在部份環境下因為建立計算欄位造成伺服器效能低弱 , 因此改用其他方法來解決效能問題
記得在幾年之前有寫過一篇文章「利用計算欄位搭配 Index 來提升效能」,一值以來會用這樣的方式來解決,像是在 ERP 系統中的單別+單號的查詢問題,或者是DATETIME 欄位要用日期來當索引,都算是一個很便利的方式。最近遇到一個特別的案例,因為在資料庫的定序中他設定區分大小寫,但是某個欄位值在判斷的時候,希望要不分大小寫去找資料,因此大部分時候大家都會用以下幾種做法
-- 轉換成大寫
SELECT * FROM Person where UPPER(FirstName) = 'GIGI'
-- 轉換成小寫
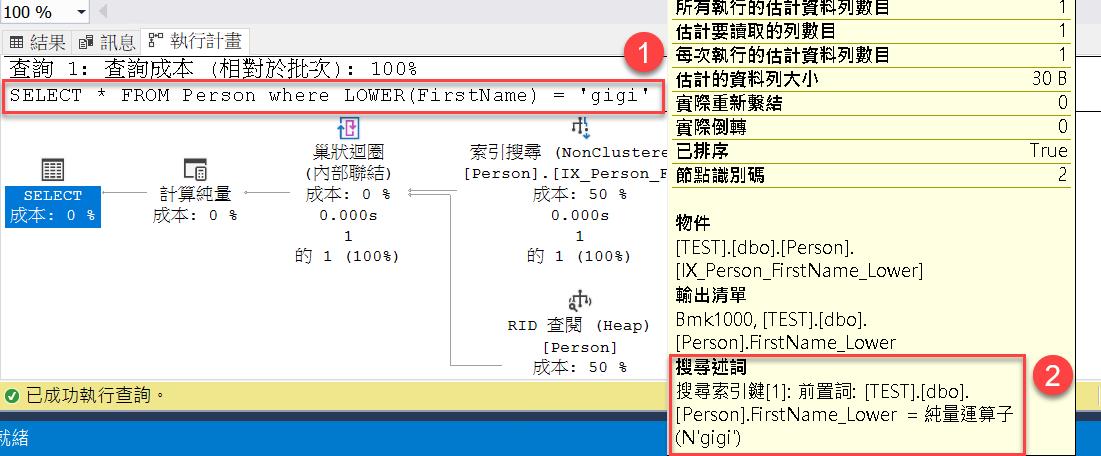
SELECT * FROM Person where LOWER(FirstName) = 'gigi'
-- 改變欄位定序
SELECT * FROM Person where FirstName = 'gigi' COLLATE Chinese_Taiwan_Stroke_CI_AS;如果在資料量不多,或者是沒有頻繁的查詢時候,這些都算是不錯的寫法。但是這樣的做法會導致 SARG 的問題,使得欄位的索引是沒有辦法來做使用。當然在我們前面所分享的另外一篇文章中,我先利用計算欄位來產生一個新的欄位,這樣就可以在該欄位上來建立索引了。
但是剛好在遇到的案例上,資料表的資料筆數非常的多,又有非常大量的異動,再加上那個資料表有做相關的複寫,使得我們如果要利用計算欄位來做處理,很有可能沒有辦法在可維護的時間內完成,因此會希望可以有其他的方式可以來處理。
因為要避免引響原本的資料表的儲存,基本上有兩個方式可以來進行:
- 一樣使用計算欄位,但是建立欄位的時候不要加入 PERSISTED 的參數,但是這樣雖然還是可以達到類似的效果,但是大量資料異動的時候,因為計算欄位沒有設定實際儲存,雖然還是可以用該欄位來建立索引,但是會造成每次要該欄位值的時候都要重新計算。
- 利用建立一個具有 SCHEMABINDING 的 View ,並且將要特別處理的欄位放在該檢視中,後續並且針對該欄位來建立叢集索引。
但因為如一開始所談的,這個資料表的資料異動和查詢次數太高,因此會先不使用增加計算欄位的方式來處理,改用具有索引的檢視,因此下面的範例我建立一個具有 SCHEMABINDING 的 View 和具有 Unique Clustered Index
CREATE VIEW dbo.v_Person
WITH SCHEMABINDING
AS
SELECT
[BusinessEntityID], [PersonType], [NameStyle], [Title], [FirstName], [MiddleName]
, [LastName], [Suffix], [EmailPromotion], [rowguid], [ModifiedDate]
, LOWER([FirstName]) AS [FirstName_Lower]
FROM dbo.Person
GO
CREATE UNIQUE CLUSTERED INDEX IX_v_Person_FirstName_Lower ON v_Person([FirstName_Lower],[BusinessEntityID])
GO但是很不幸的,在這個實驗過程中不是很順利,看起來並沒有改善

這樣的結果實在是差強人意,於是我又另外找一個資料表來做測試
CREATE VIEW v_SalesOrderHeader
WITH SCHEMABINDING
AS
select
[SalesOrderID], [RevisionNumber], [OrderDate], [DueDate], [ShipDate], [Status], [OnlineOrderFlag], [SalesOrderNumber], [PurchaseOrderNumber], [AccountNumber], [CustomerID], [SalesPersonID], [TerritoryID], [BillToAddressID], [ShipToAddressID], [ShipMethodID], [CreditCardID], [CreditCardApprovalCode], [CurrencyRateID], [SubTotal], [TaxAmt], [Freight], [TotalDue], [Comment], [rowguid], [ModifiedDate],
LOWER([PurchaseOrderNumber]) AS POID
from [Sales].[SalesOrderHeader]
GO
CREATE UNIQUE CLUSTERED INDEX IX_SalesOrderHeader_POID ON v_SalesOrderHeader(POID,[SalesOrderID])
GO此時當我比較兩段 SQL 的時候,可以從下圖中看到 SQL Server 會很自動的去使用 Index view 上面的索引,也透過該索引可以讓查詢的效能有所提升

因此總結一下前面的一些過程和問題
- 儘量避免 SQL 指令違反 SARG , 像是避免在欄位上使用函數或者是不正確的型態去比較,這樣適當的搭配索引才會有好的果效。
- 如果不得已需要使用的時候,使用計算欄位搭配索引是個可以採用的方式,但最好是要加上 PERSISTED 的標示,只是比較大的缺點是會多佔用磁碟空間,如果有使用複寫則也要注意當下可能會有很大量的資料傳送。
- 如果有特殊狀況,或許可以考慮採用 Index View 來搭配 Unique Clustered Index 使用,只是這個方式還是會有些限制,並非您建立瞭索引 SQL Server 就一定會去採用。
- Index View 除了限制不能關聯其他檢視或資料表,建立的時候要搭配 WITH SCHEMABINDING選項外,還要注意有些欄位型態是不能使用的,像是 XML 欄位型態就沒有支援。
- 我們始終無法預期查詢最佳化將做什麼,SQL Server 會自動將 Unique Clustered Index 視為查詢的一個選項,但如果它找到“更好”的索引,他就會去使用該索引。