安裝完需要的R Package之後,接著使用sp_execute_external_script來從SQL Table取得資料。
1.準備SQL Table: 在Tempdb建立一個SQL Table資料表Eurofootballclub
use tempdb
create table Eurofootballclub
([country] varchar(20) NOT NULL,[population] int,[year] int,[FIFAScore] int)
2.寫入測試資料到Sql table
這裡我們偷懶使用上一篇R Script的結果集(R Script組成DataFrame輸出)
步驟是 (1)把上一篇R Script放入預存程序 (2)insert into from 預存程序結果集。
R Script結果集:
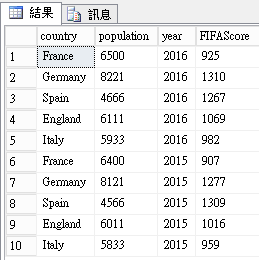
use tempdb;
go
--(1)建立預存程序
create proc usp_Eurofootballclub as
execute sp_execute_external_script
@language = N'R'
, @script = N'
country <- c("France","Germany","Spain","England","Italy","France","Germany","Spain","England","Italy");
year <- c(2016,2016,2016,2016,2016,2015,2015,2015,2015,2015);
population <- c(6500,8221,4666,6111,5933,6400,8121,4566,6011,5833);
FIFAScore <- c(925,1310,1267,1069,982,907,1277,1309,1016,959);
OutputDataSet <- data.frame(country,population,year,FIFAScore)'
, @input_data_1 = N''
WITH RESULT SETS (([country] varchar(20) NOT NULL,[population] int,[year] int,[FIFAScore] int));
go
--(2)透過預存程序結果集寫入資料
insert into Eurofootballclub
Execute usp_Eurofootballclub
執行完成後就把測試環境準備好了(R Script結果集寫入SQL Table)
3執行Select語法把Table資料載入InputDataSet
execute sp_execute_external_script
@language = N'R'
, @script = N'
OutputDataSet <- InputDataSet'
, @input_data_1 = N'select * from Eurofootballclub'
WITH RESULT SETS (([country] varchar(20) NOT NULL,[population] int,[year] int,[FIFAScore] int));
沒錯!在@input_data_1參數輸入T-SQL語法 ,R Script中就可以用InputDataSet變數取得資料(型別為DataFrame)。
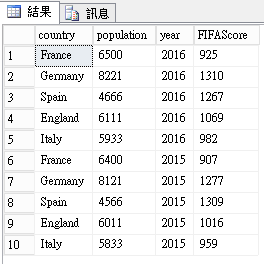
這裡先不對InputDataSet做處理,先輸出到OutputDataSet,執行後正確顯示10筆結果集資料。
4.使用plyr套件中的subset篩選Data Frame資料InputDataSet,然後寫出到OutputDataSet
篩選條件country = France
execute sp_execute_external_script
@language = N'R'
, @script = N'
library("plyr")
OutputDataSet <- subset(InputDataSet, country== "France")'
, @input_data_1 = N'select * from Eurofootballclub'
WITH RESULT SETS (([country] varchar(20) NOT NULL,[population] int,[year] int,[FIFAScore] int));
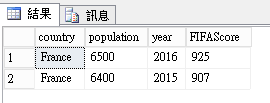
正確顯示法國近兩年的資料。
到這邊可以發現R和SQL Table更容易的整合在一起作統計作分析!
- 資料篩選及排序:T-SQL
- 統計、分類、分群、回歸演算:R Script
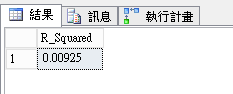
5.試試跑簡單的線性迴歸分析(linear regression),取出R-squared
execute sp_execute_external_script
@language = N'R'
, @script = N'
OutputDataSet <- data.frame(summary(lm(formula = FIFAScore ~ population,data = InputDataSet))$r.squared)'
, @input_data_1 = N'select * from Eurofootballclub'
, @parallel = 0
WITH RESULT SETS (([R_Squared] numeric(6,5) NOT NULL))
排除西班牙再跑1次
execute sp_execute_external_script
@language = N'R'
, @script = N'
d <- subset(InputDataSet, country!="Spain")
OutputDataSet <- data.frame(summary(lm(formula = FIFAScore ~ population,data = d))$r.squared)'
, @input_data_1 = N'select * from Eurofootballclub'
, @parallel = 0
WITH RESULT SETS (([R_Squared] numeric(6,5) NOT NULL))
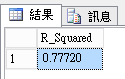
R-squared
相關係數R的平方,也稱為R2、解釋變異量(coefficient of determination)及迴歸模型的決定係數。
越接近1,表示人口波動(X)去預測FIFA分數(Y)的解釋能力很高;越接近0,解釋能力很低。
簡單的說,預測力。
小結:
- 以人口波動預測FIFA分數包含西班牙時,整體解釋能力很低只有0.00925
- 以人口波動預測FIFA分數不包含西班牙,整體解釋能力很高0.77720
參考:
https://cran.rstudio.com/web/packages/dplyr/vignettes/introduction.html