隱約記得老師說要參考相異值數目來預估Bucket Count,來筆記Determining the Correct Bucket Count for Hash Indexes。
In-Memory OLTP
SQL Server 2014新功能,也是Enterprise Edition限定版,可以提升 OLTP 資料庫應用程式效能。 減少交易處理的延遲,並且有助於改善暫時性資料案例 的效能。
建立資料庫
CREATE DATABASE [imoltp]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'imoltp', FILENAME = N'C:\SQL\imoltp.mdf' ,
SIZE = 102400KB , FILEGROWTH = 1024KB )
LOG ON
( NAME = N'imoltp_log', FILENAME = N'C:\SQL\imoltp_log.ldf' ,
SIZE = 20480KB , FILEGROWTH = 10%)
GO
建立最佳化的 FILEGROUP
ALTER DATABASE imoltp ADD FILEGROUP imoltp_mod CONTAINS
MEMORY_OPTIMIZED_DATA
ALTER DATABASE imoltp ADD FILE (name='imoltp_mod1',
filename='c:\SQL\imoltp_mod1') TO FILEGROUP imoltp_mod
建立記憶體最佳化資料表
分別新增Disk Base 及In-Memory Table(schema_only)
USE IMOLTP
CREATE TABLE dbo.AcctBookDisk
(
bu varchar(3) COLLATE Latin1_General_100_BIN2 not null,
acctnbr varchar(8) COLLATE Latin1_General_100_BIN2 not null,
createdate datetime not null,
name nvarchar(50)
COLLATE Chinese_Taiwan_Stroke_BIN2 not null,
balance numeric(13,2) not null,
CONSTRAINT PK_AcctBookDisk PRIMARY KEY NONCLUSTERED (acctnbr,bu)
)
CREATE TABLE dbo.AcctBookIm
(
bu varchar(3) COLLATE Latin1_General_100_BIN2 not null,
acctnbr varchar(8) COLLATE Latin1_General_100_BIN2 not null,
createdate datetime not null,
name nvarchar(50)
COLLATE Chinese_Taiwan_Stroke_BIN2 not null,
balance numeric(13,2) not null,
CONSTRAINT PK_AcctBook PRIMARY KEY NONCLUSTERED HASH(acctnbr,bu)
WITH (BUCKET_COUNT=1024)
)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY);
