PDF 檔案雖屬於文件格式,但其內容經常包含表格與清單等結構化資料。因此,能夠從 PDF 中正確萃取出資料表格,不僅是進行資料外部匯入的常見需求,也是資料轉換與前處理階段中不可或缺的重要技能。
這類型的檔案格式是屬於固定格式,主要設計為人們可以閱讀的文件,內容支援本文、圖像和多媒體內容,常運用於報表或檔案分享,且具有跨平台的一致性。但也因此,與其他檔案相比,PDF缺乏結構化儲存,資料提取就會比較困難。有時需要藉由OCR工具(光學字元識別)來處理掃描型PDF。至於電子檔案格式的PDF,透過Power Query等類型的ETL工具,亦可輕鬆進行解讀與轉換。但要注意的是,並非每一個PDF檔案的內容都適合擷取與轉換。譬如:必須確認PDF是否可解析,如果是內含表格的內容,也建議必須注意進行分頁和欄位的標記,也需要注意資料擷取的精確度,避免因格式複雜而導致錯誤。如下所示的PDF為文件,裡面僅有幾頁包含了幾個表格,是值得擷取、轉換與分析的。
Power Query除了可以解析整份PDF整份文件外,也可以根據您的需求而指定要分析的起訖頁數,一切都交由Pdf.Tables()函數來完成。
Pdf.Tables()函數
在Power Query的環境下,是透過Pdf.Tables()函數來解析PDF文件的內部結構和內容。這是Power Query功能強大的重要內建函數,它會尋找看起來像表格的區域,這些區域通常由文字、線條(如果存在)和空白間距組成。函數會嘗試識別表格的邊界、欄和列,並將其轉換成 Power Query 的表格結構,形成資料表(Table)形式的結構化資料。
