今日一新系統上線,30分鐘後AP同仁傳了系統錯誤訊息給我,如下圖所示。從字面上來看就是系統的資料庫發生了DeadLock。我先開始錄SQL的Trace來抓DeadLock事件,但似乎只有系統開始運作的前30分鐘有發生,後來就沒再發生DeadLock事件。於是乎我就透過預設的Extented Event來檢視之前DeadLock事件是那些資源互咬,並檢視當下時間所執行的語法。但我怎麼看當時執行的語法都覺得不至於產生DeadLock啊。

下圖指令先建立一測試資料庫mydb並建立一資料表tb1,tb1有3個欄位(sn,col1,col2)。sn欄位是PK及Clustered Index,而我們也針對col1欄位建立一非叢集索引[IX_tb1]。
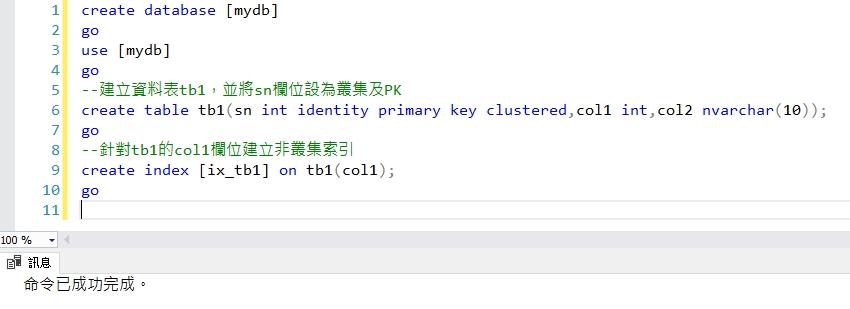
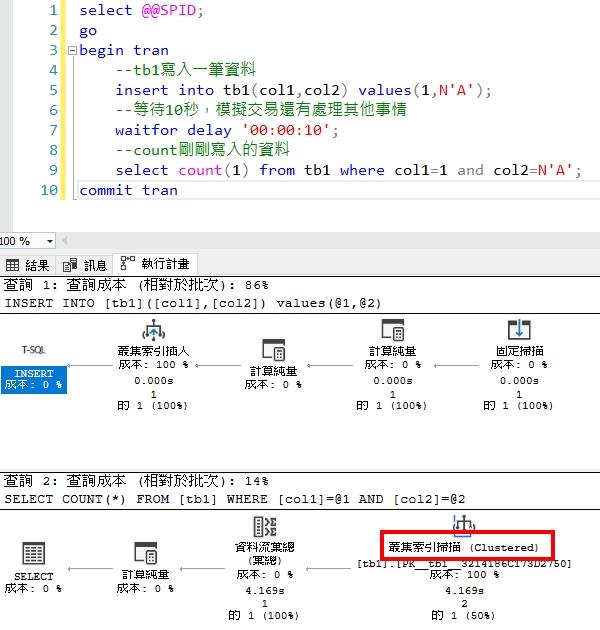
下面我們開始模擬發生DeadLock的語法,我們開啟一個Session(74)後開啟交易,先塞入一筆col1=1及col2='A'的資料進去tb1,然後停頓10秒來模擬該交易處理其他邏輯計算,最後再Select count剛剛塞入的資料,然後結束交易。
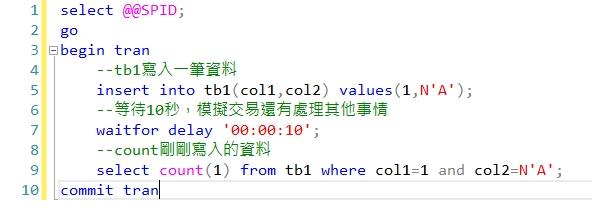
