最近其他部門同事在.NET處理大型主機(Mainframe)下傳的檔案發生長度錯誤,實際整個檔案長度正確,但卻有少數資料Parse時異常,
晚上女兒睡著了,趕緊抽時間筆記。
約定的檔案編碼是BIG5+ASCII,用Notepad或ultraedit開啟檔案,肉眼長度有shift掉1個byte,實際算檔案長度卻是正常的!
類似像下面第1筆和第4筆的位移:
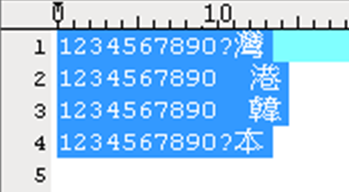
線索1:本來同事判斷是難字問題,但百萬筆只有30筆太神,這家銀行難字就4千多個字,不應該這麼少。
線索2:同事進一步提到,這幾筆資料的低位元組(中文字第二個Byte的內碼)放0E/0F/0D/0A,有古怪!
為了測試,我們試著自己做了4筆BIG5資料,中文字依序是台灣、香港、南韓及日本
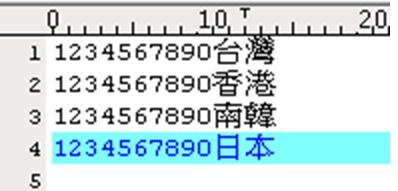
查看每一筆資料第一個中文字的內碼
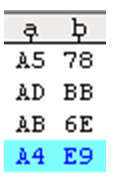
把第一筆台灣和最後一筆日本的低位元組放0E、0F,作為異常的實驗組。
把第二筆香港及第三筆南韓的高位元組放81及8E(BIG5造字區高位元組),低位元組則放40,作為對照組難字的測試。
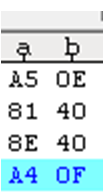
接著我們撰寫單元測試程式,依序操作StreamReader指定BIG5編碼讀Text,接著也用FileStream用bytes取資料:
[TestMethod]
public void TestMethod1()
{
//原始檔案
string fileName = @"c:\TEST\TestBIG5.TXT";
//檔案長度(Bytes) = 檔案長度(14) + 0x0D 0x0A(2)換行符號
int fileLength = 16;
int counter = 0;
string line;
Console.WriteLine("==== StreamReader text ====");
//text
using (StreamReader file = new StreamReader(fileName, Encoding.Default))
{
while ((line = file.ReadLine()) != null)
{
Console.WriteLine("{0} length:{1} data is {2}", counter + 1, Encoding.Default.GetBytes(line).Length, line);
counter++;
}
}
Console.WriteLine("");
Console.WriteLine("==== FileStream bytes ====");
counter = 0;
//bytes
using (FileStream stream = new FileStream(fileName, FileMode.Open))
{
byte[] buffer = new byte[fileLength];
int count;
while ((count = stream.Read(buffer, 0, buffer.Length)) > 0)
{
Console.Write("{0} length:{1} data is {2}", counter + 1, buffer.Length, Encoding.Default.GetString(buffer));
}
}
}
執行結果
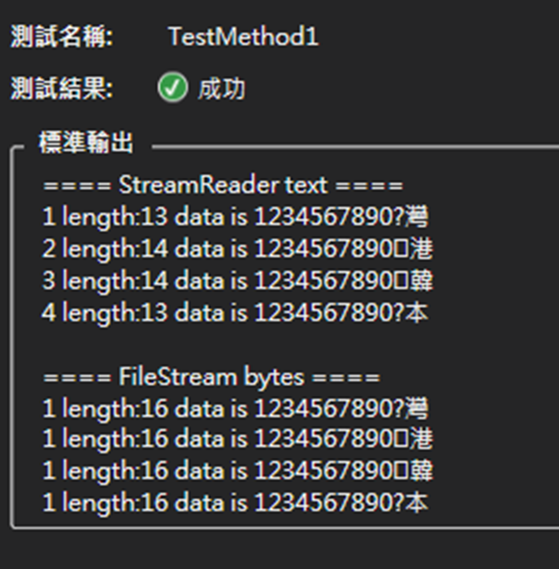
從結果可以發現:
- 無論StreamReader或是FileStream,難字都可以正確的轉出很像全型空白的圖示(我們的電腦沒有特別造字,因此看起來會像全型空白)
- 但台灣和日本的第一個中文字都是問號,而且StreamReader還發生了長度不一致的現象(13 vs 14),這點可以解釋同事程式遇到的長度問題。
這邊我們也得到兩個前進的方向:
- 應該不是難字問題,研判可能出現非預期的編碼,導致系統無法解析,shift掉一個byte。
- 直接用BIG5編碼取檔案text時,猜測因為有異常編碼,長度會發生錯誤,必須用bytes的方式取,才能取到正確長度。
BIG5是一套雙位元組字元集,不像主機EBCDIC或特殊編碼會在前後有控制位元(Shift-in/out),她有特定的範圍區來讓系統辨識:
- BIG5高位元組: 0x81-0xFE
- BIG5低位元組: 0x40-0x7E,及0xA1-0xFE。(這表示,內碼並不是連續的!!)
