Hash index只能建立在In-memory table,並且提供point更快速的搜尋效能,
SQL2016開始可透過rebuild index方式修改bucket_count,無須drop and create。
查詢使用須知
- 避免Rang query,適用point query
- 避免order by 操作,因為hash在記憶體中都不會排序
- 所有的hash key都必須要存在where 子句中
Note:每個bucket使用 8 bytes
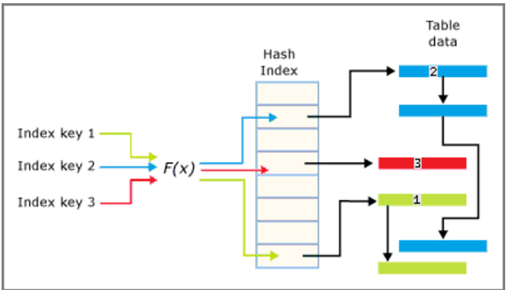
當建立hash index,SQL Server會透過hash function把指定的hash key進行hash,
這過程中有可能會發生hash collision,所以我們應該要盡量使用唯一性高的key(無法完全避免),
來減少發生hash collision頻率和bucked link list長度。
 From Microsoft
From Microsoft
假設我建立一個hash index並有 4 個bucket,下面我大概簡單說明這過程
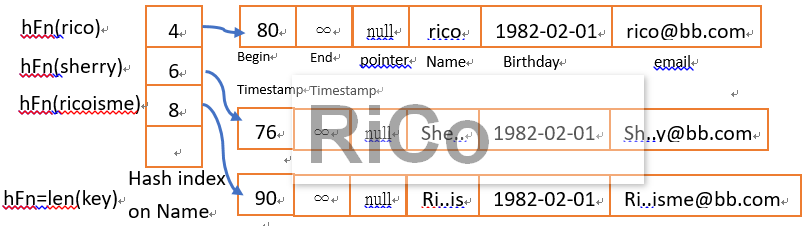
如果這時候我在新增一筆FIFI的資料,
那麼透過hash function就會被分配到bucket=4的address,這時候就會發生hash collision,如下圖
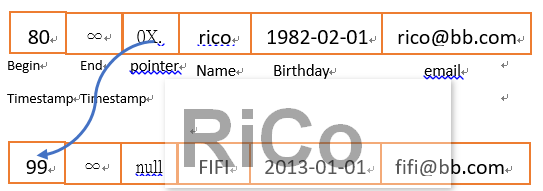
你可以看到,就算該index key唯一性高,但還是會有機率發生hash collision並造成長的bucked link list,
這主要對我們的query of point和batch insert效能影響很大。
Bucked count建議大小=唯一索引鍵值1.5~2倍,因為太大浪費記憶體,太小影響效能,
而SQL Server在建立bucket count是以2的次方來處理,下面我簡單驗證這數字不是我自己唬爛的。
while @maxloop <= 50
begin
-- build dynamic string with table name and bucket count having loop counter
set @mysql = N'
CREATE TABLE buckedcounttest'+ CONVERT(varchar(10), @maxloop)+'
(
ID INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = '+CONVERT(varchar(10), @maxloop) +'), --each bucket_count
EName VARCHAR(20) NOT NULL,
CName VARCHAR(20) NOT NULL
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)'
Exec (@mysql)
set @maxloop = @maxloop+1
end
note:schema_and_data:must have a PK, schema_only:must have at least on index or a PK。
Select object_name( [object_id]) AS 'Table Name',
bucket_count AS 'Number of Buckets'
from sys.hash_indexes
WHERE object_name( [object_id]) LIKE N'buckedcounttest%'
order by bucket_count, [object_id] asc
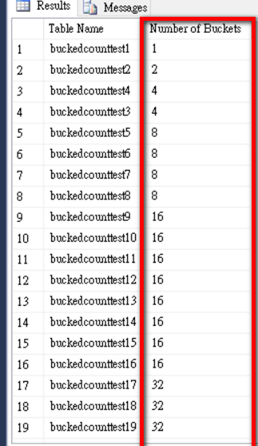
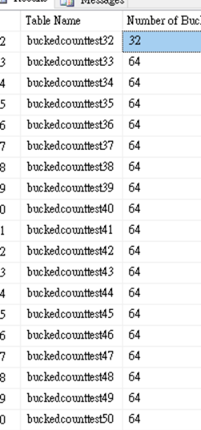 你可以看到我雖然最大指定50,但SQL Server所建立的bucket_count有效值卻是64,
你可以看到我雖然最大指定50,但SQL Server所建立的bucket_count有效值卻是64,
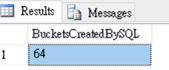
我們可以透過下面script來驗算這數字
DECLARE @BucketNumber int = 50 ;
DECLARE @BucketsCreatedBySQL int = 0;
-- Check of @BucketNumber is power of 2. if yes, that's the bucket number
IF (LOG(@BucketNumber,2) = ROUND(LOG(@BucketNumber,2),0))
SET @BucketsCreatedBySQL = @BucketNumber;
ELSE
-- If not power of 2, round off to next power of 2
SET @BucketsCreatedBySQL = POWER( 2, floor(LOG(@BucketNumber,2))+1);
SELECT @BucketsCreatedBySQL [BucketsCreatedBySQL]
--query hash index statistics
SELECT Object_name(his.object_id) AS 'Table Name',
idx.name AS 'Index Name',
total_bucket_count AS 'total buckets',
empty_bucket_count AS 'empty buckets',
total_bucket_count - empty_bucket_count AS 'used buckets',
avg_chain_length AS 'avg chain length',
max_chain_length AS 'max chain length',
90000 AS 'Rows - hardcoded value'
FROM sys.dm_db_xtp_hash_index_stats as his
JOIN sys.indexes as idx
ON his.object_id = idx.object_id
AND his.index_id = idx.index_id;
參考
Hash Indexes for Memory-Optimized Tables
sys.dm_db_xtp_hash_index_stats (Transact-SQL)