許多人很害怕 Regular Expressions, 除了它的確不好學之外, 主要是因為大家普遍不太了解它能拿來做什麼。所以我在這裡要陸續舉出一些實際上的應用範例, 向讀者們示範 Regular Expression 在實際生活中能幫我們解決什麼問題。依照我的慣例, 當我想到什麼, 就會在原來的文章裡直接修改, 不另做通知, 也不會再寫另一篇新的文章...
如果你完全不懂 Regular Expression, 我建議你先去讀一下我寫的入門教學「[Regex] Regular Expression 詳論」。
在使用的工具方面, 我仍然最推薦 Sublime Text 3, 其次是 Visual Studio, 或者最新流行的 Visual Studio Code。此外, 其實 Word 本身也內建了跟 Regex 有點類似的所謂「萬用字元」搜尋與取代工具; 如果真的有需要, Regex 是派得上用場的。
或許讀者覺得奇怪, 為什麼我在系列文章裡介紹的是 .Net 的 Regex, 但偏偏推薦使用 Python 的 Regex 引擎的 Sublime Text 作為首選工具呢? 這是因為 Sublime Text 的搜尋與取代工具可以讓我們很方便地處理斷行字元; 我們甚至可以把好幾行一起拷貝到搜尋與取代工具的文字方塊裡頭去, 如此, 我們可以處理跨行的文字取代作業。其實在某個程度上 Visual Studio 也辦得到 (使用 [\s\r\n]* 取代斷行字元), 但是如果單就文字處理方面, 在操作的方便性上, 我個人覺得 Sublime Text 還是略勝一籌。
不過, 相對的, Sublime Text 在方塊狀選取比較不方便(使用 Shift + 滑鼠右鍵), 也不支援方塊狀的複製貼上。在這方面 Visual Studio 則是獲得大勝。所以實際上我個人是這兩個工具都搭配使用的, 缺一不可。
例一. XML 元素置換
首先, 我來舉一個最具代表性的 Regex 應用。假設我有一個 XML 文件如下:
<document version="1">
<item>
<number>1</number>
<content>blah blah</content>
</item>
<item>
<number>2</number>
<content>blah blah</content>
</item>
<item>
<number>3</number>
<content>blah blah</content>
</item>
...
</document>
由於某種原因, 我打算把這個文件寫成 HTML 相容格式, 讓它可以直接在網頁上直接呈現, 卻不必寫 XSLT。我們可以怎麼做?
至少有兩種方式可以馬上辦到。第一種, 把 <document> 和 </document> 標籤改成 <ol> 和 </ol>, 再把所有 <number> 元素刪除, 再把所有 <item> 和 </item> 改成 <li> 和 </li>, 把所有 <content> 和 </content> 改成 <span> 和 </span>, 結果如下:
<ol version="1">
<li>
<span>blah blah</span>
</li>
<li>
<span>blah blah</span>
</li>
<li>
<span>blah blah</span>
</li>
...
</ol>
如果使用 VS 或 Sublime Text 的話, 只需按下幾次 Ctrl-H, 做幾次置換動作, 就可以很快做好。其中要把所有 <number> 元素刪除的方法也很簡單, 啟用 Regex Expression 選項, 在「搜尋詞彙」或 "Find What" 字方塊中填入 "<number>\d*</number>" (不含引號), 另一個方塊保持空白, 就可以一次把所有該元素清除。至於它可能遺留的一個空行, 如果你看不順眼的話, 請讀者自己想辦法把它刪除, 方法其實我上面已經提示過了。
以上這種方法看來簡單快速, 但是它事實上把所有 number 元素清除了。如果你想把它留著, 怎麼辦? 在這種情況下, 我們可以這麼做:
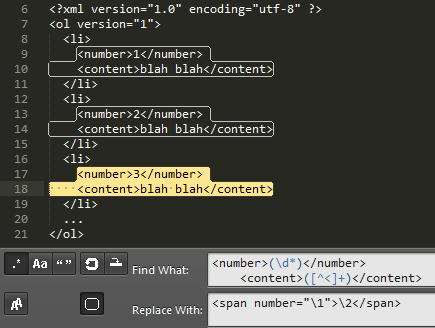
如上圖所示, 找出第一組數字和第二組文字, 再填入被取代文字內, 結果如下:
<ol version="1">
<li>
<span number="1">blah blah</span>
</li>
<li>
<span number="2">blah blah</span>
</li>
<li>
<span number="3">blah blah</span>
</li>
...
</ol>
如此, 這段文字不但可以當作 HTML 正常顯示, 也可以當作 XML 文件, 將裡面的數字取出。
如果你覺得你不想把這組數字塞進 attribute 裡, 而想讓它維持為 element 的話, 那麼你可以回到上一個方法, 把它變成 "<script>1</script>" 這樣的型式。那麼這段標籤既是標準的 XML 元素, 也不會顯示在網頁上。
在 Sublime Text 中第一組 matched 是以 \1 表示, 第二組則以 \2 表示; 如果你使用的是 Visual Studio, 它是以 $1 和 $2 表示(Sublime 也可以用), 依此類推。
像這類的文字取代作業, 雖然在我的範例中只有三個項目要處理, 但是實際上我們經常可以遇到成百上千個項目; 如果沒有 Regex 工具可用, 那可就變成十分惱人的問題了。所以 Regex 實在是開發人員不能不熟的一項必備技能!
例二. 數值範圍
Regex 不是程式; 或者說, 它的運作引擎並不是一個程式編譯器, 所以它能夠理解的語法相當有限。如果你不知道這一點的話, 就難免會懷疑為什麼它不能直接解析出一段數字區間, 例如 0~24。
曾經有一位 IBM 工程師來問我這個問題。當下我我回答說「很簡單呀, 就是 "(0|1|2|3|4|5|6|7|8|9|10|11|12|13|14|15|16|17|18|19|20|21|22|23|24)"」! 結果他覺得不太滿意, 喃喃自語說一定有更好的做法。
有沒有「更好」的做法, 我不知道。但是有沒有其它的做法, 那則是肯定的。不過, 你必須得先讀過我寫的「[Regex] 進階群組建構」這一篇才行。
但是在我繼續說明之前, 我們可以先來看看大家普遍上對這類問題的一般解法。至於到底哪一種做法比較好, 就交給你自己去判斷了。
我提出的做法如下, 你可以在 Rubular 上親自操作測試: http://rubular.com/r/QdHNB9Fx1R。
((?=\b\d\b)|(?=\b1\d\b)|(?=\b2[0-4]\b))(\d+)
基本上我提出的解法和上面提到的「一般解法」是一樣的, 但是我用到了「無寬度右合子樣式」(第二種用法)。
不過, 如果是我自己的話, 在數字區間不大的情況下, 我還是會採用 "(0|1|2|3|4|5|6|7|8|9|10|11|12|13|14|15|16|17|18|19|20|21|22|23|24)" 這種直覺的樣式, 因為效能差不了多少(這種做法效能是 O(n), 另兩種則是 O(log n), 在數量小的時候效能差異可以不計), 重點是不必傷腦筋, 只是多打一點字而已。
採用直覺的樣式還有一種好處。有時候, 你可能遇到數字區間並不是連續的狀況, 例如你的客戶突然要求「如果把 12 和 20 拿掉呢? 然後加上 301」, 這時若使用直覺的做法, 把 12 和 20 抽掉, 再填上 301 就行了, 但是另兩種做法就顯得麻煩許多。
當然, 如果數值範圍是例如 3000 萬到 2億這種區間, 直覺的樣式就絕對不可行了。
相關主題