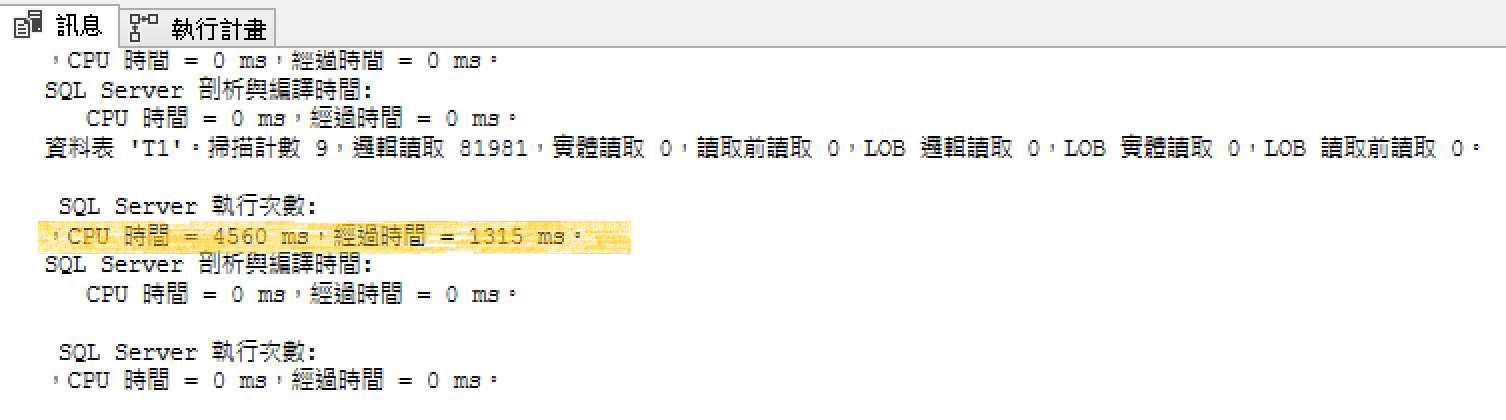
執行計畫: 資料表插入走平行了,連T1叢集掃描也平行了,平行處理原則是8
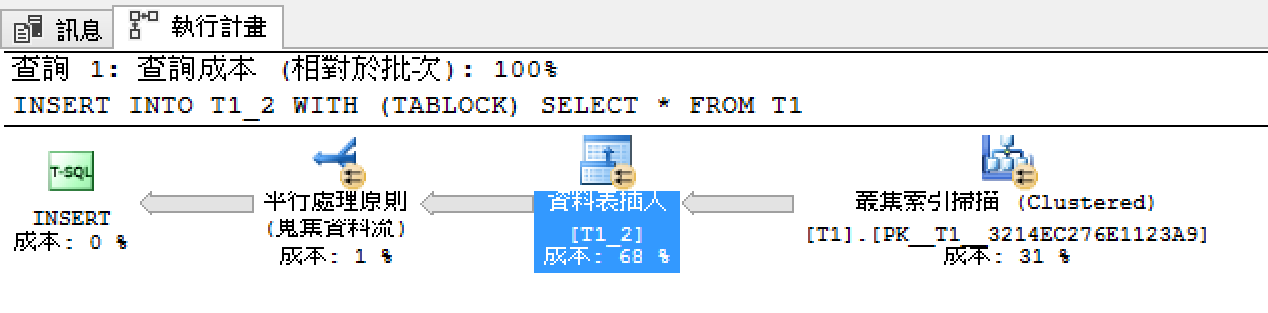
啟用平行
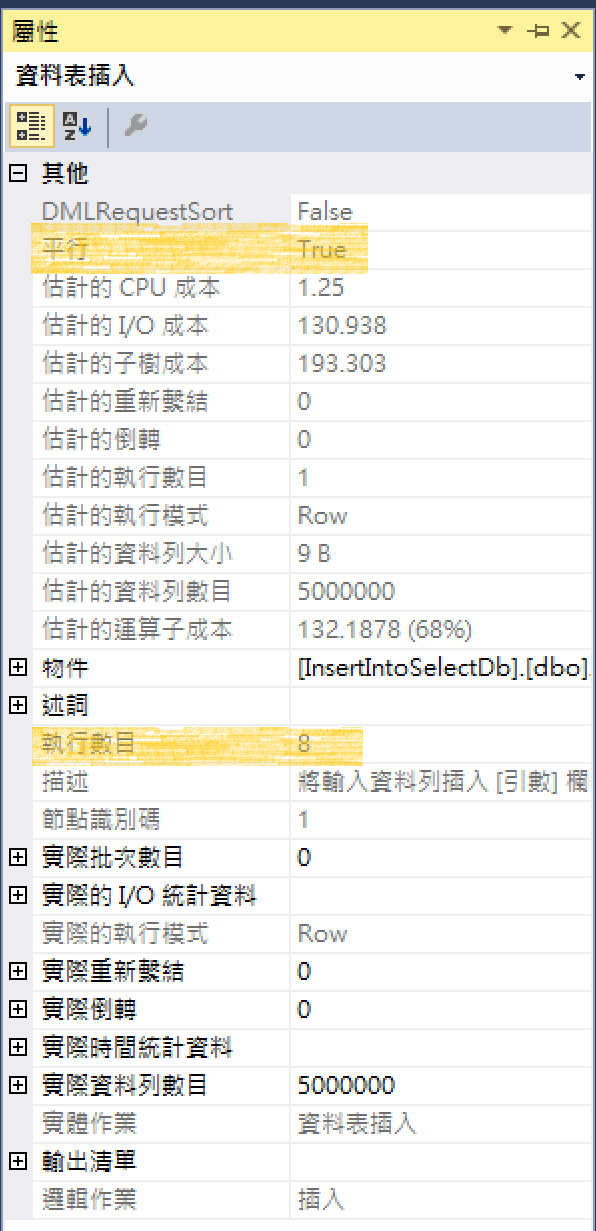
小結
| 相容性層級 | CPU TIME | 經過時間 | 估計子樹成本 |
| 110 | 2125ms | 2386ms | 593 |
| 130 | 4560ms | 1315ms | 194 |
- 啟用平行後,執行時間快了一些,CPU 時間也增加了。ms blog的在速度上差距到3x。
- 除了相容性層級130(SQL2016)以上外,還要加上Table Hint WITH (TABLOCK)
- 相容性層級升級後,也有副作用,尤其是基數預估演算法(Cardinality Estimator)的改變,要測試先。
參考:
Graphical Execution Plan Icons (SQL Server Management Studio)
ALTER DATABASE (TRANSACT-SQL) 相容性層級