排序條件在DB的分頁處理中扮演重要的角色,邏輯上,排序能確保每一次的分頁查詢,分頁資料的順序都有一致的預期;在效能上,也因為她的名字是排序,她有決定性的影響。來比較叢集索引、非叢集索引及非索引欄位來作分頁排序時的差異。
第二篇,排序欄位的選擇
- 取總筆數的效能(COUNT(1) OVER() VS CTE)
- 排序條件選擇
- 取資料序號(ROW_NUMBER() OVER(ORDER BY NOTHING))
- Offset Fetch Vs Row_number(總筆數及資料序號)
微軟DOCS
叢集索引將資料表或檢視中的資料列依其索引鍵值排序與儲存。
只有當資料表包含叢集索引時,資料表中的資料列才會以排序順序儲存。
當資料表有叢集索引時,資料表又稱為叢集資料表。 如果資料表沒有任何叢集索引,它的資料列就儲存在未排序的結構中,這個結構稱為堆積(heap)。
這次實驗我們還是用AdventureWorks2014資料庫中的PRODUCTION.TRANSACTIONHISTORY資料表作DB分頁測試,3次的執行,排序條件依序是:
- TransactionID(叢集索引)
- ProductID(非叢集索引)
- ModifiedDate(非索引欄位)
但先不抓取總筆數。
實驗
--叢集索引、非叢集索引及非索引欄位來排序
SET STATISTICS IO ON
SET STATISTICS TIME ON
DECLARE @PageSize INT = 10;
DECLARE @PageNumber INT = 10;
--叢集索引
SELECT *
FROM PRODUCTION.TRANSACTIONHISTORY
ORDER BY TransactionID
OFFSET (@PageNumber - 1) * (@PageSize) ROWS
FETCH NEXT @PageSize ROWS ONLY;
--非叢集索引
SELECT *
FROM PRODUCTION.TRANSACTIONHISTORY
ORDER BY ProductID
OFFSET (@PageNumber - 1) * (@PageSize) ROWS
FETCH NEXT @PageSize ROWS ONLY;
--非索引條件
SELECT *
FROM PRODUCTION.TRANSACTIONHISTORY
ORDER BY ModifiedDate
OFFSET (@PageNumber - 1) * (@PageSize) ROWS
FETCH NEXT @PageSize ROWS ONLY
先用數據比較,整理測試結果:
| 排序條件 | CPU Time | 經過時間 | 邏輯讀取 |
| 叢集索引欄位 | 0ms | 42ms | 3 |
| 非叢集索引欄位 | 0ms | 75ms | 317 |
| 非索引欄位 | 109ms | 145ms | 876 |
11萬筆資料的比較
執行計畫

查詢1的叢集索引掃描,資料已排序。

查詢2的索引鍵查閱(key lookup),資料已排序。
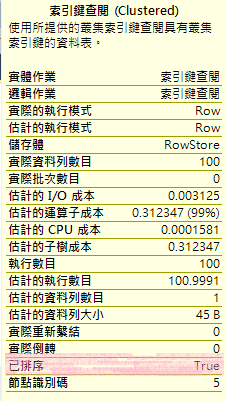
查詢3沒有,只好自己排。
比較成本表格:
| 排序條件 | 占比 | 子樹成本 |
| 叢集索引欄位 | 0% | 0.0039133 |
| 非叢集索引欄位 | 10% | 0.316297 |
| 非索引欄位 | 90% | 2.83824 |
比較成本圖示:

小結
- 資料表設計叢集索引很重要,除了排序的效能影響外,也是空間是否能重複使用的關鍵。
- 理想的叢集索引設計: 最短、不常變更、AP能更按照順序新增、唯一(選擇)。
- Cluster Index並不一定要和Primary key相同。
- 用非叢集索引作為排序條件時,索引鍵查閱(key lookup)將耗用較多的資源,可以再調整語法,先挑出key column再撈其他欄位。
- 排序條件無法識別唯一性時,會不會有非預期的順序?
參考
[SQL Server][Pagination]DB端的分頁處理(一)取總筆數的效能(COUNT(1) OVER() VS CTE)