當我們使用Exists判斷資料是否存在時,是否需要再子查詢中額外使用 Top 1來告訴QO,
我只需判斷一筆資料即可,請不要進行多餘(非必要)的處理。
我在code review時,常看到一些SP同時使用top 1 with an exists來判斷資料是否存在,
今天我就來簡單驗證一下,這樣做到底有沒有意義(效益)呢?
SELECT InvoiceID ,
Description
FROM dbo.InvoiceLines pm
WHERE EXISTS (SELECT 1 FROM dbo.testDatetime s WHERE pm.InvoiceID = s.id)
SELECT InvoiceID ,
Description
FROM dbo.InvoiceLines pm
WHERE EXISTS (SELECT TOP 1 1 FROM dbo.testDatetime s WHERE pm.InvoiceID = s.id)
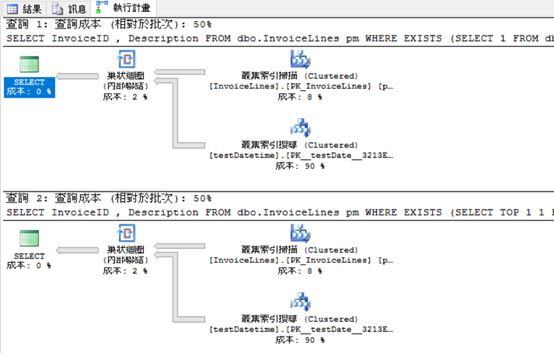

 你可以看到這兩句TSQL的執行計畫和I/O都一樣,並不會因為你在subquery的select中多寫或少寫TOP 1,
你可以看到這兩句TSQL的執行計畫和I/O都一樣,並不會因為你在subquery的select中多寫或少寫TOP 1,
而讓I/O、CPU更少或產生更低成本的執行計畫,另外,
exists已經告訴QO只需測試subquery是否存在符合條件資料,
而不會針對subquery的select list做任何處理,下面我在執行幾個query讓你更明白我在說什麼
SELECT InvoiceID ,
Description
FROM dbo.InvoiceLines pm
WHERE EXISTS (SELECT distinct s.sdate FROM dbo.testDatetime s WHERE pm.InvoiceID = s.id)
SELECT InvoiceID ,
Description
FROM dbo.InvoiceLines pm
WHERE EXISTS(SELECT 1/0 FROM dbo.testDatetime s WHERE pm.InvoiceID = s.id )
SELECT InvoiceID ,
Description
FROM dbo.InvoiceLines pm
WHERE EXISTS(SELECT case when s.id=1 then 'rico' else 'sherry' end FROM dbo.testDatetime s WHERE pm.InvoiceID = s.id )
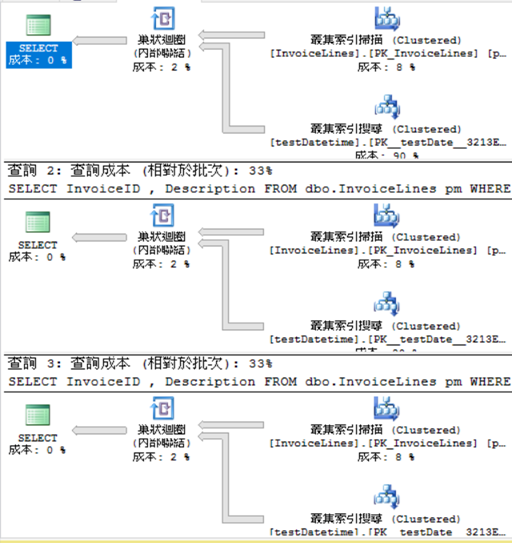


 這3句的執行計畫和IO都相同,
這3句的執行計畫和IO都相同,
我在subquery的select list中用了distinct、1/0和case end都能正常執行,
尤其1/0沒有發生除以零的錯誤,這更可證明exists的subquery的select list皆沒有意義(效益),
不管我寫的多花俏、多華麗或多有效率。
我相信你應該知道exists keyword的重點了,所以下面這句簡單statement應該也不難理解