我們馬上(10秒內)再開啟另一個Session(67)後開啟交易,先塞入一筆col1=2及col2='B'的資料進去tb1,然後停頓10秒來模擬該交易處理其他邏輯計算,最後再Select count剛剛塞入的資料,然後結束交易。
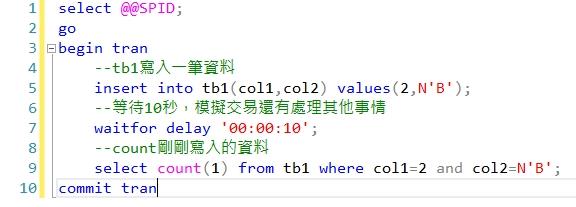
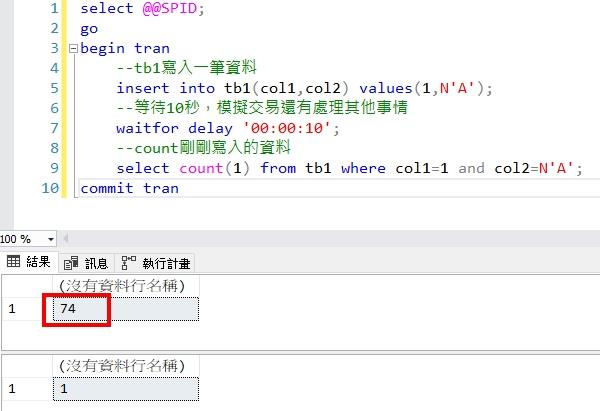
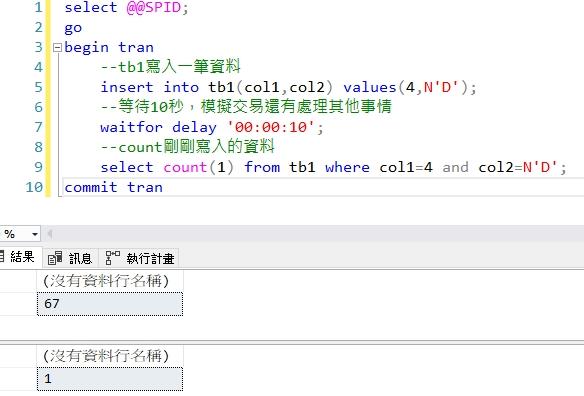
下圖中Session(74)順利完成交易,回傳Count筆數是1。
下圖中Session(67)則發生了DeadLLock事件而無法完成交易。
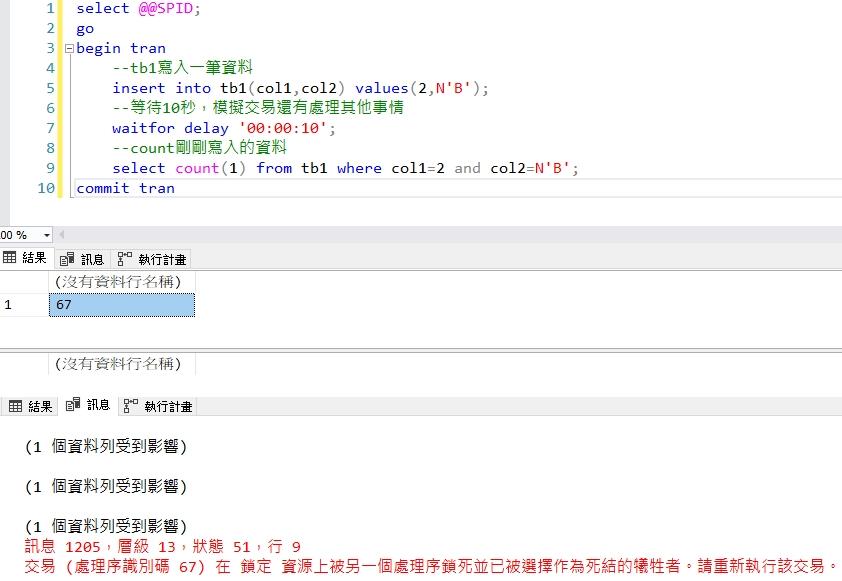
我們檢視一下Select Count的執行計畫後發現,雖然我們有針對col1建立了索引,但SQL仍然選擇用Table Scan的方式來抓取資料。反而不吃索引[IX_tb1]。
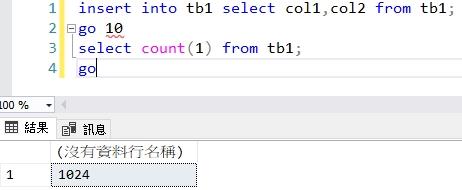
接下來我將該資料表寫入1024筆資料,再來做一次測試。
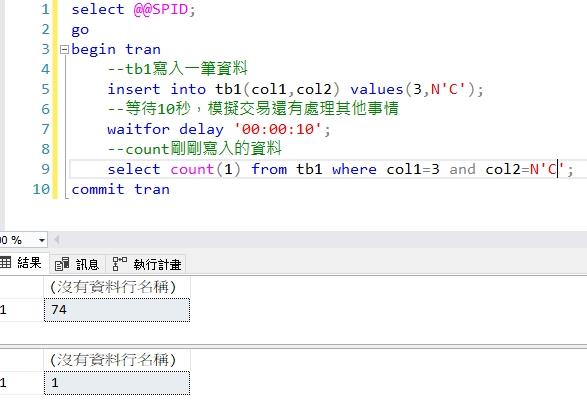