--記憶體最佳化資料表中的 (var)char 資料行必須使用字碼頁 1252 定序。
--select * from sys.fn_helpcollations()
-- where collationproperty(name, 'codepage') = 1252;
--(n)(var)char 資料行上的索引只能使用 BIN2 定序來指定 (請參閱第一個範例)。
--下列查詢會擷取所有支援的 BIN2 定序:
--select * from sys.fn_helpcollations() where name like '%BIN2'
SET NOCOUNT ON
PRINT '---Disk Base'
PRINT CONVERT(TIME,GETDATE())
DECLARE @I INT = 0;
WHILE @I < 1000000
BEGIN
SET @I = @I + 1
INSERT INTO AcctBookDisk
VALUES
('001', CONVERT(VARCHAR(8), @I), '20161028', 'ImDeveloper', 100)
END
PRINT CONVERT(TIME,GETDATE())
PRINT '---In-Memory'
PRINT CONVERT(TIME,GETDATE())
SET @I = 0;
WHILE @I < 1000000
BEGIN
SET @I = @I + 1
INSERT INTO AcctBookIm
VALUES
('001', CONVERT(VARCHAR(8), @I), '20161028', 'ImDeveloper', 100)
END
PRINT CONVERT(TIME,GETDATE())
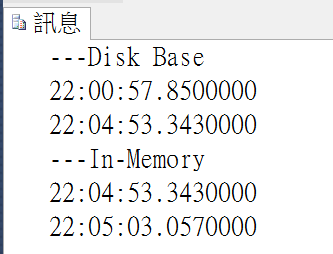
比較循序的效果:
| # | 循序寫入 |
|---|---|
| Disk Base | 236秒 |
| In-Memory Table | 10秒 |
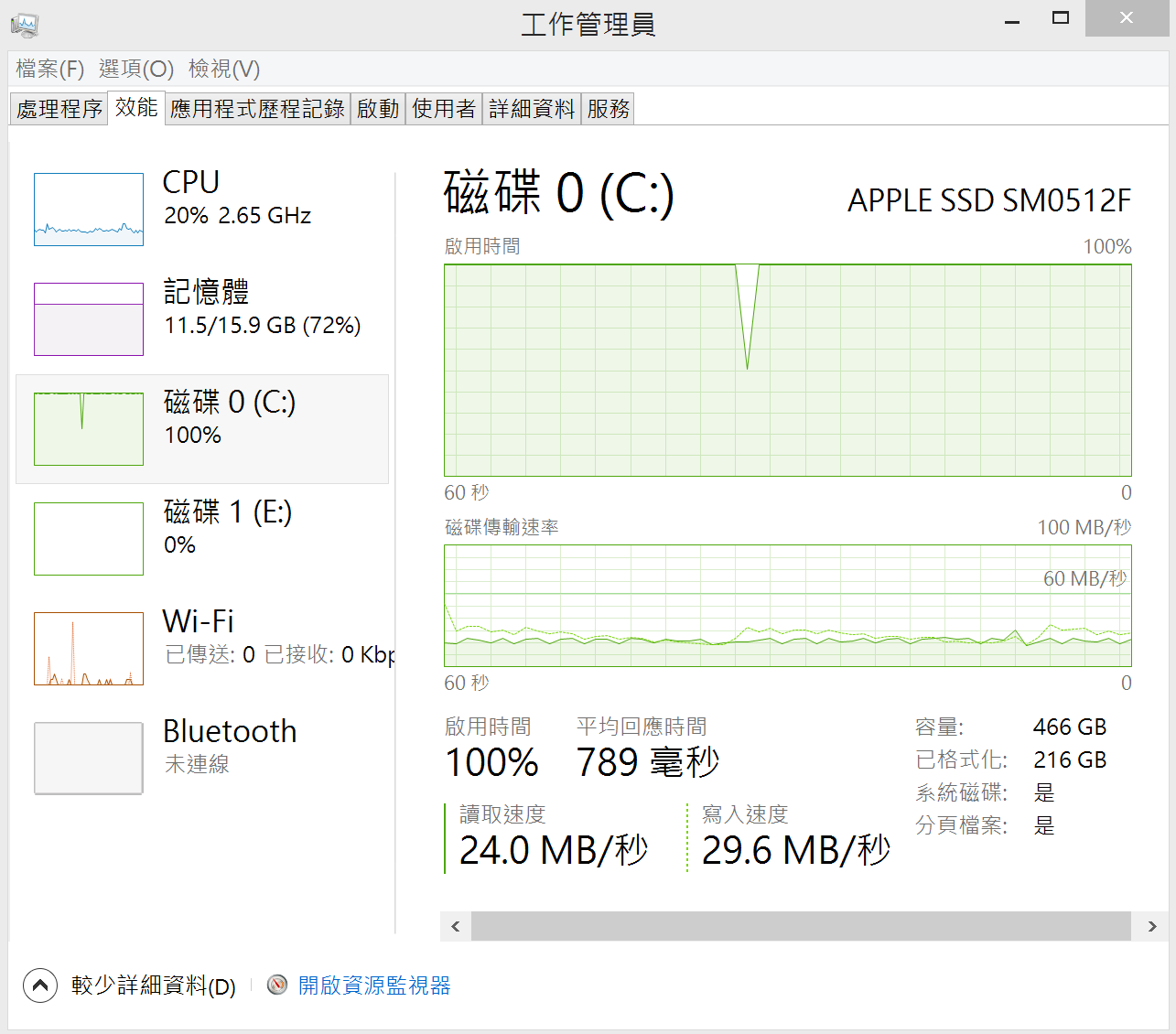
In-Memory完勝! 而且寫入Disk Base table時,MBP的硬碟效能滿載。
這個階段看起來Bucket count還沒有影響!
換個做法,改試試
PRINT '---Disk Base'
PRINT CONVERT(TIME,GETDATE())
INSERT INTO AcctBookDisk
SELECT
A.BU
,'D' + A.acctnbr
,A.createdate
,A.name
,A.balance
FROM AcctBookDisk A
PRINT CONVERT(TIME,GETDATE())
PRINT '---In-Memory'
PRINT CONVERT(TIME,GETDATE())
INSERT INTO AcctBookIm
SELECT
A.BU
,'I' + A.acctnbr
,A.createdate
,A.name
,A.balance
FROM AcctBookIm A
PRINT CONVERT(TIME,GETDATE())
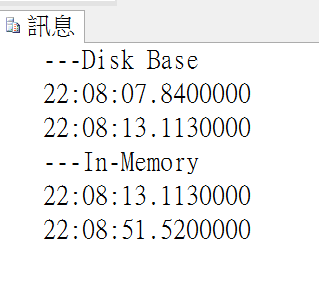
| # | 循序寫入 | 整批寫入 |
|---|---|---|
| Disk Base | 236秒 | 6秒 |
| In-Memory Table | 10秒 | 38秒 |
結果令人意外!是不是哪裡出狀況?