常見使用案例:
- 從 PDF 報表中提取數據進行分析。
- 將掃描的表格轉換為可編輯的資料格式(儘管對於掃描的 PDF,OCR 的準確性可能會影響提取結果)。
- 自動化從定期收到的PDF文件中提取表格資料的過程。
局限性:
- PDF 格式的複雜性:PDF是一種文件呈現的檔案格式,而不是專門應用於儲存結構化資料的格式。因此,Pdf.Tables()的提取結果有可能並不是那麼的完美。
- 表格結構不清晰:如果PDF中的表格沒有明確的邊框或分隔符,或者排版非常複雜,函數極可能難以正確識別表格結構。
- 掃描的PDF:對於掃描的PDF文件,Pdf.Tables()通常無法直接提取文字。使用者或許需要先使用OCR(光學字元辨識系統)技術將掃描的內容轉換為可選取的文字。
- 非標準表格:有些PDF文件可能包含使用非標準方式排版的「表格」,這些資料可能無法被Pdf.Tables()正確識別。
Pdf.Tables()函數的標準語法為:
Pdf.Tables(pdf as binary, optional options as nullable record) as table
- 第1個參數pdf是必要的,表示PDF檔案的內容。通常是透過File.Contents("檔案路徑")來載入PDF檔案,或者是二進制格式的檔案。
