最近的案子中,在測試及正式環境都碰到了幾次資料庫交易死結(DeadLock)而有交易被犧牲,有一次還碰上了查詢交易的死結(內部平行查詢死結intra-Query Parallel Deadlock),由於SQL Server發生死結(DeadLock)的原因很多,因為經驗不足,自己沒碰過的碰過的多,踏出解問題的第一步就是紀錄死結資訊。
來筆記幾種觀察死結問題的工具。
- Trace flag(1222,1204)
- SQL Profiler
- Extended events
最近的案子中,在測試及正式環境都碰到了幾次資料庫交易死結(DeadLock)而有交易被犧牲,有一次還碰上了查詢交易的死結(內部平行查詢死結intra-Query Parallel Deadlock),由於SQL Server發生死結(DeadLock)的原因很多,因為經驗不足,自己沒碰過的碰過的多,踏出解問題的第一步就是紀錄死結資訊。
來筆記幾種觀察死結問題的工具。
延續SQL Server儲存Unicode補充字集的話題,因為同事的目標資料庫是既有資料庫,沒辦法採用新建立資料庫的方式,後來同事直接把資料庫改成支援補充字集的定序(*_SC),一開始很順利,但使用到tempdb,像是join #table 或是union all #table時發現了定序衝突(collation conflict)問題。
來筆記另外兩種解決定序衝突(collation conflict)的作法:
中文博大精深,剛好負責的資訊系統會儲存客戶的中文姓名和地址,而中文姓名關係著八字五行、三才五格還有市場熱門度,取一個很命中缺什麼補什麼的名字是命理老師的專業,所以系統中時常會出現許多特別的古文字或是自創字也是相當合理自然的一件事。
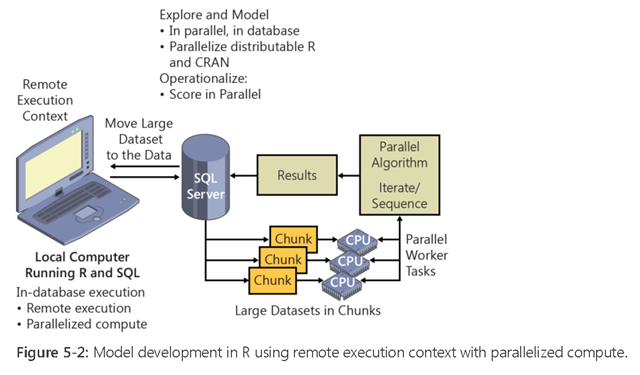
當我們在執行大量資料分析時,資料科學用戶端的本機記憶體及CPU運算能力可能會不足,另外如果也希望資料庫的資料不要走出家門太久,這時候就可以考慮在遠端的SQL Server上執行分佈運算Distributed Computing。
最近客戶要節省資料庫空間,除了資料封存(archive),想到了SQL Server Enterprise版本限定的功能”資料壓縮”。
隱約記得老師說要參考相異值數目來預估Bucket Count,來筆記Determining the Correct Bucket Count for Hash Indexes。
資料匯入資料庫準備驗證總數時發現有小數位,於是想要抓出有鬼的資料出列,解題答案可能有很多種,腦海中想到這個數學函數!
因為工作的需要(MPN條件,客戶標案要求),每年年底都有著上課進修和考試準備,上個月的27號收到了兩封微軟mswwprog的祝賀信,但自己最近沒參加考試啊!哈!究竟是怎麼一回事?
除了已經在SQL Server資料庫內的資料,有時候也會有其他來源收集的整批資料,這時候就可以在R用戶端呼叫RevoScaleR函數直接在SQL Server內建立資料物件並且匯入資料。
為了能在用戶端使用RevoScaleR(增強型R套件),這時候安裝Microsoft R Server或是Microsoft R Client就可以像和In-Database R中繼續使用RevoScaleR套件開發R。
凡間修練了好幾個百年,此時雲上的位置喬好了,該是時候回到天庭!接下來筆記第三篇,SQL資料庫透過SSMS佈署上Azure當神去!
上一篇完成了地面資料庫及網站準備,這一篇筆記Azure服務設定的步驟,預約Cloud上的位置。
這兩天協助客戶處理累積交易餘額的資料修補,因為要使用到累積總計(Running Totals),但客戶還在使用SQL Server 2008 R2,筆記SQL Server 2012前後兩個版本的作法。
上一篇將訓練後的線性迴歸模型儲存在SQL 資料表內,這一篇筆記在SQL Server 2016使用模型作出預測。
當SQL Server 完成機器學習後,如果能把訓練後的模型直接儲存在SQL資料表,新的交易數據馬上能就近在資料庫內參照模型作預測。這篇先紀錄將訓練後的模型儲存在SQL Server 2016資料庫內,下一篇再筆記使用模型對新數據作出預測。
就在光輝的10月又要開始銀行駐點的人生,每個禮拜只有一天能回公司LAB測試SQL Server 2014/2016功能,除了Azure DataBase方式外,打算把原本筆電安裝的2014Express升級為2014Developer版本。
有時後資料庫會出現門當戶不對的狀況,這時候不用重新投胎(Restore DB),只要幾秒鐘就門當戶對了。
資料庫內的資料表數目快速攀升,想要檢視某個資料表內容或是因為工作分組經常要使用特定名稱開頭或特定schema的資料表,都得要用滑鼠滾輪穿過很許多路人甲乙丙丁下才能遇到真愛;如果資料表數目有幾百個就需許多人生歷練,這禮拜看其他部門同事操作SSMS管理工具,快來筆記好用的filter setting。
SQL Server安裝在Windows OS中,而存放Data的磁碟幾乎都格式化為NTFS檔案系統,預設磁碟分割大小則是4KB。
從Super SQL Server社群楊老師的文章得到收穫和啟發,NTFS檔案系統預設的4KB可能不是SQL Server Data/Log Page的存取最佳值,來試試看其他Allocation Unit Size對效能的幫助。
客戶已經用上了壓縮備份(Compress Backup)再加分檔備份(Multi Backup Files)來提升備份作業速度,本以為除了換上SSD、切多條LUNs等這些可遇不可求的方法之外,只能回到資料庫的儲存資料作封存下手!
最近檢查備份語法時找到一招可以讓資料庫備份再快!