In-Memory變成龜兔賽跑的兔子!慢上許多個倍!
CREATE PROCEDURE usp_bulkinsert
WITH
EXECUTE AS OWNER,
NATIVE_COMPILATION,
SCHEMABINDING
AS
BEGIN ATOMIC
WITH
(TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'us_english')
INSERT INTO dbo.AcctBookIm
SELECT
A.BU
,N'A' + A.acctnbr
,A.createdate
,A.name
,A.balance
FROM dbo.AcctBookIm A
END
| # | 循序寫入 | 整批寫入 |
|---|---|---|
| Disk Base | 236秒 | 6秒 |
| In-Memory Table | 10秒 | 38秒 |
| In-Memory Table(Natively Compiled Stored Procedures) | 39秒 |
還是慢! 一整個鬼打牆!哈~ 這不科學!(氣!老婆要跺腳了!!!)
Bucket Count
重新檢視In-memory table 建立索引時有一個bucket count,我們用了1024,如果放大到相異值數目的200萬看看!
好!因為是客戶使用的版本是SQL Server 2014,還不能直接修改資料表結構,我們先移除預存程序、移除資料表最後才重建資料表!
DROP PROC usp_bulkinsert
DROP TABLE AcctBookIm
CREATE TABLE dbo.AcctBookIm
(
bu varchar(3) COLLATE Latin1_General_100_BIN2 not null,
acctnbr varchar(8) COLLATE Latin1_General_100_BIN2 not null,
createdate datetime not null,
name nvarchar(50)
COLLATE Chinese_Taiwan_Stroke_BIN2 not null,
balance numeric(13,2) not null,
CONSTRAINT PK_AcctBookIm PRIMARY KEY NONCLUSTERED HASH(acctnbr,bu)
WITH (BUCKET_COUNT=2000000)
)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY);
循序建立100萬筆資料
PRINT '---In-Memory'
PRINT CONVERT(TIME,GETDATE())
DECLARE @I INT = 0;
WHILE @I < 1000000
BEGIN
SET @I = @I + 1
INSERT INTO AcctBookIm
VALUES ('001', CONVERT(VARCHAR(8), @I),'20161028', 'ImDeveloper', 100)
END
PRINT CONVERT(TIME,GETDATE())
這邊執行後還是約10秒,快!
接著重新執行Bulk Insert
Good!科學了!超快!只要1秒!
科學是一門通過經驗實證的方法,對現象(原來指自然現象,現泛指包括社會現象等現象)進行歸因的學科。
| # | 循序寫入 | 整批寫入 |
|---|---|---|
| Disk Base | 236秒 | 6秒 |
| In-Memory Table(Bucket count = 1024) | 10秒 | 38秒 |
|
IIn-Memory Table (Bucket count = 2000000) |
10秒 | 1.3秒 |
真相大白!In-memory table 沉冤得雪!
MSDN建議:
在大部分情況下,值區計數應該介於索引鍵中相異值數目的 1 到 2 倍之間。 如果索引鍵包含許多重複的值,平均每個索引鍵值都有超過 10 個資料列,則改用非叢集索引
您不一定能夠預測某個特定索引鍵可能擁有或將會擁有多少個值。 如果 BUCKET_COUNT 值在索引鍵值實際數目的 5 倍以內,則效能應該是可以接受的。
計算最佳Bucket count語法
SELECT
POWER(2,CEILING( LOG(COUNT(0)) / LOG(2))) AS 'BUCKET_COUNT'
FROM
(SELECT DISTINCT bu,acctnbr
FROM AcctBookIm) T
透過Dmv查詢
SELECT * FROM sys.dm_db_xtp_hash_index_stats

SQL Server 2016除了改善了許多語法限制後,可以直接修改索引中的Bucket Count。(Alter table)
ALTER TABLE dbo.AcctBookIm
ALTER index PK_AcctBookIm rebuild
WITH (BUCKET_COUNT=3000000);
就在點還有In-Database R,一直努力說服客戶用2016,不過客戶也有希望等SP1、SP2後再升級的考量。
參考:
Requirements for Using Memory-Optimized Tables
Determining the Correct Bucket Count for Hash Indexes
Determine BUCKET_COUNT for Hash Indexes for SQL Server Memory Optimized Tables