- 第2個參數則是可以選用的,這是一個記錄型態的選項值,用來指定額外的規範,諸如指定曲資料的起始頁與結束頁,以及指定使用的解析器,例如"1.3"表示PDF版本兼容解析器。
例如:
來源 = File.Contents("F:\ Report.pdf"),
輸出 = Pdf.Tables(來源, [StartPage=2, EndPage=5, Implementation="1.3"])
表示匯入來自D:\DATA路徑名為「Report.pdf」的檔案,而這個查詢只會提取 PDF 文件中第2頁到第5頁之間的表格。在解析此PDF檔案時是採用"1.3"版本的解析器。讓您覺得有些PDF內容複雜或格式較舊,資料表的識別若並不顯著,可以嘗試著切換 成Implementation="2.0" 看看會不會有所改善。以下就帶領大家實作演練一番囉!
第一個範例
首先,開啟空白活頁簿後點按[資料]索引標籤[取得資料]命令按鈕,從展開的功能選單中點選[從檔案]裡的[從PDF]功能選項。
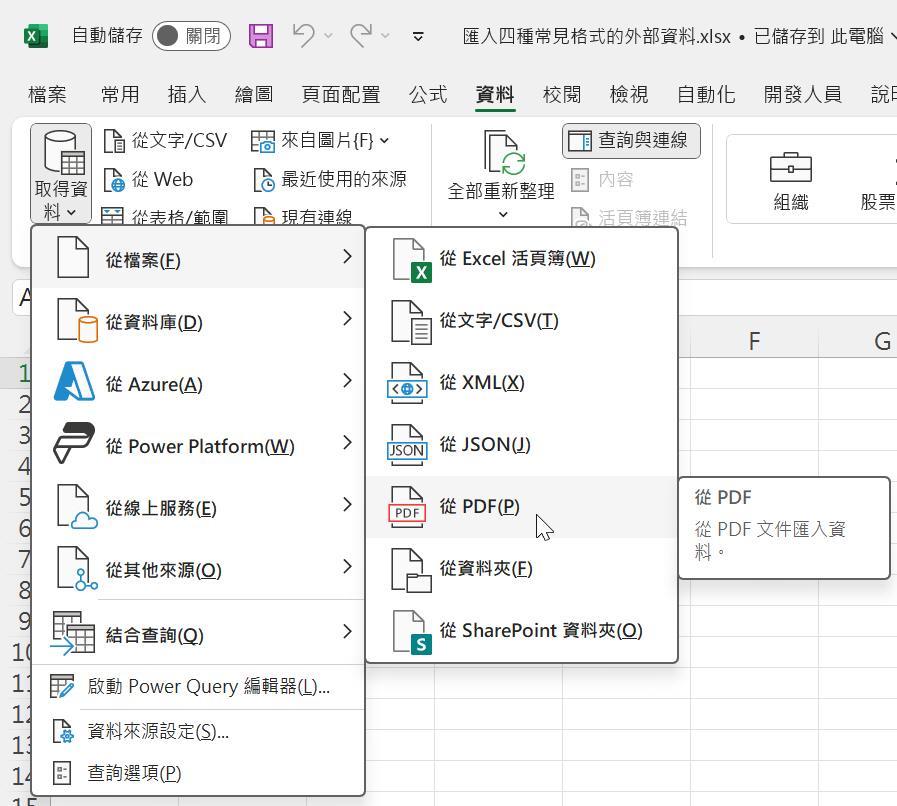
開啟[匯入資料]對話方塊,選擇此文章的實作範例檔案[台灣地區主要咖啡連鎖市場研究報告.pdf]。
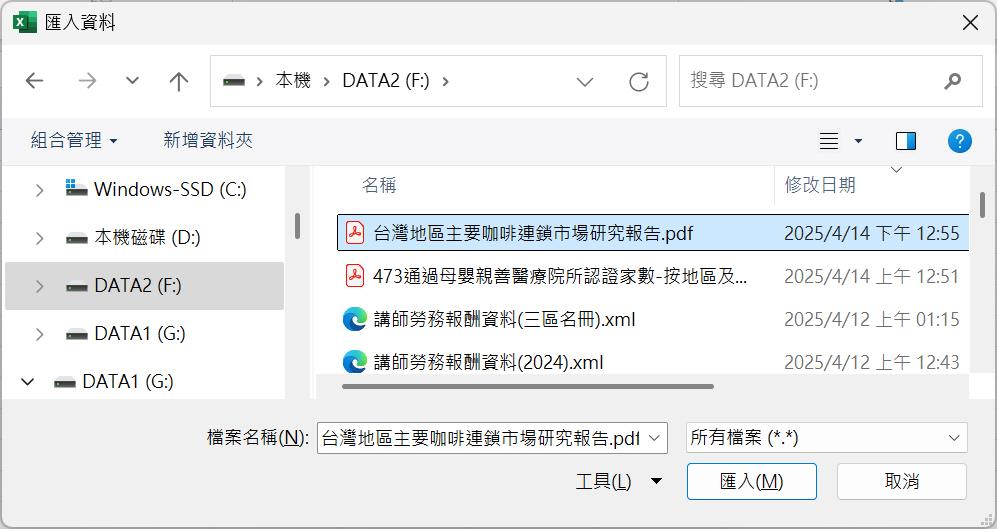