ASCII則是單位組字元集
- ASCII : 00到7F元區間。
兩者的第一個位元組並沒有重疊,當電腦系統處理到BIG5+ANSI的檔案時,就可以簡單用這樣的編碼規則來分辨。
下圖簡單說明ASCII + BIG5編碼範圍:
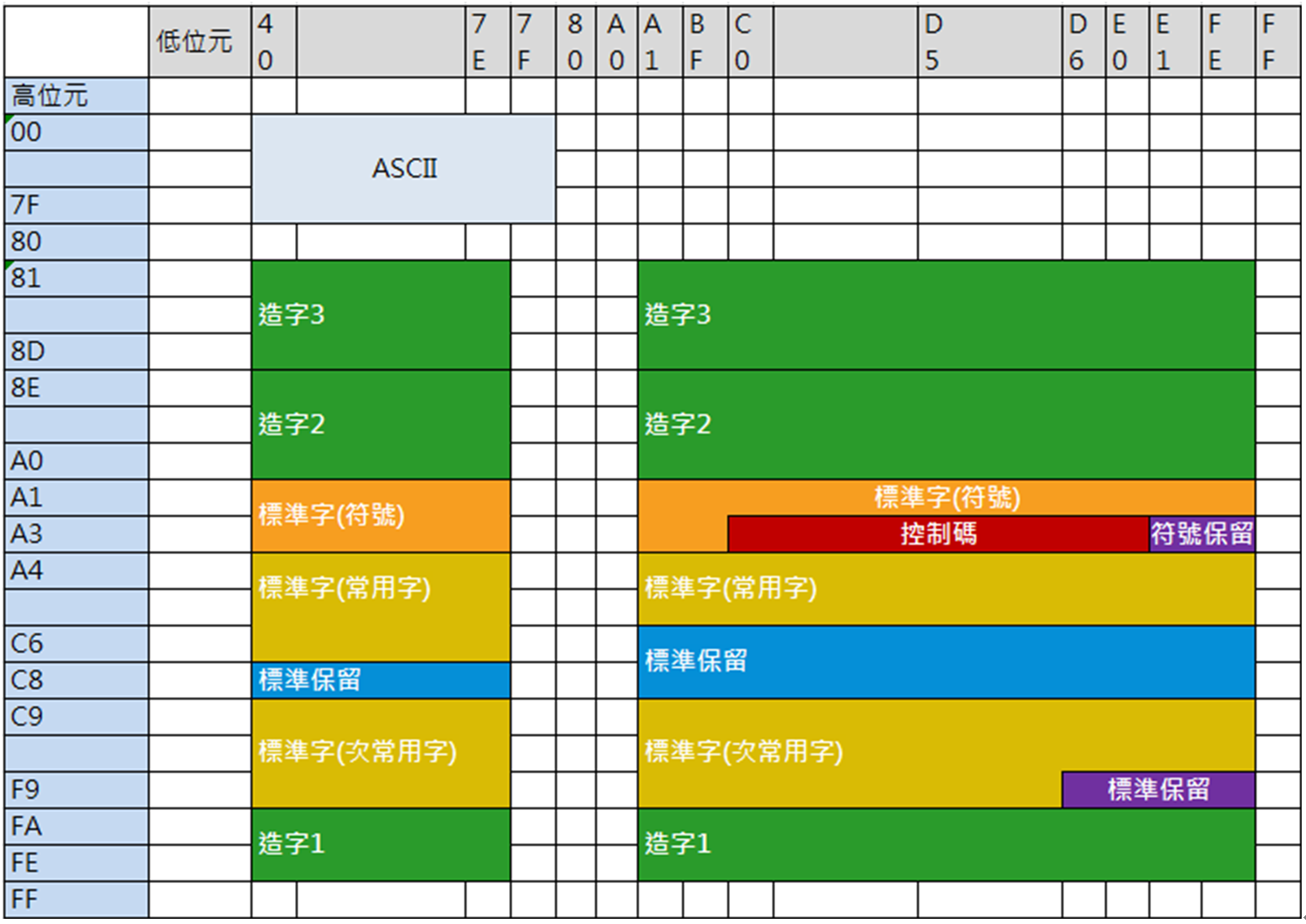
從上圖然後對應4筆測試資料可以發現:
這4筆資料高位元組都符合BIG5編碼系統(0x81-0xFE),電腦解析為中文編碼區,接著判斷低位元組區發現有2筆低位元組不符合編碼範圍!!!
| 1 | A50E |
| 2 | 8140 |
| 3 | 8E40 |
| 4 | A40F |
Bingo! 非預期的編碼果然造成了這次位移。
資料提供端是大型主機系統MainFrame,修正要比較久的時間,我們試著先寫一段程式把非預期的編碼修正為空白,然後重新產生檔案。
[TestMethod]
public void TestMethod2()
{
//原始檔案
string fileName = @"c:\TEST\TestBIG5.TXT";
//新檔名稱
string NewfileName = @"c:\TEST\TestBIG5_NEW.TXT";
//檔案長度(Bytes) = 檔案長度(14) + 0x0D 0x0A(2)換行符號
int fileLength = 16;
using (FileStream streamO = File.Open(NewfileName, FileMode.OpenOrCreate, FileAccess.Write))
{
//bytes
using (FileStream stream = new FileStream(fileName, FileMode.Open))
{
byte[] buffer = new byte[fileLength];
int count;
while ((count = stream.Read(buffer, 0, buffer.Length)) > 0)
{
for (int i = 0; i < count; i++)
{
if (buffer[i] == 0x0E || buffer[i] == 0x0F)
{
//設定中文欄位出現的offset位置區間
if (i >= 10 && i <= 14)
{
buffer[i] = 0x20;
buffer[i - 1] = 0x20;
}
}
}
streamO.Write(buffer, 0, buffer.Length);
}
}
}
}
修正後檔案長度也正確了!
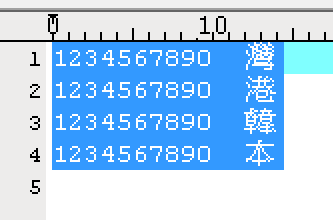
小結:
- 中華男籃換新血期間,球迷多包涵。
參考: