我在SQL效能調校課堂上有提到幾個常見查詢效能issues,
如不正確join type、謹慎使用MTVFs和低/高估記憶體大小,
現在SQL Server 2017可以更有效率自我修正這些效能問題。
QO進行優化期間,CE主要負責執行計畫中,每個運算子的資料列估計,
然後會透過假設評估產生各種執行計畫組合,最後,選擇一個足夠好(enough)的執行計畫,
當估計不準確則會導致效能不佳,如產生不良執行計畫、使用太多資源(CPU、IO、Memory)、
高估記憶體導致降低吞吐量和並行能力。
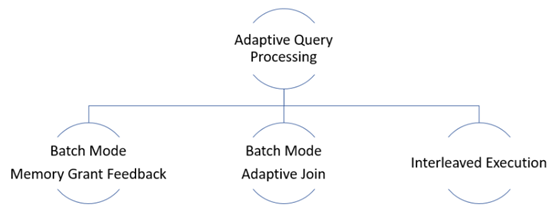
Adaptive query processing(自主查詢處理)可以修正幾種不合適的執行計畫情況,
例如某個operation估計資料列錯誤或記憶體估計值不正確…等。
我們可以設定資料庫層級>=140,讓SQL Server自主適應workload,
並發揮查詢最佳效能,目前有三種改善範本,下面我簡單測試驗證效果。
 From Microsoft
From Microsoft
Batch Mode Adaptive Joins
 From Microsoft
From Microsoft
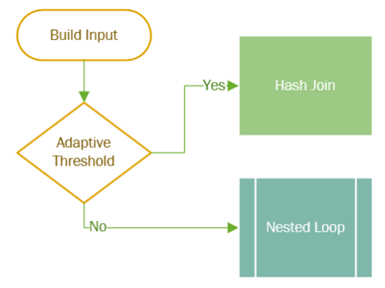
該範本會定義一個門檻值,當輸入>=門檻值就使用Hash join,
反之則使用nested loop join,執行過程中,每一個branch皆runtime切換至最合適運算子,
但目前只支援batch mode,我相信未來不久也會支援row mode。
alter database WideWorldImportersDW set compatibility_level=130
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 15
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 115
 層級<=130,QO會自行判斷input的資料量,並選擇應該使用那種join type,
層級<=130,QO會自行判斷input的資料量,並選擇應該使用那種join type,
這種方式對真實世界來說太過理想化,因為input資料量並沒有完整scan會影響join其他資料表效能,
雖然,我以前都是透過hint或改code方式來調校,但這方式也有美中不足的地方,
該條件下的資料量如果發生非預期變化,那麼這時效能兇手可能就是自己所造成,
最好的方式,應該還是由SQL Server完全自主調整,不應該由開發人員來monitor並隨時修復效能問題,
下面我將DB層級改為140,這時SQL Server將延後等到第一個input都完全scan後,
才會選擇要用hash or nested loop。
alter database WideWorldImportersDW set compatibility_level=140
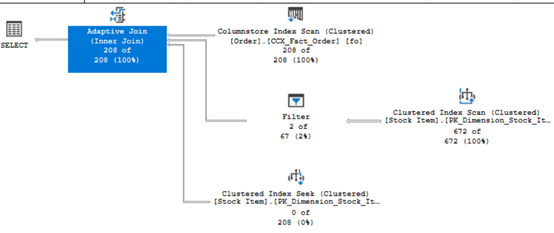
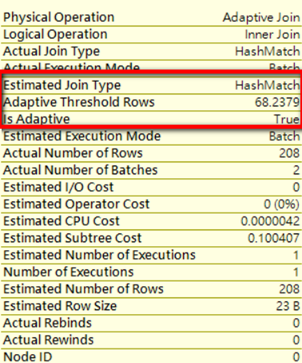
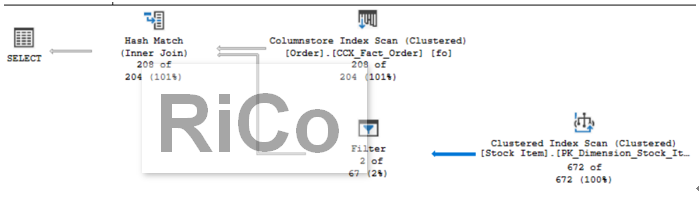
執行計畫中多了一個新的operation為adaptive join,也可以看到>=68.2379門檻值將使用hash join,
反之則使用nested loop join,使用nested loop join則使用已經讀取的資料列(from hash join build),
而不會重新讀取join input。
由上而下我們可以知道,兩個columnstore index scan會使用hash join input,
該join input都掃描完後再和clustered index seek使用nested loop join。
另外,我以前也有提過hash join所帶來的副作用(額外的記憶體資源..等),
而這些副作用當然也會發生,換句話說,這只能幫助我們減少效能調校時間,
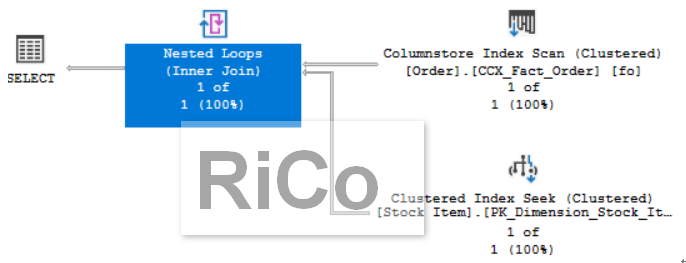
但無法完全避免效能調校,下面我改條件為115
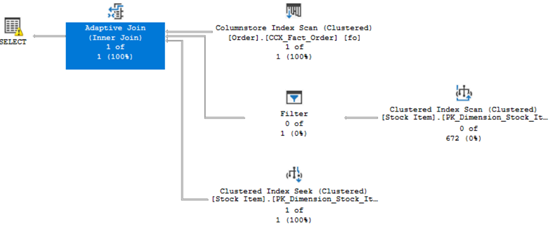
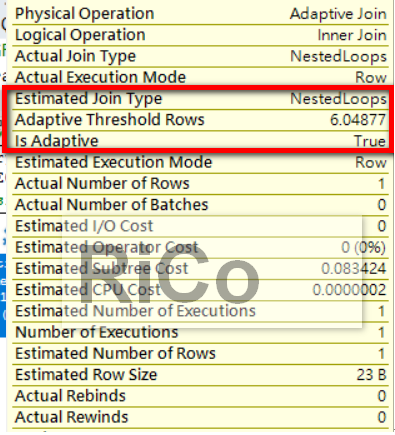
該條件下,我們可以更明確知道預估的join type為nested loops,也多了幾個新屬性
Is Adaptive:顯示是否為adaptive query processing
Adaptive threshold rows:門檻值
Actual join type:顯示最終的join類型
Estimated join type:預估的join 類型
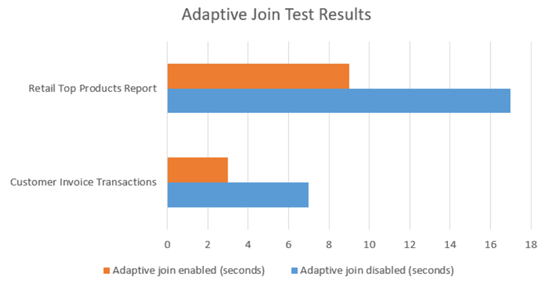 MS宣稱可改善wrong join type效能約20%。
MS宣稱可改善wrong join type效能約20%。
Batch Mode Adaptive Memory Grant Feedback
針對記憶體授權問題,我以前在SQL2016-新查詢提示 for Memory文中有說明過,
這裡就不在重複說明 (太多浪費記憶體,降低併發能力。太低則大量使用IO) 和示範,
這項功能需要連續重複執行相同statement(才能更新cache plan),
這樣SQL Server才能自我修正記憶體大小,所以如果有使用option(recompile)、plan低於1024 kb或計畫從cache被移除皆無法受益。
Note:如果記憶體授權大於實體記憶體2倍,則會反應並重新計算記憶體授權,
不足的情況,則會反應至spilling_report_to_memory_grant_feedback事件。
參數探測的計畫,如果記憶體需求不穩定,SQL Server將自動禁用該功能,
我們可以透過監控memory_grant_feedback_loop_disabled 事件,
另外,透過memory_grant_updated_by_feedback可以得知計畫被更新的次數。
Interleaved Execution for Multi-Statement Table Valued Functions
資料表值函數效能也是老問題,可參考我以前文章資料表值函數(2)。
SQL2014/2016固定統計值為100(更早之前的版本都為1),目前相關參考的statement都必須唯讀,
且不能為任何資料修改的一部分才能受益。一般來說,估計和實際資料列差距越大,
透過該範本改善效果就越明顯,另外,也不會有什麼額外資源開銷,
就算使用option(recompile)的statement也都可以受益(因為會產生新執行計畫),
可惜目前只針對MSTVF進行估計值修正,未來,我想這範圍應該可以擴大至所有相關估計演算,
現在可能存在風險就是執行計畫會有一些變更,
但我們可以透過Query Store或automatic tuning來快速修正問題(如果效能不佳)。
alter FUNCTION GetMovement(@stockkey int)
RETURNS @mytbl TABLE
([Transaction Type Key] int NULL,
[WWI Stock Item Transaction ID] int null,
[WWI Purchase Order ID] int NULL)
AS
BEGIN
INSERT @mytbl SELECT a.[Transaction Type Key],a.[WWI Stock Item Transaction ID],a.[WWI Purchase Order ID]
FROM fact.Movement a
where a.[Stock Item Key]=@stockkey
RETURN
END
select top 10000 a.* from fact.[Order] a
join dbo.GetMovement(140) b
on a.[Stock Item Key]=b.[Transaction Type Key]
join fact.Purchase c
on c.[Purchase Key]=a.[Stock Item Key]
Level=130
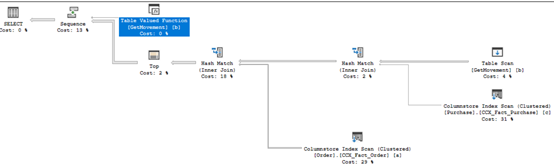
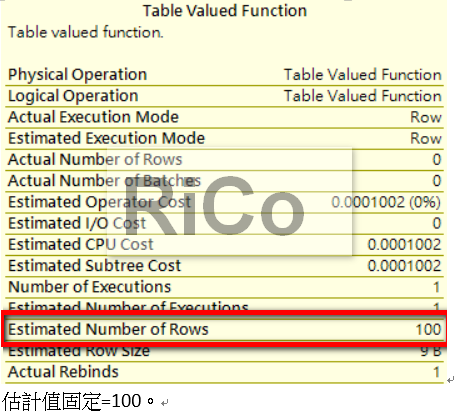
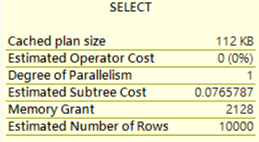
Level=140
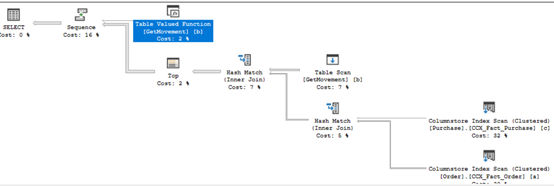
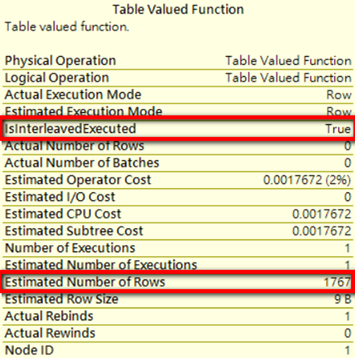
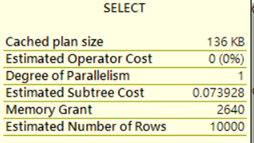 透過新屬性IsInterleavedExecuted,我們可以確定查詢是否套用Interleaved Execution,
透過新屬性IsInterleavedExecuted,我們可以確定查詢是否套用Interleaved Execution,
而且估計值也不在固定為100,且整體執行計畫成本也較之前版本低。
參考
Performance Center for SQL Server Database Engine and Azure SQL Database
Enhancing query performance with Adaptive Query Processing in SQL Server 2017
Adaptive Query Processing in SQL Server 2017
SQL Server 2017: Adaptive Query Processing
Query Processing Architecture Guide
Batch Mode Adaptive Memory Grant Feedback
Interleaved Execution for Multi-Statement Table Valued Functions