當瞭解單一個 story 怎麼使用 relative estimation 的原則估算出 story point 後,這篇文章將介紹怎麼運用同樣的精神,針對整個專案的時程進行推估。公式只有一個,而且再簡單不過了。
時程(schedule) = 範圍(PBI story points) / 速率(velocity)
前言
在上一篇文章《Scrum Estimation-Dog Point Game》中提到,該如何讓敏捷開發團隊透過 Dog Point Game 來熟悉相對估算的精神,並以團隊一同進行估算的方式,針對需求複雜度取得相對客觀的共識。
然而,一個傳統團隊要成功轉型成 Scrum 開發團隊將面臨許多困難,其中有很大一部分是來自於產品擁有者(Product Owner, 後續簡稱 PO )的思維,是否能接受敏捷開發的概念。想讓 PO 接受敏捷開發,就必須先瞭解 PO 的需求以及他可能會碰到的問題。只有協助滿足他的需求,解決他的問題,才能建立 PO 與 Team 之間的信任。
而 PO 最重要的問題之一就是「如何評估專案時程」,本文將提出一種能在 Scrum 中運用相對估算的精神,透過實際的數據進行相對推估,以便 PO 能隨時依據不同情況回答這個棘手的問題。
迷思
在 PO 詢問團隊:「能否讓我知道,這個專案你們預計多久可以完成?」
團隊請千萬不要回答:「因為我們 run 敏捷開發,所以要到實際估算時才會知道每一個 story 要花多久。而且我們只估算接下來的 1~2 個 sprint ,因為之後的一切都會變化,估了也估不準,告訴你也沒用。」這樣的答覆只是在逼你的 PO 走回頭路。
PO 心裡可能會想,為什麼在傳統的開發方式中,開發團隊至少可以透過工作分解結構(Work Breakdown Structure,簡稱 WBS)來評估一個時程目標,到了敏捷開發反而變成「做多少,算多少」這種不負責任的態度?那還不如用傳統的方式來進行開發,至少讓我可以對我的老闆跟客戶交差,至於品質與時程,當然還是開發團隊要負的責任,跟我 PO 無關。而且敏捷開發不是說要擁抱變化、儘早交付、鼓勵需求異動?到時候我看你們怎麼死的。
當 PO 開始用這樣的態度來要求團隊時,團隊成員就會覺得這個 PO 沒有敏捷心態(Agile Mentality),是個不知上進、改變、跟不上趨勢潮流的落伍角色,而又開始製造出角色之間的對立。
Step 1:按順序整理好 Product Backlog Items
首先請 PO 整理好整個專案的專案待辦項目(Product Backlog Items,後續簡稱 PBI),別被詞彙嚇到了,其實就只是在專案範圍內,有哪一些 features/stories/function list 需要完成。
請記得,在敏捷開發中的優先順序(Priority )相當重要,因此當所有 PBI 都被整理出來後,務必請 PO 按照優先順序排好。
若以開發一個購物車系統的部分需求來當例子,如下表所示:

Step 2:以 T-Shirt Size 來定義 PBI 的相對大小
這個步驟相當簡單,先以 t-shirt size (Small, Medium, Large) 三種等級來定義 PBI 的相對大小。
PO 只需要問自己:「如果只有大、中、小三種 size 的話,這個 PBI 應該屬於哪一種等級?」
假設 PBI 在 PO 評估完 size 後,結果如下表所示:

把整個 PBI 的大小等級都分類完後,應該每個 size 都有被使用到,否則可能需要協助 PO 回顧一下,這樣的相對分類是否需進行調整。
此外,可以按照團隊與 PO 的習慣或需求,區分成更多等分,例如 “1, 2, 3, 4, 5” 或 “S, M, L, XL, 2XL”,雖然分越多類似乎越精準,但太多類其實反而容易造成 PO 定義 size 的困擾。建議 3 類,最好不要超過 5 類。當然,在整個專案開發過程中,還沒完成的 PBI 也隨時可以調整其 PBI 的 size 評估。
Step 3:使用 Sprint 0 進行穿刺實驗
接著有兩種方式可以方便估算出,整個 product backlog 需要團隊花多少時間才能交付。假設目前團隊正式的 sprint 時間為 2 週。
第一種是按照 PBI 順序挑出第一個 L 、第一個 M 、第一個 S 的 PBI ,來當做穿刺實驗(Spike in XP 及 wiki 的說明)的標的物,並在 sprint 0 中完成這三個 PBI 。
第二種是直接以 sprint 1 當穿刺實驗的基底,按照 PBI 的順序進行 story point 的估算與開發,在 sprint 1 結束後,一樣可以得到團隊產出速率。
不論採用何種方式,期望得到的資訊如下:
- 每一種 size 評估出來的 story point。
- 推估出團隊每個 sprint 的產出速率,也就是團隊每個 sprint 可完成多少 story point。
- PBI 的 size 是否有大到超出 sprint 的範圍,也就是一個 sprint 做不完某一種 size 的 PBI 。若有此情況,則需考慮拆細 PBI 並調校 size 的定義。
以 sprint 0 的 spike solution 為範例,假設估算如下所示:
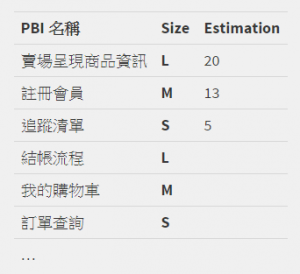
假設這三個 PBI 總共花了團隊 1 週的時間完成 (4/20~4/26)。因此可以得到以下的基礎資訊:
- 團隊的 velocity 為 (20+13+5) * 2 = 76
- 各 size 對應的 story point 基準為
- L: 20
- M: 13
- S: 5
目前 product backlog 上分別有 2 個 L , 2 個 M , 2 個 S 共 6 個 PBI 。以上述兩個資訊為基礎,可以推算出完整的 product backlog 總大小為 2*20 + 2*13 + 2*5 = 76,剩下的 product backlog 大小為 38 。
團隊每個 sprint 可完成 76 個 story points ,因此要消化剩下的 PBI 只需要 38/76 = 0.5 個 sprint ,也就是一週的時間,也就是若 4/27 開始進行,可以在 5/3 完成整個專案。
考考你
如果經過 Spike 試驗後, L 為 40 , M 為 20 , S 為 10 ,每個 sprint 為 2 週,團隊的 velocity 為 50 ,sprint 1 從 2015/5/4 開始進行,那麼下面的 product backlog 何時可以完成?

推估如下:
- 整個 product backlog 大小為:2*40 + 3*20 + 4*10 = 180 story points
- 團隊 velocity 為 50 ,所以需要 180/50 = 3.6 個 sprints = 50.4 天,約 51 天。
- Sprint 1 起始日為 5/4,整個 product 預計於 6/24 可完成。
結論
透過上述簡單的三個步驟,Scrum 團隊以實際的估算來相對推估出整個 product backlog 的大小,並以實際的產出來推估出團隊的 velocity。
其重要的精神在於:
- PO 透過相對比較,定義 PBI 大小
- 團隊實務上的相對估算,放大到完整的 product backlog ,推算出 product backlog 大小
- 團隊實務上的產出速率,推算到整個 product backlog 需消化的時間
這樣的方式帶有幾點好處:
- 團隊一起進行
- 實務回饋
- 以 PO 的分類與順序為基底進行
- 隨時可以對 PBI 的 size 與順序進行調整,也隨時可以移除或插入新的 PBI ,都可以計算出整個 product 相對應的交付時程,或限定時程內可以交付的 PBI 有哪些。
最後,我個人比較喜歡使用「推估」而非「預估」,雖然相對估算並等比例放大很可能會帶有誤差,但總比過去 WBS 那種以個人過去經驗來「猜測」整個專案的時程來得可靠得多。而且這樣的估算方式,示每一個變化的當下,都可以進行 review 與調整,也就是 Scrum 中重要的精神: inspect and adapt 。
請不要再把 PO 推向懸崖了,請把 PO 當成團隊最重要的一員,只有成為「一個團隊」,衝刺(Sprint)才會是同個方向,才會有力道。
另外,完整的 product 交付時程,建議以 sprint 為單位,也就是最後要無條件進位,會比較貼近實務上的需求與經驗。
blog 與課程更新內容,請前往新站位置:http://tdd.best/