如同匯入他檔案格式一般,隨即進入導覽畫面,在此可看到Power Query已經解析出這份PDF文件裡有多頁可以解讀的頁面(Page)與表格(Table)。點選這些資料來源時,右側就可以預覽其內容。
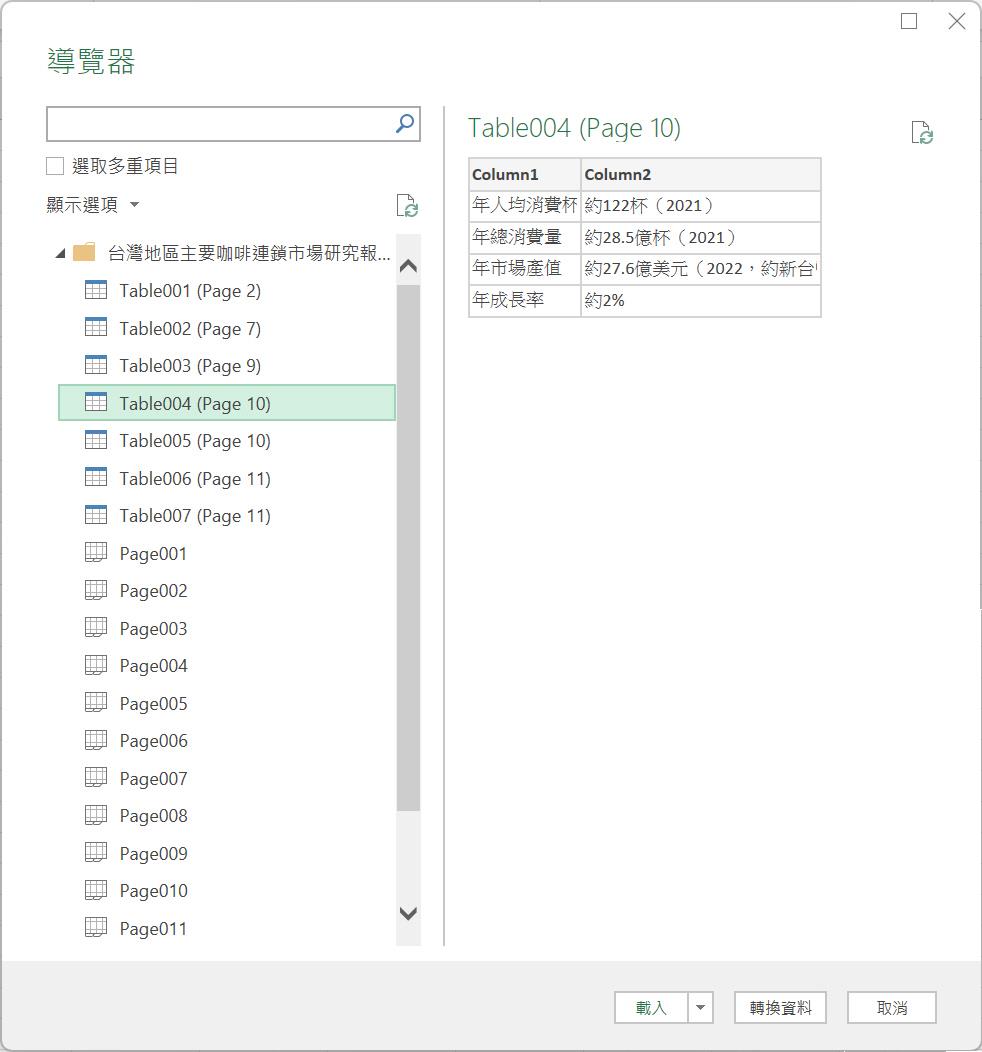
在此我們勾選「選取多重項目」核取方塊後,分別勾選所要的「Table003(Page9)」、「Table005(Page10)」與「Page007」等三個資料來源。最後,點按[轉換資料]按鈕。
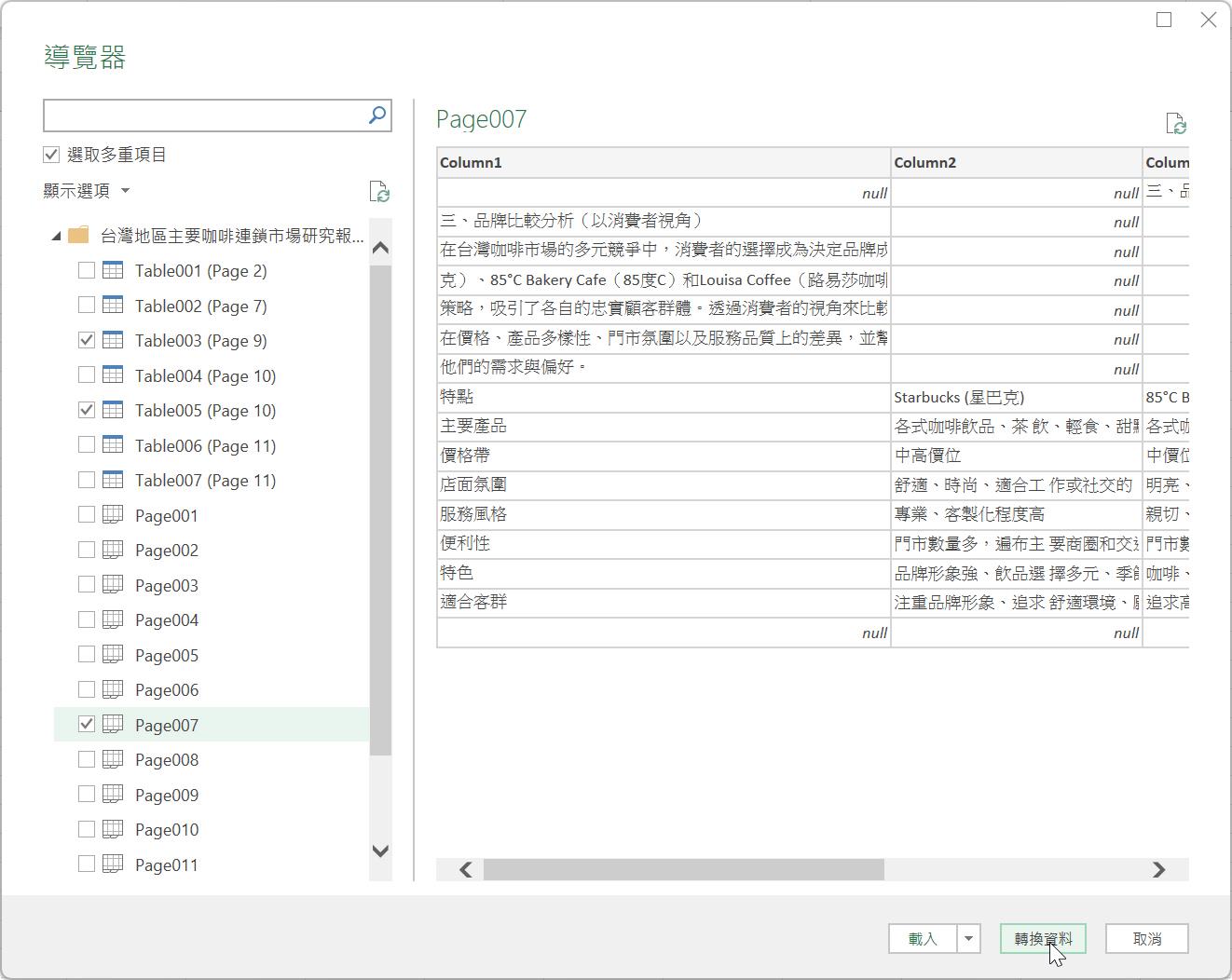
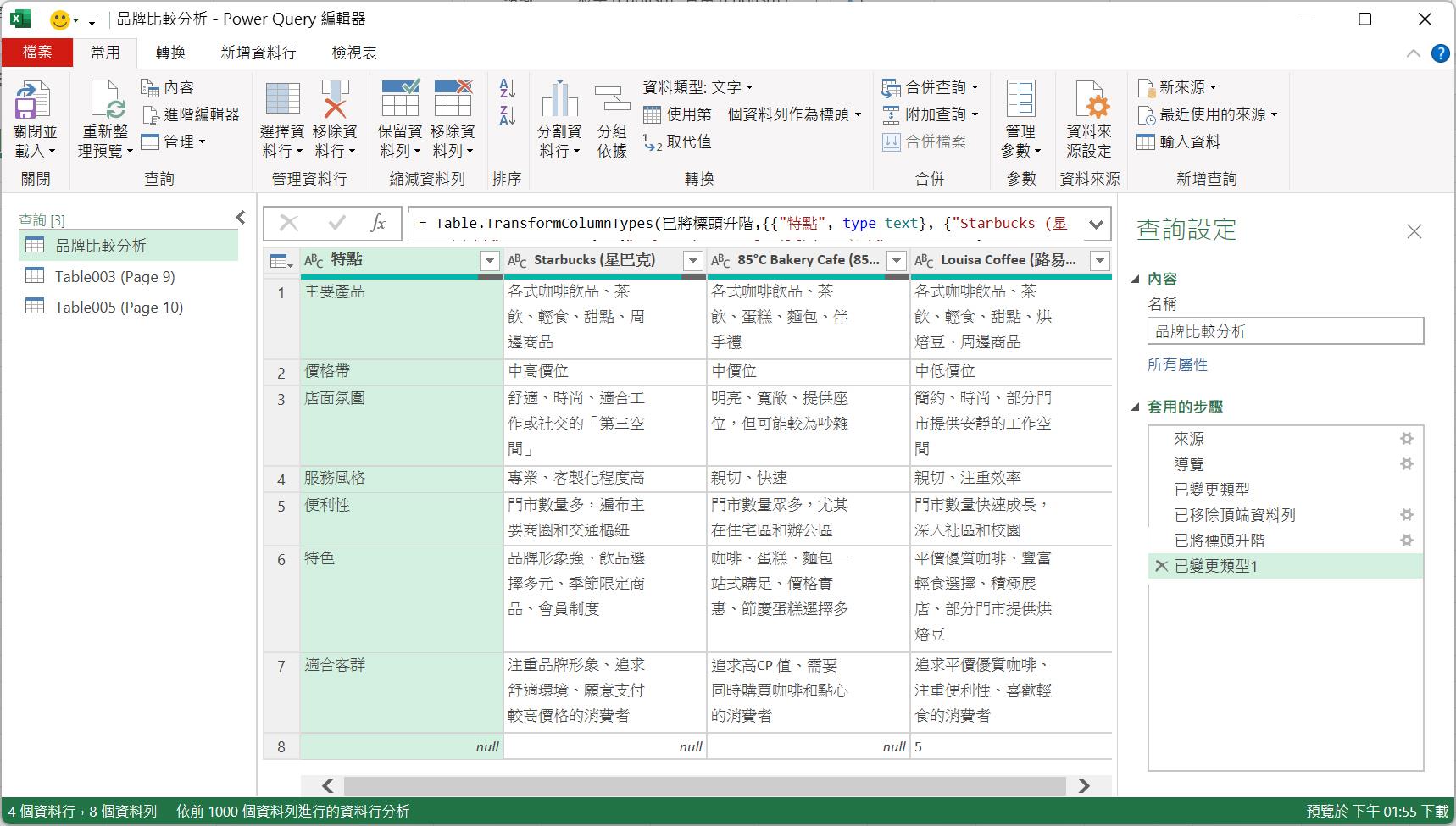
隨即開啟Power Query編輯器,立即看到建立了三個查詢,分別等您處理先前勾選的3個資料來源。依查詢名稱的筆畫順序來說,第1個查詢是來自Page007的資料來源,描述著三個品牌咖啡的比較分析。'
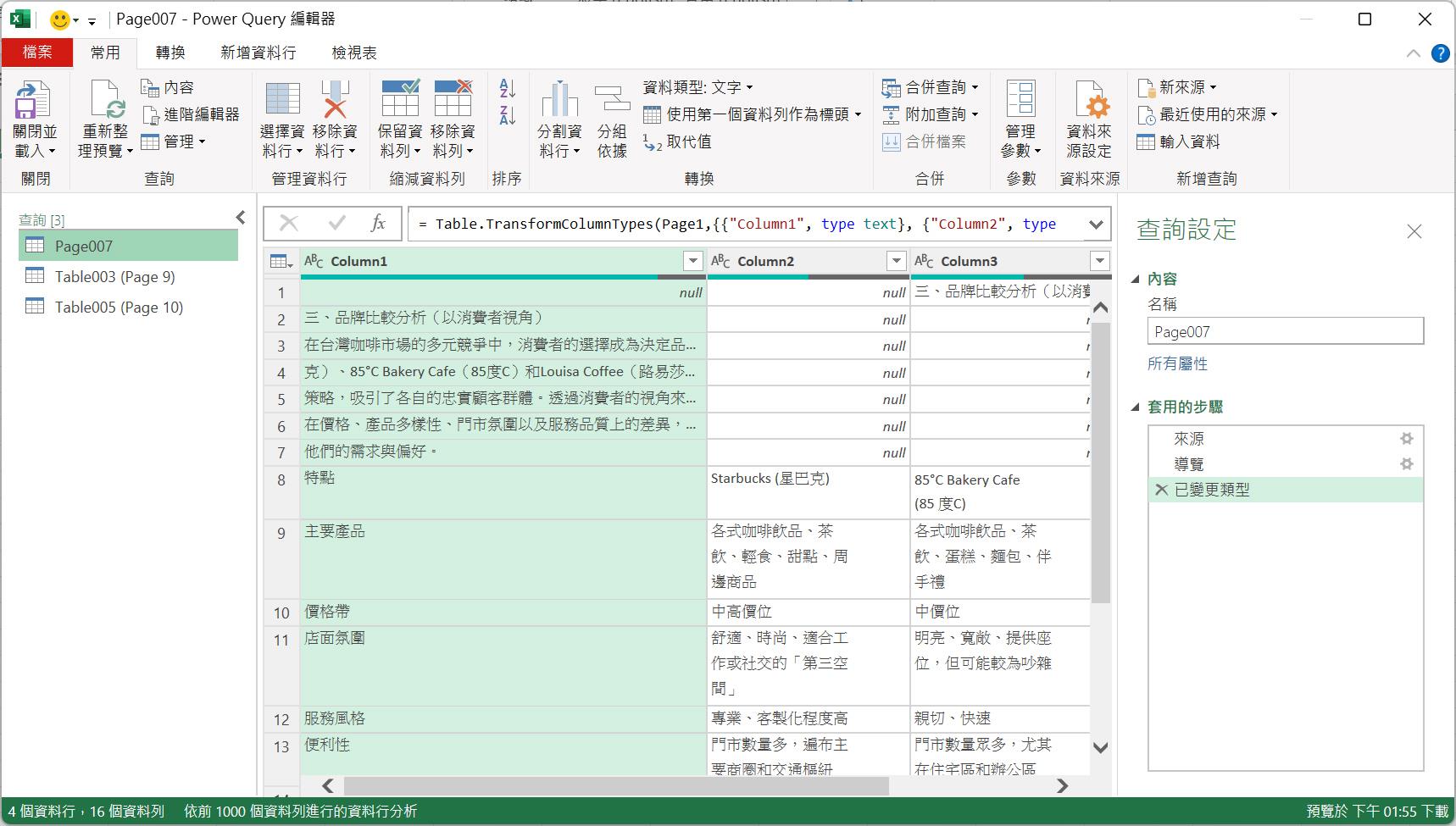
由於前7列資料室標題文字以及段落敘述,所以可以將其移除。此時可以點按[常用]索引標籤,然後,點按[移除資料列]命令按鈕後從展開的功能選單裡點選[移除頂端資料列]功能選項,開啟[移除頂端資料列]對話方塊後,輸入資料列數目為7,再按下[確定]按鈕。
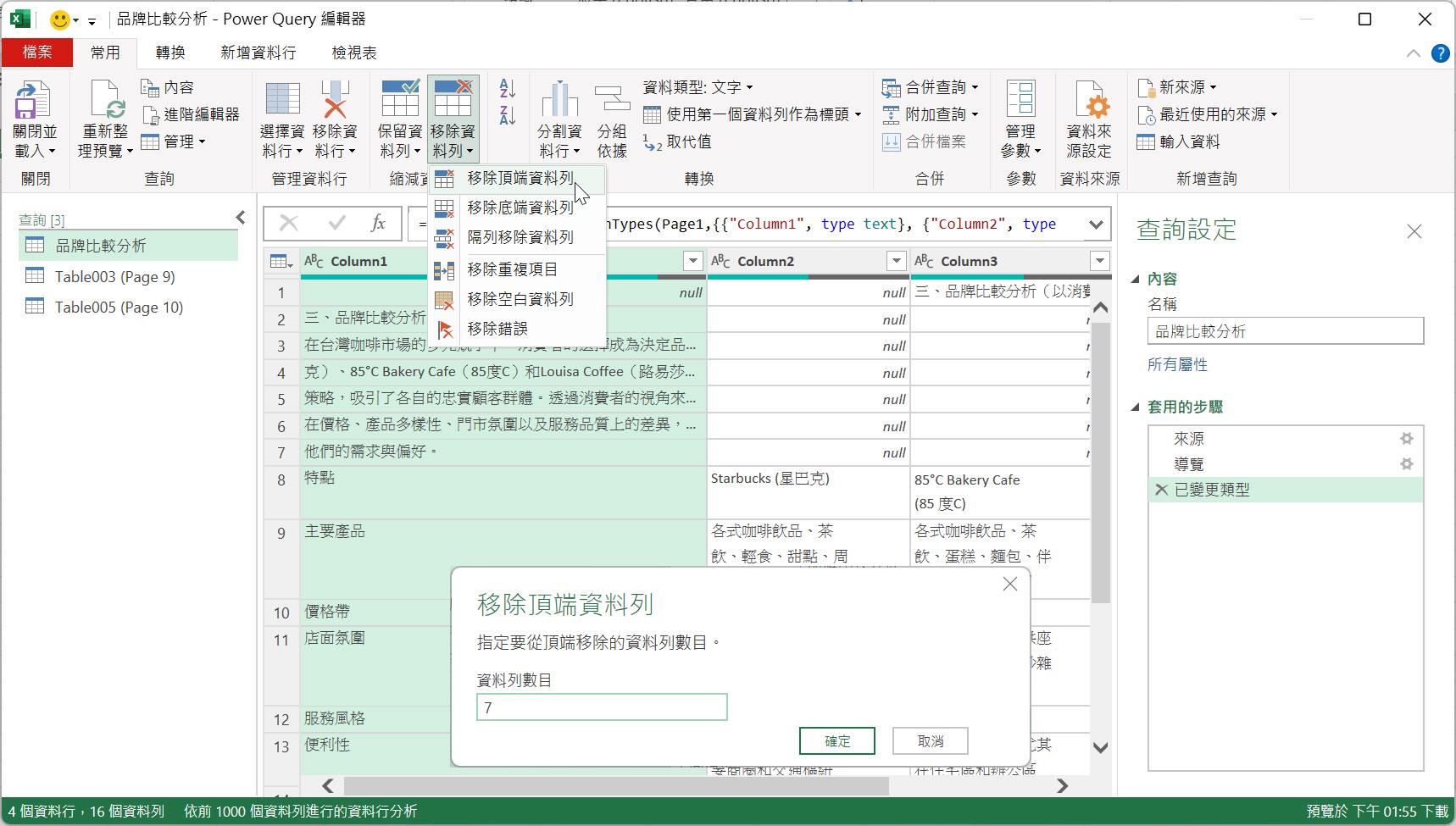
最後可以將當下的首列升級為資料表的資料行名稱,以取代目前的Column1、Column2、Column3等預設的資料行名稱。
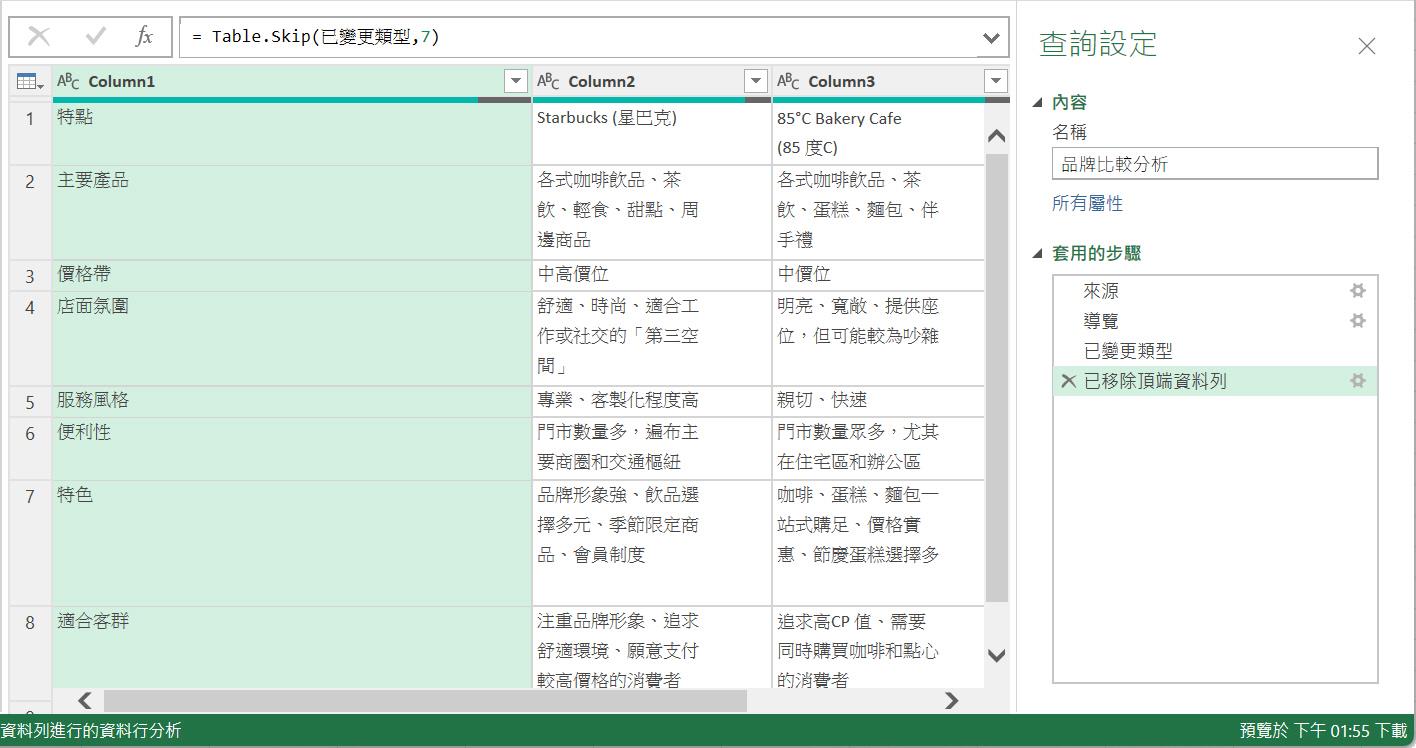
當然,要想成一個好習慣,當完成一個查詢的建立後,就要為這個查詢結果命名較有意義與容易識別的查詢名稱。例如:[品牌比較分析]。
接著,開始處理第2個查詢,這是來自Table003(Page9)的資料來源,描述著三個品牌咖啡連鎖店的品牌優勢及改進面向,這已經是一個很完美的表格解析了,就差一步要將資料表的首列升級為資料表的資料行名稱,以取代目前的Column1、Column2、Column3等預設的資料行名稱。
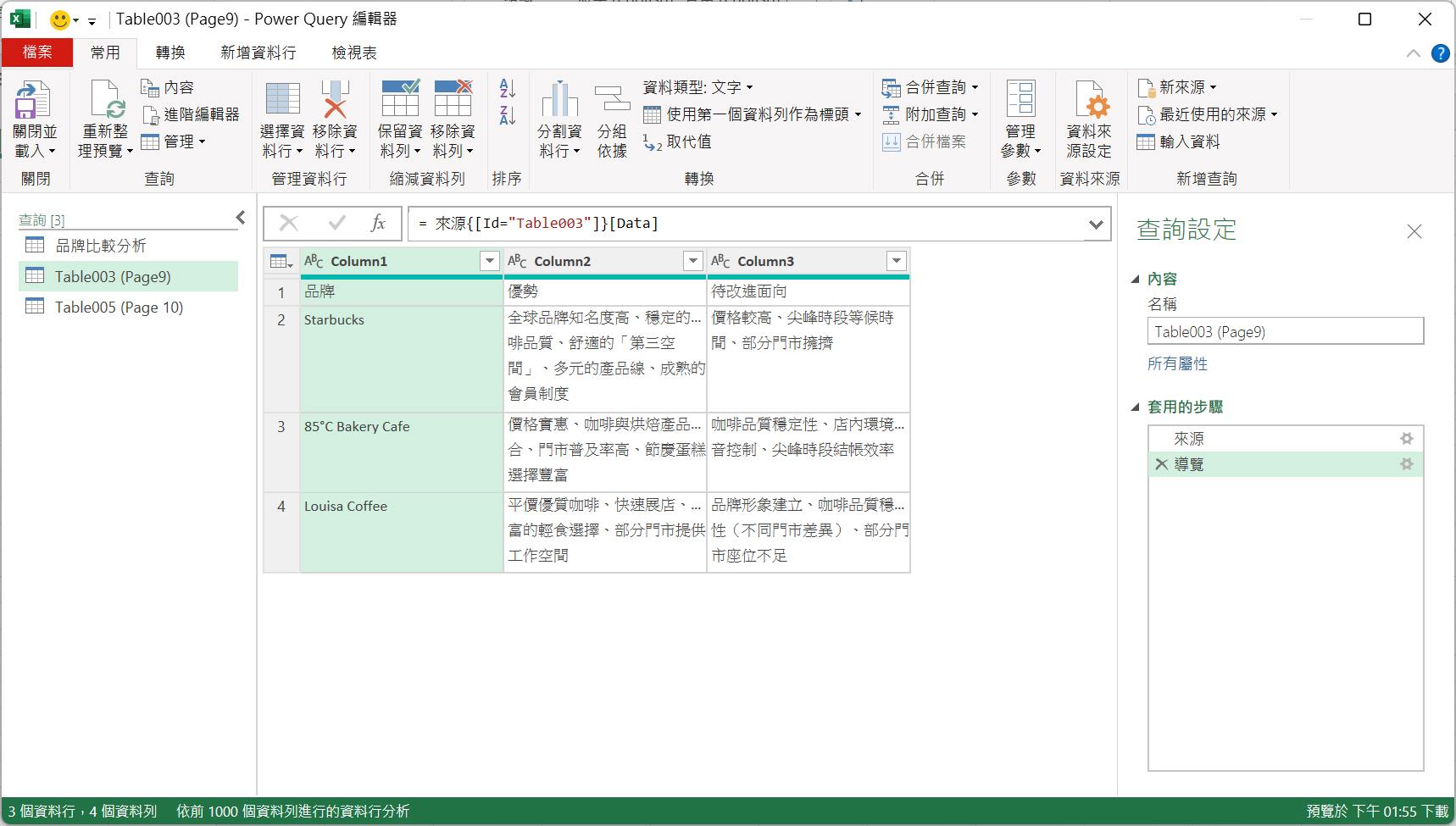
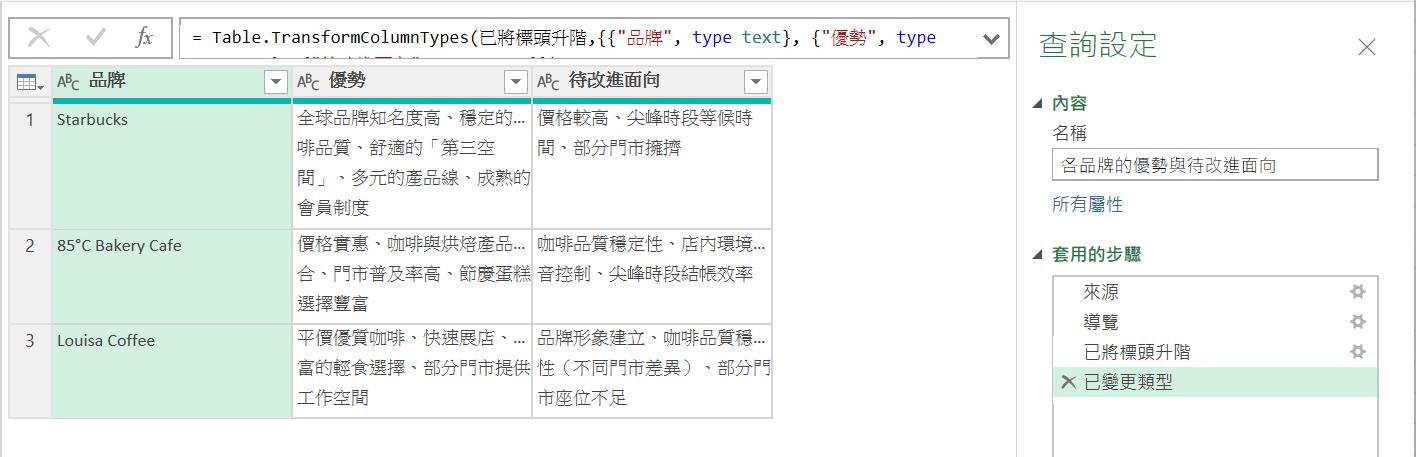
完成後,也將此查詢結果重新命名較有意義與容易識別的查詢名稱。例如:[各品牌的優勢與待改進面向]。
最後來到最後一個查詢來源囉!這個預設名為Table005(Page10)的查詢,描述著三大咖啡連鎖店在各縣市的家數與密度。這次的解析更精準,連資料行名稱都很符合需求。
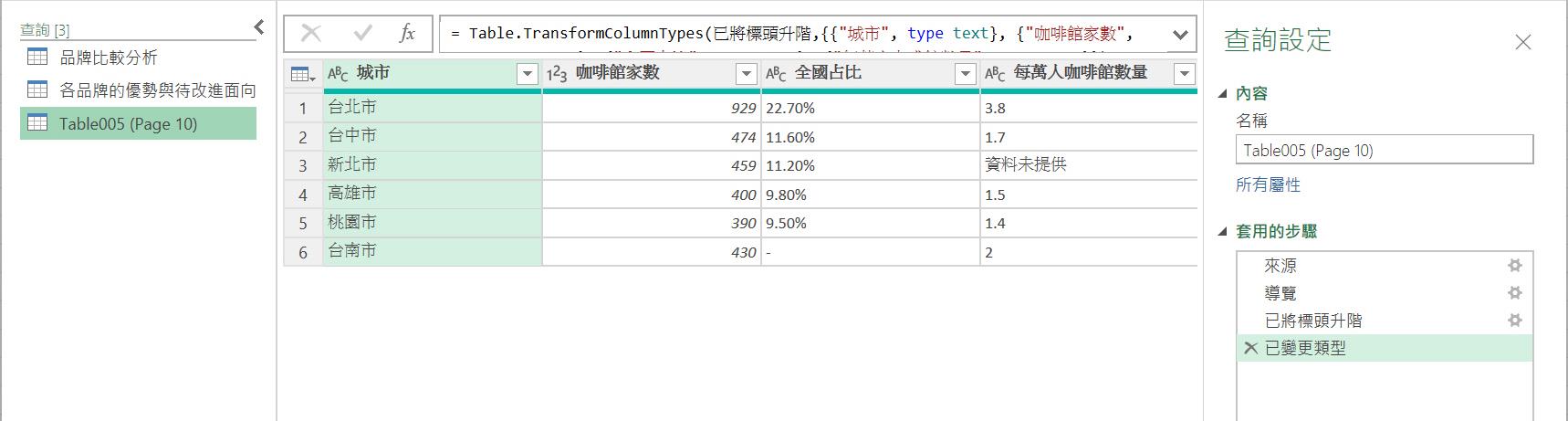
可以重新設定此查詢結果的名稱為[各城市咖啡連鎖店家數與密度]。
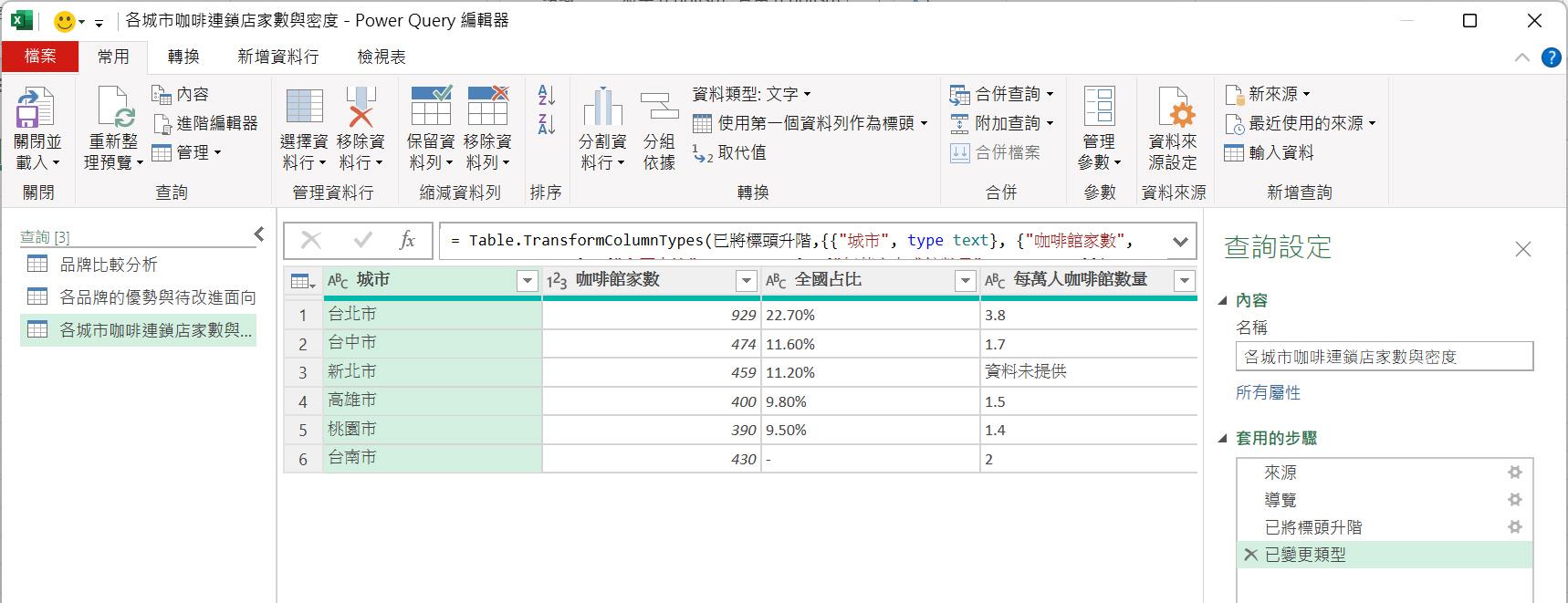
完成所有的查詢建置與轉換後,點按[常用]索引標籤裡的[關閉並載入]命令按鈕,便可以將這三個查詢結果輸出成為三張Excel工作表上的資料表。
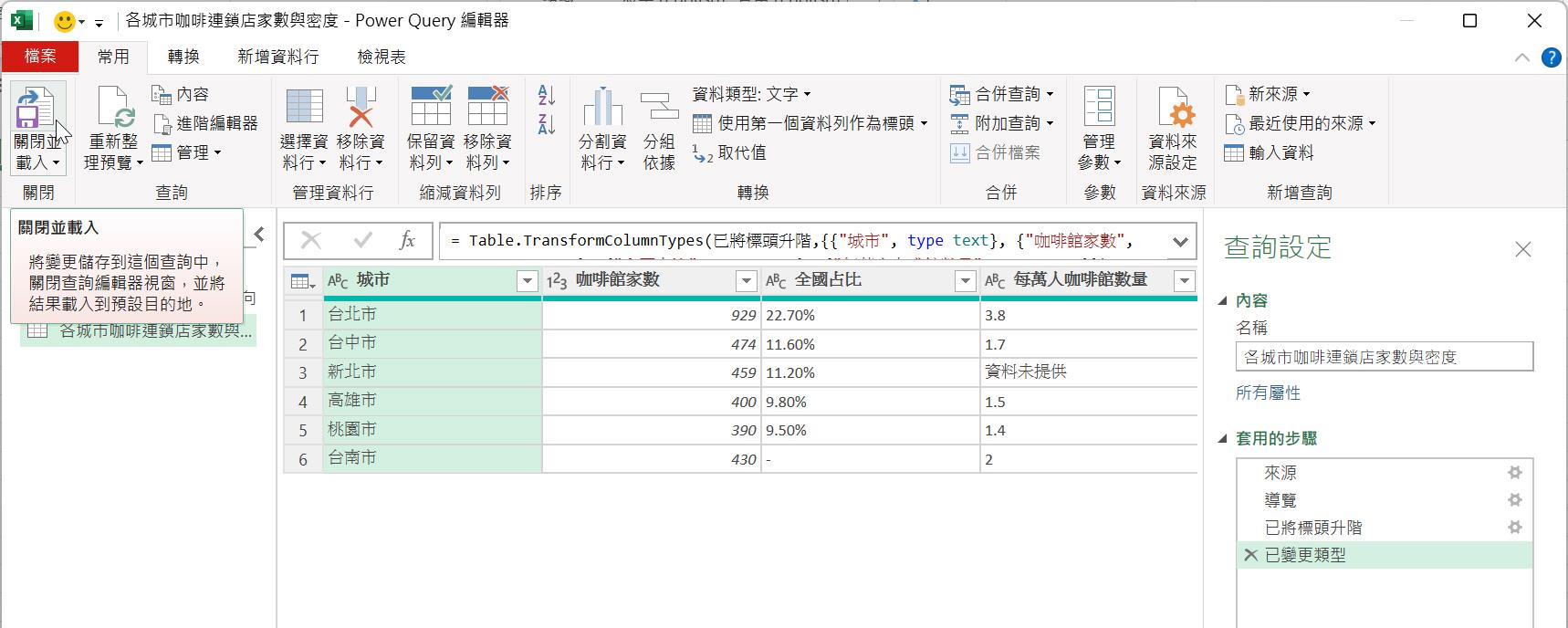
來自PDF檔案解析後所擷取的三份資料表就可供您使喚與運用了。
第二個範例
接著就為您實際演練另一個PDF檔案匯入與解析的情境。檔案名稱為 - 全泉科技外聘講師業務所得清單.pdf,總共有20頁。此檔案描述著2025年第一季的外聘講師業務所得清單,每一個月份都是結構相同的表格資料,但表格有標題以及跨頁的情形。
此次的練習我們想要萃取出第8頁到第13頁的內容,也就是2月份的完整資料。
在匯入這份PDF檔案後,隨即進入導覽畫面,Power Query解析出這份PDF文件裡包含了許多可以解讀的分頁(Page)與表格(Table)。這次我們將點選代表整個PDF檔案的資料夾圖示與檔案名稱(並不是逐一勾選所要的頁面喔!),然後點按[轉換資料]按鈕。
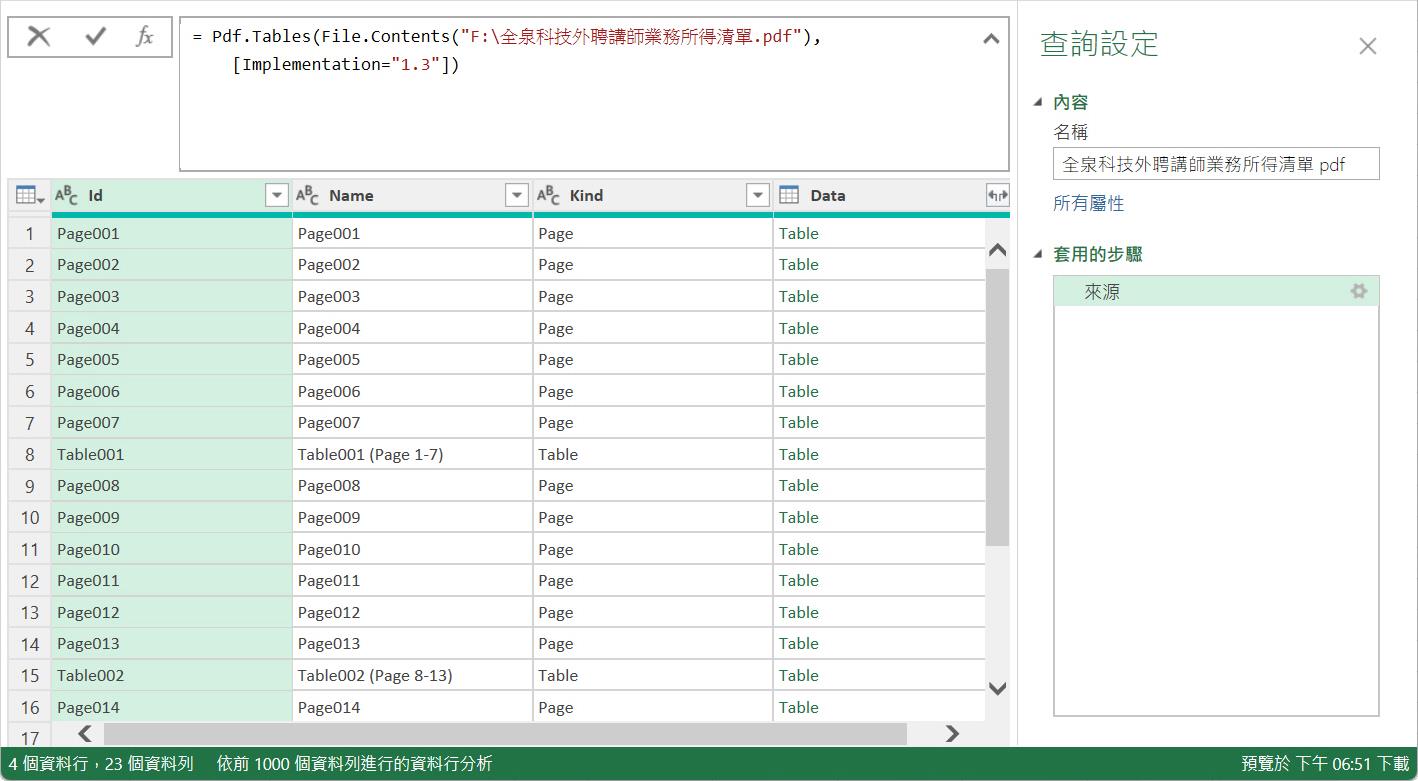
隨即開啟Power Query編輯器,立即看到每一個解析的頁面與表格的資料屬性。而僅有的這一行程式碼即為Pdf.Tables()函數與File.Contents()函數:
= Pdf.Tables(File.Contents("F:\全泉科技外聘講師業務所得清單.pdf"),
[Implementation="1.3"])
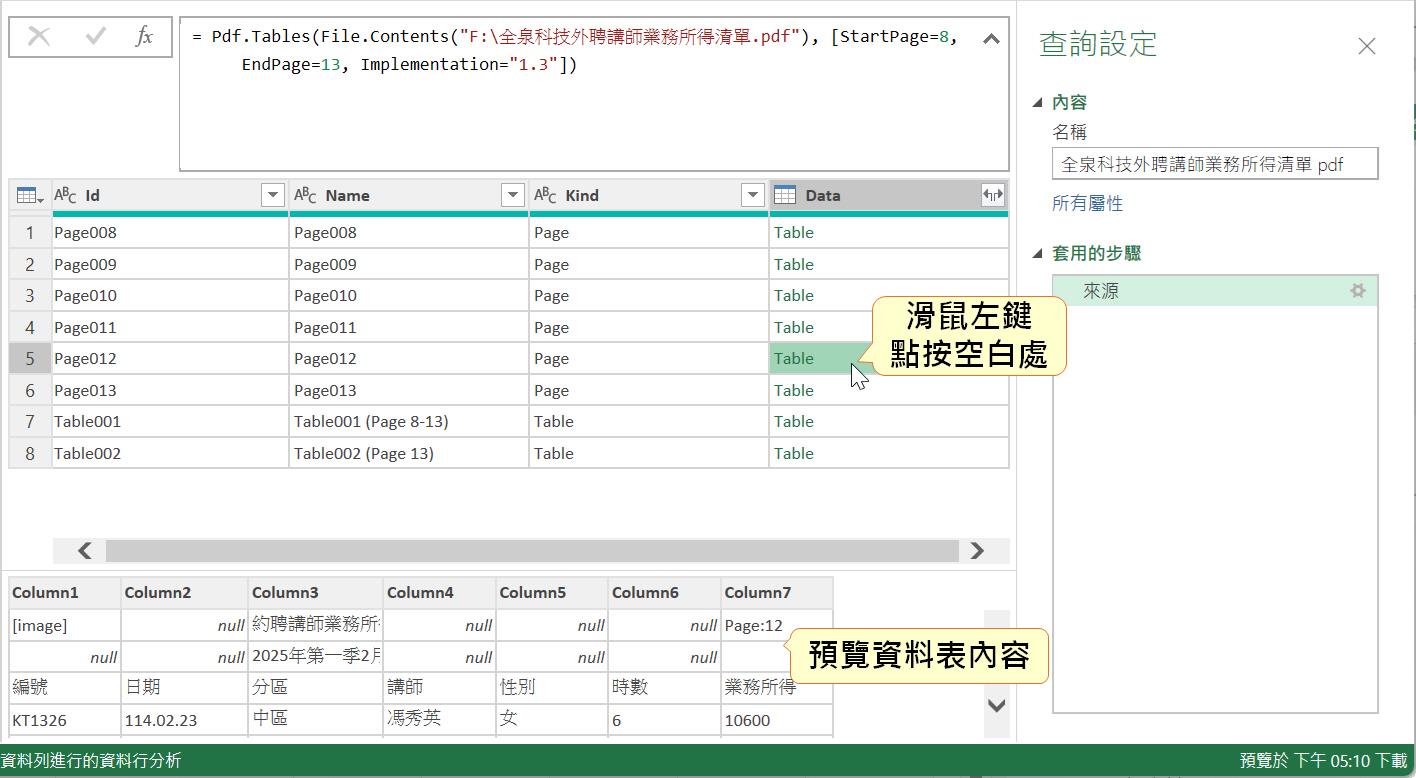
由於我們僅是需要解Power Query擷取正分PDF檔案裡的第8到第13頁的內容,因此,我們可以直接在公式列上修改M語言程式碼,改成:
= Pdf.Tables(File.Contents("F:\全泉科技外聘講師業務所得清單.pdf"),
[StartPage=8, EndPage=13, Implementation="1.3"])
指定查詢結果僅限於PDF檔案裡的第8到第13頁的內容,而這份查詢輸出結果解析了頁面與表格的資料屬性。這是包含了[id]、[Name]、[Kind]、[Data]等4個資料行的查詢結果資料表。這些資料行都有著特定的意義:
1. id
這是唯一識別碼,用於標識每一列的資料。例如,PDF檔案中的每個表格或每個頁面可能會分配一個ID,以區分來源的不同。
2. Name
此資料行通常用來顯示來源的名稱。例如,若PDF檔案中包含數個頁面、數個表格,在此資料行便會顯示每個頁面名稱、表格名稱,或者與這些頁面或表格相關的描述性資訊。
3. Kind
此資料行描述每一列記錄的資料內容之類型或種類。譬如:整頁內容是隸屬於page資料類型;若是屬於結構化資料表格就是Table資料類型。
