SQL SERVER
由於SQL SERVER的索引是採用(B-Tree)資料結構。
先來看,沒有排序過的資料30,50,25,70,2,10,55,27,35,如果從中找到55,須逐一比對,總共要花
七次的比對成本。
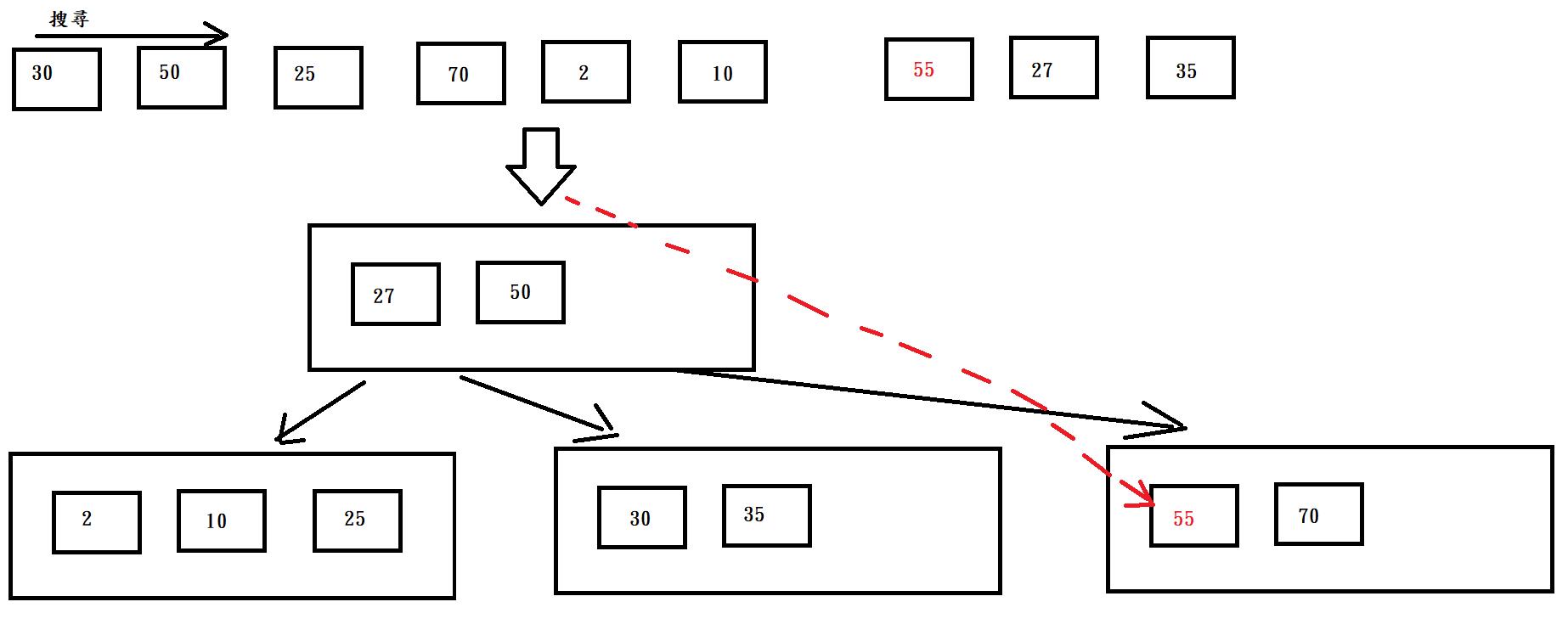
若用上述的圖,樹狀結透查詢55,從最上根節點比對27和50,因為55 > 50 所以往右邊的子節點前
進,然後再比對一次,就可在第三次找到資料。
利用樹狀結構可以縮短搜尋次數(效率)。
B-Tree樹狀結構分成以下三種
根節點(root node):樹狀結構的第一層B-tree只會有一個根節點。
葉節點(leaf node):樹狀結構的最下面一層,也就是說他的下一層,不在有任何的子節點。
內部節點(internal node):位於根節點與葉節點之間的所有層、稱之為,內部節點。
SQL SERVER提供索引的結構:分成叢集索引與非叢集索引,這兩種都是B-Tree,如果沒叢集索引就會是Heaps。
叢集索引:叢集索引是將資料表或檢視中的資料列,依其索引鍵值排序與儲存,這些就
是索引定義中包含的資料行。
因為資料列本身只能以一種順序排序,所以每個資料表只能有一個叢集索引。 若資料表有叢集索引時,
資料表又稱為叢集資料表。若資料表沒 有任何叢集索引,資料列就儲存在未經排序的結構中,此結構稱為堆
積結構。
註記:資料表建立完成之後,設定主P-Key,就是預設叢集索引,但是主索引不一定是叢集索引、叢集索引不
一定就是P-Key。
非叢集索引: 非叢集索引是與資料列完全分開的結構。非叢集索引包含非叢集 索引鍵值,每個索
引鍵值項目都有一個指標,該指標指向包含索 引鍵值的資料列。 叢集索引是將資料與索引儲存在
一起,每個表格只能有一個叢集索引,且資料是經過排序,速度較快。而非叢集索引是將資料與索
引分開儲存,類似指標的概念,且資料可能未經排序。在資料 表中可以設定多個非叢集索引,但只
能設定一個叢集索引,因為非叢集索引不會影響實際資料的排列順序。
範例如下
CREATE TABLE Emp(
ID int ,
Name varchar(20) ,
Area varchar(30) ,
Ext char(3) ,
