C#有關於爬蟲的那檔事
前言
內容絕對是一個網站熱不熱門的依據,通常一個網站擁有更多的資料,就會有越多人會去使用,這些資料有些是自己擁有的,有些可以透過一些open api,有些時候我們則可能會需要去爬一些內容,如果要使用c#去爬網站內容的話,目前最多人使用的還是Html Agility Pack(HAP),如果對這個第三方package有興趣的話,可以直接前往(https://github.com/zzzprojects/html-agility-pack)查看
下載HAP
可以直接使用nuget來下載,這邊我是使用linqpad來測試的
以威秀網站示例
這邊示例假設我想要去爬威秀網站的內容,以便知道目前威秀上映有哪些影片,那怎麼使用HAP來達成我的目的,我想爬的其實就是首頁的電影介紹區塊,那使用HAP就跟使用javascript的概念一樣,是用dom的概念去分析結構,再透過lambda可以很大的幫助我們去分析樹狀結構的資料,先看一下要分析的內容網站
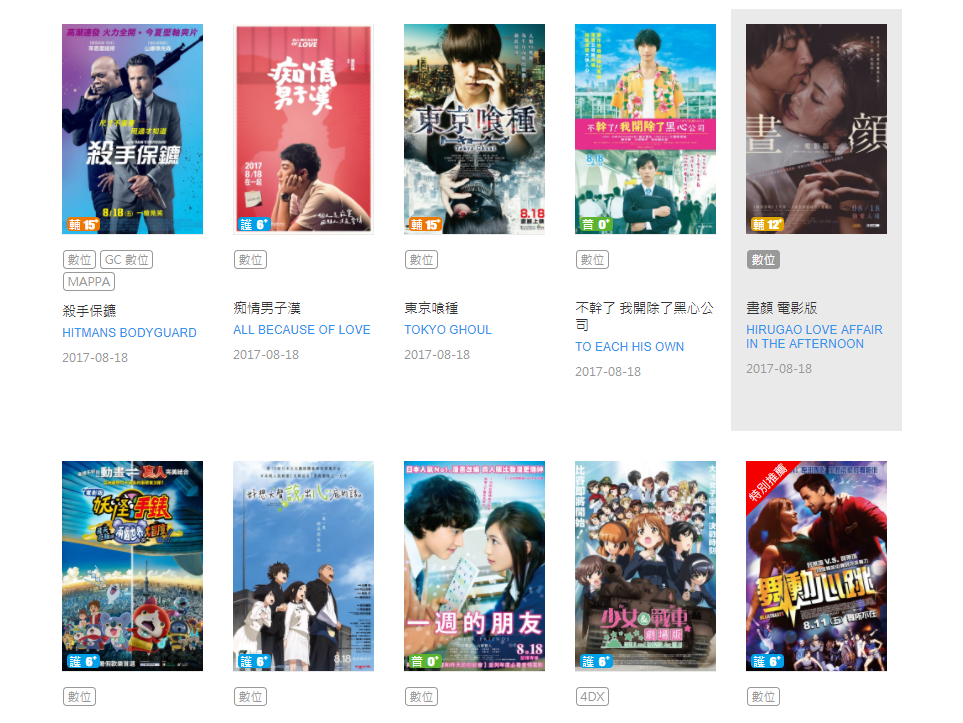
假設我想抓到的是圖片位置,還有連結跟影片名稱的話,那就來看一下我的程式碼是怎麼寫的吧
void Main()
{
var htmlWeb = new HtmlWeb();
var doc = htmlWeb.Load("http://web.vscinemas.com.tw/film/index.aspx/");
//選擇的ul整個區塊
var items = doc.DocumentNode.SelectNodes("/html/body/article/ul");
var viewShowDto=new List<ViewShowDto>();
foreach (var element in items)
{
var imageUrls=element.ChildNodes.SelectMany(x=>x.Descendants("img")).Select(a=>a.Attributes["src"].Value).ToList();
var urls=element.ChildNodes.SelectMany(x=>x.Descendants("a"))
.Select(x=>x.Attributes["href"].Value)
.Where(x=>x.Contains("?id="))
.Distinct().ToList();
var titles = element.ChildNodes.SelectMany(x => x.Descendants("h3")).Select(x => x.InnerText).ToList();
int i=0;
foreach (var item in imageUrls)
{
viewShowDto.Add(new ViewShowDto
{
ImageUrl = imageUrls[i],
Title = titles[i],
Url = urls[i]
});
i++;
}
viewShowDto.Dump();
}
}
public class ViewShowDto
{
public string ImageUrl { get; set; }
public string Url { get; set; }
public string Title { get; set; }
}
結果
| ImageUrl | Url | Title |
|---|---|---|
| ../upload/film/film_20170801002.jpg | detail.aspx?id=2738 | DAY 4 AQOURS 2ND LOVELIVE HAPPT PARTY 現場直播 |
| ../upload/film/film_20170801001.jpg | detail.aspx?id=2737 | DAY 3 AQOURS 2ND LOVELIVE HAPPY PARTY 現場直播 |
| ../upload/film/film_20170818001.jpg | detail.aspx?id=2772 | 即興舞台2017 PART 5-8 現場直播 |
| ../upload/film/film_20170811025.jpg | detail.aspx?id=2750 | 即興舞台2017 PART 1-4 現場直播 |
| ../upload/film/film_20170814004.jpg | detail.aspx?id=2716 | 軍艦島 |
| ../upload/film/film_20170731030.jpg | detail.aspx?id=2717 | 殺手保鑣 |
| ../upload/film/film_20170713075.jpg | detail.aspx?id=2718 | 痴情男子漢 |
| ../upload/film/film_20170731024.JPG | detail.aspx?id=2734 | 東京喰種 |
| ../upload/film/film_20170731022.jpg | detail.aspx?id=2714 | 不幹了 我開除了黑心公司 |
| ../upload/film/film_20170815002.jpg | detail.aspx?id=2751 | 晝顏 電影版 |
| ../upload/film/film_20170814002.jpg | detail.aspx?id=2735 | 電影版妖怪手錶 飛天巨鯨與兩個世界的大冒險喵 |
| ../upload/film/film_20170731023.jpg | detail.aspx?id=2715 | 好想大聲說出心底的話 |
| ../upload/film/film_20170814003.jpg | detail.aspx?id=2713 | 一週的朋友 |
| ../upload/film/film_20170815001.jpg | detail.aspx?id=1236 | 少女與戰車 |
| ../upload/film/film_20170718008.jpg | detail.aspx?id=2712 | 舞動心跳 |
| ../upload/film/film_20170731021.jpg | detail.aspx?id=2719 | 俠盜聯盟 |
| ../upload/film/film_20170718007.jpg | detail.aspx?id=2711 | 表情符號電影 |
| ../upload/film/film_20170718006.jpg | detail.aspx?id=2710 | 安娜貝爾 造孽 |
| ../upload/film/film_20170731002.jpg | detail.aspx?id=2707 | CARS 3 閃電再起 |
| ../upload/film/film_20170731009.jpg | detail.aspx?id=2732 | REAL |
結論
這邊只是示例怎麼去爬對方網站的內容,當我們內容取回來的時候是要保存起來,或者是顯示在畫面上就視需求而定了,從此示例可以看出一樣是用dom的思考方式,去對整個dom做解析,然後再用lambda去對整個樹狀解析做分解判斷,不過還真是希望有一天C#也能發明一套類似jquery取dom的邏輯方式去解析啊,或許是筆者還不知道,如果有人知道有類似前端解析dom的方式的話,再請告知筆者囉。

