[Cloud Computing]亞馬遜雲端服務當機事件
這次Amazon的事件恰恰就是Availability的議題,而Availability代表的是服務的可獲得能力,當我想存取這個服務時,他是不是活著?有沒有當機或者斷線?而這也是目前雲端廠商比較敢提出SLA(Service Level Agreement)的部分,Security跟你的系統管理與程式有關,Performance跟你的程式寫法、環境設定、使用者端的頻寬等有關,所以雲端廠商不太可能會提供SLA,而已Amazon EC2的SLA來說,他的標準是99.95%,也就是一年365天中,有99.95%的時間你的服務是活著的,在這樣嚴苛的標準下,只要你的服務掛了一天就算是不滿足SLA了,你可對Amazon索償,但索償不代表他會賠償你服務掛點這段時間的任何營業損失,而是他會跟你收較少的錢或者讓你免費用一些時間,以這次的案例來說,Foursquare掛了兩天,因此流失掉多少客戶或者掉了多少客戶滿意度,這些都是無法跟Amazon索賠的。
這是兩三天的事情了,到目前為止仍未完全平息:
Amazon Cloud Outage Staggers Into Day 2
伤不起!亚马逊史前最大宕机事件的启示
對雲端服務商來說,Amazon已經算是最成熟的雲端服務廠商,受這次事件波及的主要有Amazon的客戶如Foursquare(知名的LBS/社群服務供應商)、Quora(類似論壇服務又有點類似微網誌功能的服務)、Reddit(提供新聞服務)、Hootsuite(社交媒體資訊分析),其他更多受到影響的服務可以參考這邊:Who is affected by EC2?
雲端服務在這兩年的發展中,大家對於雲端仍然存在許多的疑慮,去年IDC的資料中(IT Cloud Services User Survey, pt.2: Top Benefits & Challenges)提到雲端運算發展的前10大困難,包含了Security、Performance、Availability等: 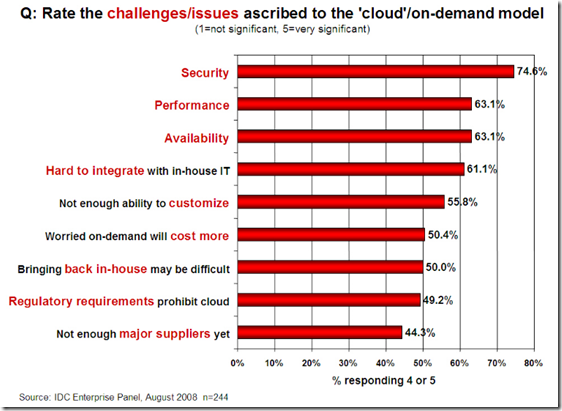
這次Amazon的事件恰恰就是Availability的議題,而Availability代表的是服務的可獲得能力,當我想存取這個服務時,他是不是活著?有沒有當機或者斷線?而這也是目前雲端廠商比較敢提出SLA(Service Level Agreement)的部分,Security跟你的系統管理與程式有關,Performance跟你的程式寫法、環境設定、使用者端的頻寬等有關,所以雲端廠商不太可能會提供SLA,而已Amazon EC2的SLA來說,他的標準是99.95%,也就是一年365天中,有99.95%的時間你的服務是活著的,在這樣嚴苛的標準下,只要你的服務掛了一天就算是不滿足SLA了,你可對Amazon索償,但索償不代表他會賠償你服務掛點這段時間的任何營業損失,而是他會跟你收較少的錢或者讓你免費用一些時間,以這次的案例來說,Foursquare掛了兩天,因此流失掉多少客戶或者掉了多少客戶滿意度,這些都是無法跟Amazon索賠的。
我在推廣雲端服務時最常被問到的幾個問題:服務掛掉怎麼辦?資料放雲端遺失或者被嫖竊怎麼辦?整合問題怎麼辦?
這些問題在這次Amazon的事件後應該會更難搞,Amazon這次影響到的不只有他自己,更會影響到雲端運算的發展,讓大家對雲端的疑慮又多了一些,真的是個壞消息,如果Amazon在事件發生後HA機制立即啟動,若Data Center的服務整個掛了,看是否啟動跨Data Center的服務,讓服務移到另一個Data Center並儘快的on起來,讓服務不會中斷太久,這樣最少仍不會造成太大的影響,現在一掛掛兩天,太傷太傷了。
進一步的後續資料可參考這篇:[Cloud Computing]Amazon Web Service Outage事件後續
 |
游舒帆 (gipi) 探索原力Co-founder,曾任TutorABC協理與鼎新電腦總監,並曾獲選兩屆微軟最有價值專家 ( MVP ),離開職場後創辦探索原力,致力於協助青少年培養面對未來的能力。認為教育與組織育才其實息息相關,都是在為未來儲備能量,2018年起成立為期一年的專題課程《職涯躍升的關鍵24堂課》,為培養台灣未來的領袖而努力。 |