Birthday date
)
INSERT INTO Emp (ID ,Name ,Area ,Ext ,Birthday) VALUES(3,'李一','taipei','100','1995-03-03')
INSERT INTO Emp (ID ,Name ,Area ,Ext ,Birthday) VALUES(4,'鬼三','taipei','100','1995-02-03')
INSERT INTO Emp (ID ,Name ,Area ,Ext ,Birthday) VALUES(5,'館長','keelung','200','1995-04-03')
INSERT INTO Emp (ID ,Name ,Area ,Ext ,Birthday) VALUES(1,'李小龍','tainan','300','1995-05-03')
INSERT INTO Emp (ID ,Name ,Area ,Ext ,Birthday) VALUES(2,'李武','taipei','400','1995-07-03')
SELECT * FROM Emp;
go
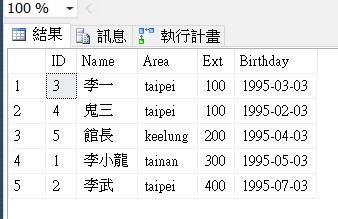
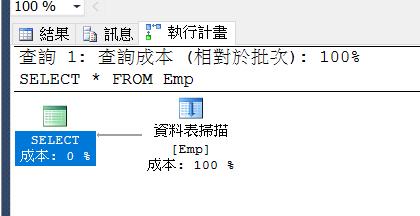
從上述來看會歸納出以下幾點
- 上述圖來看沒有叢集索引的資料表,稱謂Heaps。
- 沒有用到索引的資料表,一定會用到Table Scan。
- 從Heaps的第一筆讀取到最後一筆結束。
SELECT * FROM Emp
WHERE ID = 2
改用WHERE之後
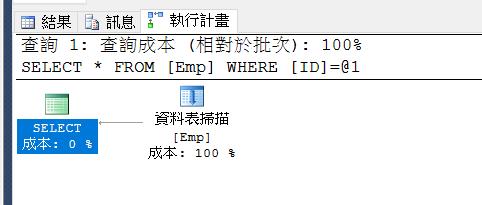
雖然有用到WHERE,但系統不知符合資料有幾筆,分布在何處,仍會從Heaps的第一筆讀取到最後一筆結束。
兩個語法比較一下
SELECT * FROM Emp
GO
SELECT * FROM Emp
WHERE ID=2
GO
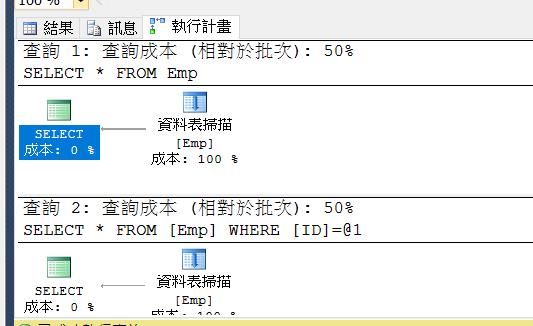
只要Heaps,不論有沒有用where,一定都會Table Scan,兩者成本也會是一樣。
元哥的筆記