IF EXISTS (SELECT 1 FROM InvoiceLines )
PRINT 'rico'
ELSE
PRINT 'rico is me'
IF EXISTS (SELECT TOP 1 1 FROM InvoiceLines)
PRINT 'rico'
ELSE
PRINT 'rico is me'
![]()
![]()
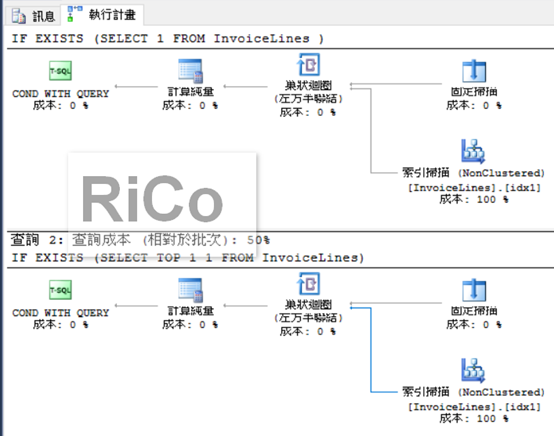
大多人看到subquery沒有任何條件,會很直覺的說兩句一定皆是scan操作,
而多寫TOP 1的subquery 的IO會比沒有TOP 1的subquery來的低很多,
實際看兩者的執行計畫皆有scan運算子,這裡雖然顯示一個index scan,
但要注意這不是一個完整的scan,因為實際和估計資料列數目都是1,
也就是說使用Exists,SQL SERVER會嘗試以最小數目來進行評估,
你更本無須加上TOP 1多此一舉,我在執行一個完整的index scan,
或許你能更明白我的意思。
我移除exists並單獨執行subquery如下:
SELECT 1 FROM InvoiceLines
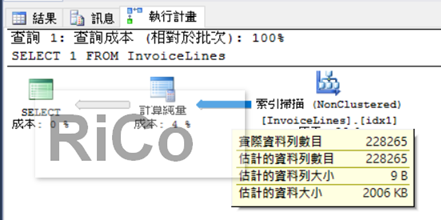
 我在進行執行計畫優化教育訓練時,我常說,完整的scan運算子(大資料量)才會影響效能,
我在進行執行計畫優化教育訓練時,我常說,完整的scan運算子(大資料量)才會影響效能,
我們也才有機會去改善,從上圖你就可以知道,
該index的完整scan需要400 pages,而這才是真正的scan操作。
再來看更複雜的statement
IF EXISTS (
SELECT 1 FROM InvoiceLines
WHERE InvoiceID >2 and InvoiceID <10
GROUP BY LEFT(Description,1)
HAVING COUNT(*) > 1
)
PRINT 'rico'
IF EXISTS (
SELECT TOP 1 1 FROM InvoiceLines
WHERE InvoiceID >2 and InvoiceID <10
GROUP BY LEFT(Description,1)
HAVING COUNT(*) > 1
)
PRINT 'rico'
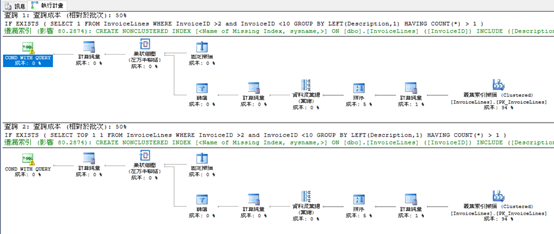
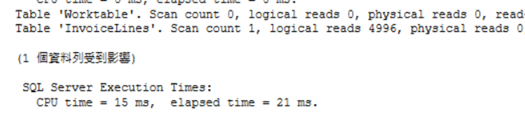
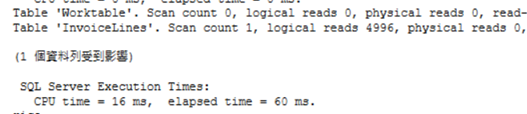
你依然可以看到執行計畫和I/O是相同,甚至CPU時間也大同小異(我會忽略經過時間,因為那大多是顯示資料時間,我個人會比較在意CPU和I/O),
這次QO需使用完整的叢集索引scan,因為我們使用了Aggregate Functions和having,
所以必須返回所有資料才能知道最後結果,
同時也證明TOP 1並無效益(無法中斷QO進行完整的scan操作)。
結論:
top 1 with an exists in subquery我認為只有增加該查詢大小(至少多了5個字元),
因為SQL Server的QO可是超過 30 年時間研究開發出來的心血,
說白話一點,QO絕對夠聰明並知道不會進行多餘(非必要)的處理。
參考