IN-Memory OLTP的Range Index使用類似B-tree的BW-tree結構,
透過BW-tree有效改善Range和point搜尋效率,並節省更多記憶體開銷,
尤其更適合DATE, DATETIME and DATETIME2。
我以前寫過一篇Bw(Buzz Word)- Tree 筆記,這篇我補充以前忽略的細節和觀念
Bw-Tree 優點
1.針對範圍(range)和指標(point)搜尋有很高效率
2.自我平衡
3.每張 page 透過邏輯指標互相串起來
4.依照Key有順序存取
5.更有效率使用多CPU
BW-tree結構大致如下
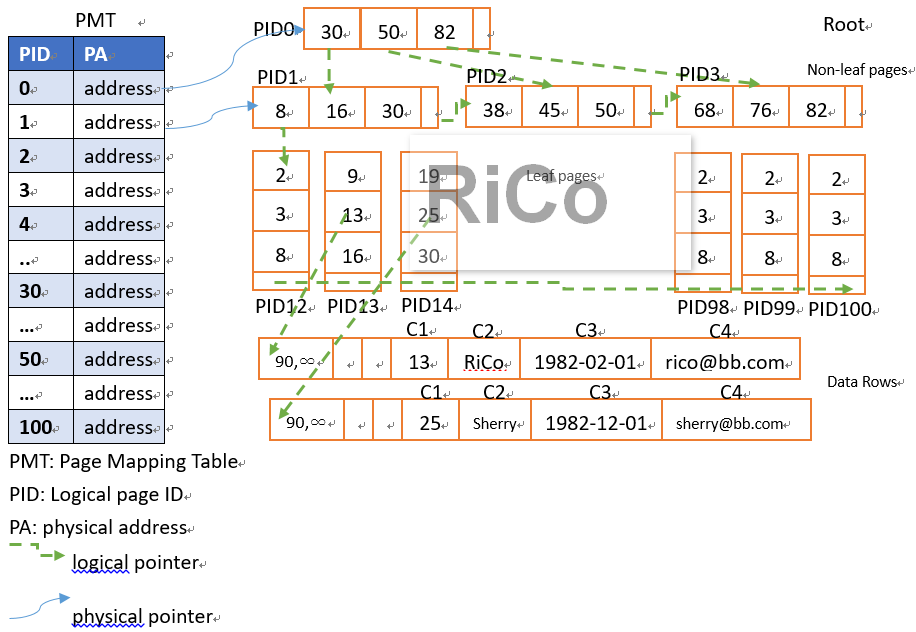
當我傳送where c1=13並使用range index搜尋時,會先從PID0開始並知道下一個page要使用PID1(因為8~30),
這時PID1會透過PMT提供相關PA,透過該PA我們知道PID13有我們需要的資料,
由於PID13已經是leaf page level,所以該page將提供真實資料的memory address,
而這時In-Memory OLTP engine也知道搜尋到該page就已經符合使用者所需資料。
如果C1重複多筆資料
這些重複資料都將被Linked再一起(類似hash indexes),
因為leaf page 不會包含這些重複row head
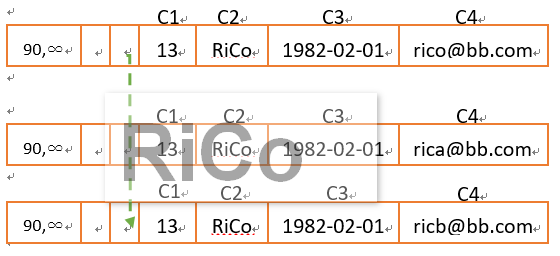
資料更新
如果我將原有13更新(update)為15,為了提高交易效率,in-Memory OLTP engine都不會再原有page更新,
而是建立(insert)一個較小的page包含資料變更資訊,最後在更新PMT上所對應的PA並指向最後更新的真實資料,
由於整個BW-tree存取路徑並不會變更,所以更可以節省記憶體開銷,
而被marked刪除的舊資料,後續將由GC自動回收。

參考
In-Memory OLTP – ORDER BY Behavior Clause Using Range Index
LOB and Row-Overflow Storage in In-Memory OLTP in SQL Server 2016