同樣語法在資料表已有1024筆的狀況下,Session(74)開啟交易,塞入一筆col1=3及col2='C'資料後停頓10秒再查詢。然後一樣馬上在Session(67)開啟交易,塞入一筆col1=4及col2='D'資料後停頓10秒再查詢。這次兩個交易都順利完成,沒有發生DeadLock,如下兩圖所示。
同樣的我們檢視一下Select Count時SQL的執行計畫為何。從下圖看,SQL已從Table Scan方式改成Index Seek + Key Lookup方式來計算筆數。
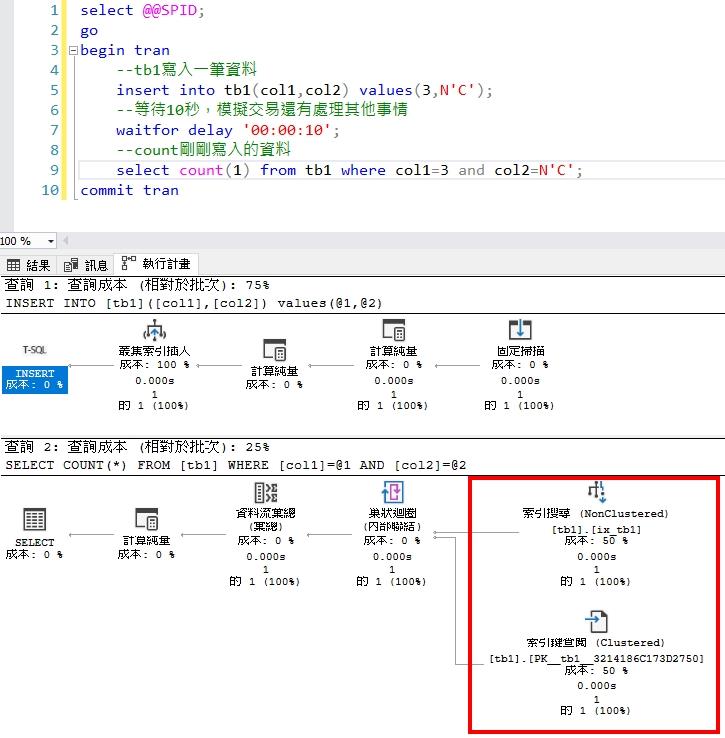
從上面簡易的模擬情境可以了解,一開始tb1資料量少因此在Select Count時,SQL認為Table Scan效能較佳,故採直接對叢集做Scan而不使用我們建立的[IX_tb1]這一個索引。因此導致大量Session同時在寫入tb1也在Scan tb1,此時就容易互咬而產生DeadLock。
但當tb1的資料量達到一定筆數後,SQL會認為Index Seek + Key Lookup的效能會優於Table Scan因而改使用[IX_tb1]這一個索引而避開Table Scan。此時就不會因為Table Scan的關係再發生DeadLock狀況。這也就是該系統為何在運作30分鐘後就沒有再發生DeadLock的原因。
我是ROCK
rockchang@mails.fju.edu.tw


