管理和理解Consumer offset我覺得是入門kafka的首要基礎,不然可能會遇到一些小問題,
如Consumer為什麼一直pull重複資料?Consumer如何從某個offset開始pull資料?
Consumer為什麼不pull資料?..等
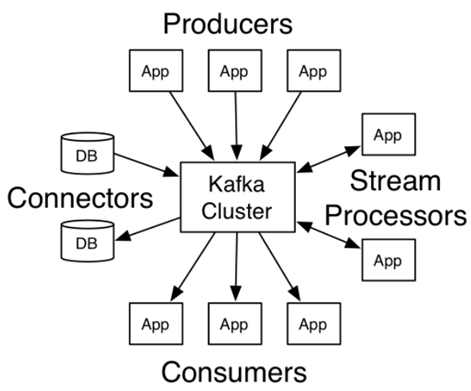
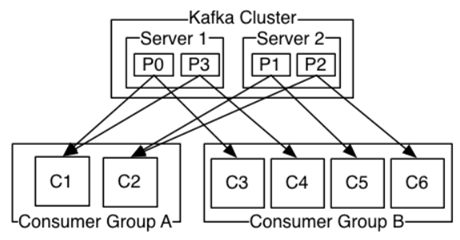
目前在kafka cluster架構下,我都一律使用consumer group,
consumer group是kafka所提供的一種容錯、自動平衡、擴充和平行處理的消費機制,
所有consumer加入都使用相同group id,實務上建議number of partition on topic=a multiple of broker,
因為這樣才能達到真正的balance。
管理consumer group中所有的member,kafka透過GroupCoordinator instance來處理,
其中Offset manager(每個broker都有自己的)管理所有offset,所以該information我覺得滿重要的,
相當然我的consumer ap都會帶出該資訊,方便我釐清狀態或debug。
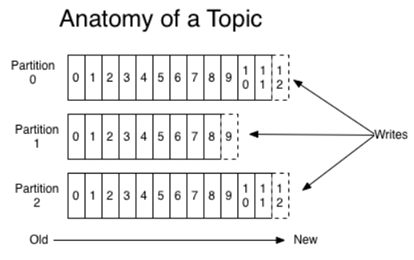
新版(>0.8.2)的kafka不在把offset存在zookeeper,因為zookeeper沒辦法承受大量的讀寫(尤其寫)request,
為了解決這問題,kafka自行建立內部topic(__consumer_offsets)來存放consumer group的offset,
你可以透過下列公式來算出groupcoordinator(那個partition)
consumers_offsets partition# = Math.abs(groupId.hashCode() % groupMetadataTopicPartitionCount)
P.S: groupMetadataTopicPartitionCount=50(default)
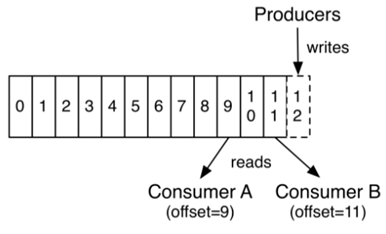
Kafka選擇讓每個consumer group管理自己的offset,這樣做可以避開broker變成狀態性(影響擴充彈性)、
握手機制來確認消費成功與否,最重要可以省下複雜的資料結構和資源消耗成本,
所以當初在設定consumer.config,我當然開啟enable.auto.commit = true和auto.commit.interval.ms=5000(類似checkpoint),
且kafka會定期保存每個consumer group的offset。
新版的kafka保證以下三件事
- producer發送message至相同topic,將保證message順序。
- consumer將依照partition上的message順序,依序讀取。
- topic上設定replicate N,保證最多允許N-1 server crash且不丟失任何資料(offsets.commit.required.acks=-1)。
知道三大保證後,在來看看Offset 如何commit?
當producer送一條message(序列化成byte[])至broker後,這時broker會讓partition中的leader來處理,
並且確認最少follower都sync完成,這時會通知offset manager紀錄該message的offset,因為設定ack=-1,
所以broker也會確保replicated 的數量已經追上leader,來保證容錯性和無資料遺失。
啟動Consumer訂閱該topic,就會隨機對一個broker發出offsetfetch請求,
由於請求中會包含多個partition的offset訊息,所以接收請求得broker會通知其他broker,
讓該partition的leader來(從broker的leader cache)response對應的offset。
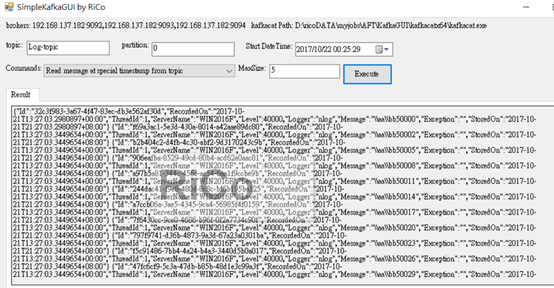
之前我透過 bin/kafka-console-consumer.sh 來ReConsumer,由於這功能我覺得滿實用,
所以我打算包裝kafkacat這強悍的KafkaCLI,並自己簡單寫一個GUI小工具,方便debug或救火使用。
1. Query Metadata
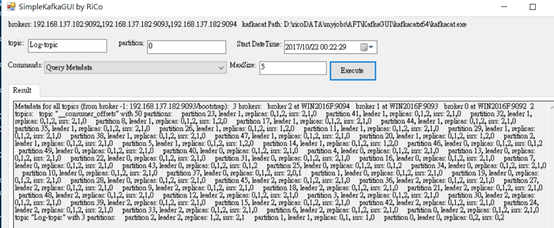
2.Query offset(s) by timestamp(s)
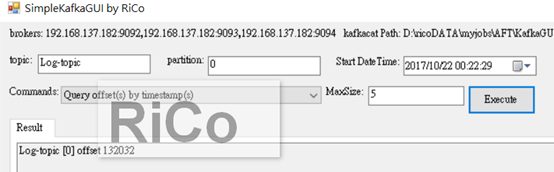
3.Read the last N messages from topic
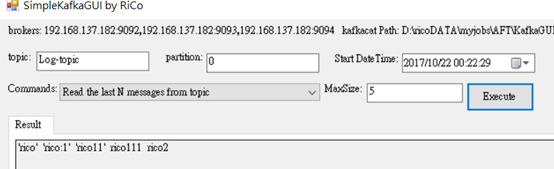
4.Read message at special timestamp from topic
參考
Kafka Consumer Offset Management
[Kafka] consumer offset checker