4. Data
正如資料行名稱所述,此資料行正是每一列資料類型的實質內容,對於Kind隸屬於Page資料類型的內容就是整個頁面裡的資料;對於Kind是隸屬於Table資料類型的內容就是內嵌的資料表(表格物件),有時候一個頁面可能會存在再不只一個以上的小表格,Power Query都會一一解析出來。如果需要進一步預覽資料內容,可以點按儲存格裡綠色Table文字以外的空白處(切記,不是直接點按資料行裡的綠色Table喔!)。
瞭解了這次的需求後,點按一下[Name]資料行的篩選按鈕,從中僅勾選[Table001(Page 8-13)]選項。
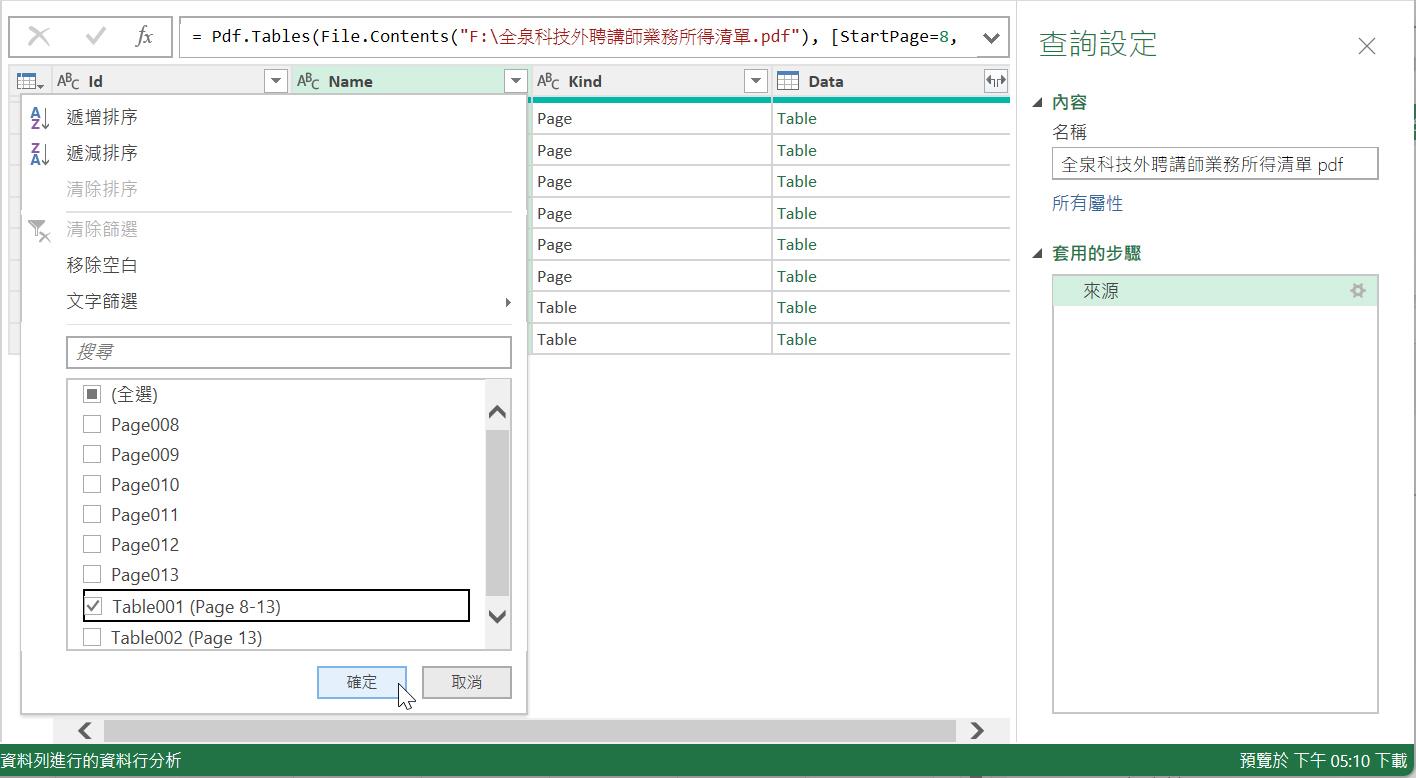
篩選的結果將是留下8-13頁的頁面之解析結果,也就是將這份連續6頁的PDF內容萃取出資料表格的查詢結果。而這份資料表則僅需保留[Data]資料行即可。因此,可以在點選該資料行後,透過【移除其他資料行】的功能操作達到目的。
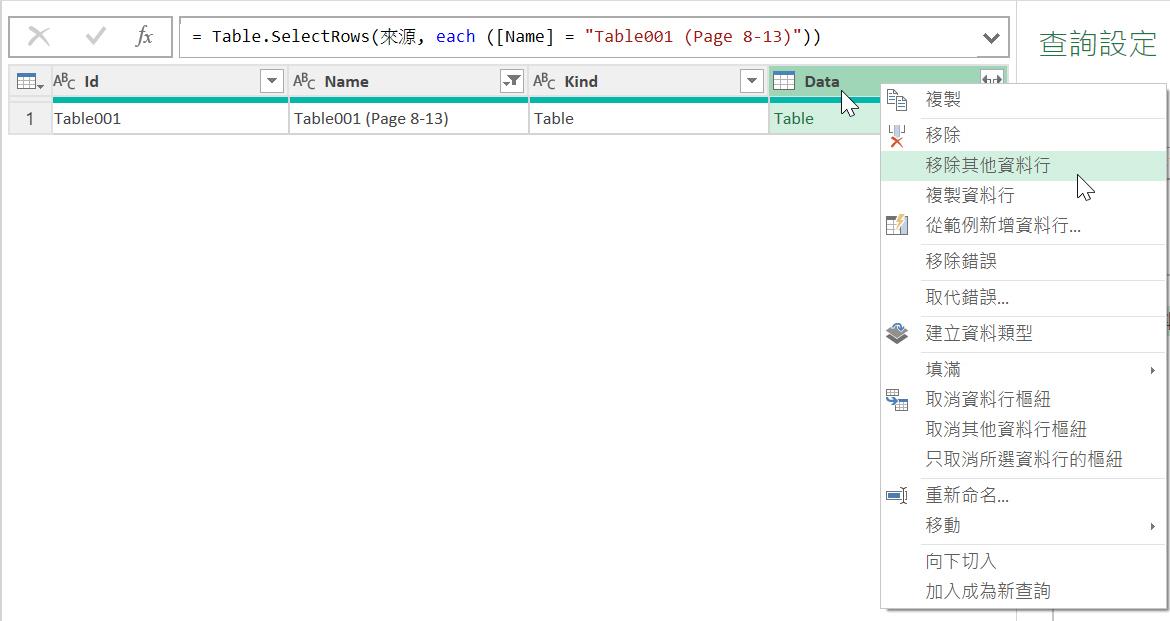
這個移除其他資料行的M語言程式碼其實也不是甚麼特別函數,就是單純的Table.SelectColumns(),也就是選取指定的資料行:
= Table.SelectColumns(已篩選資料列,{"Data"})
接著,點按僅存留下來的[Data]資料行之展開按鈕。
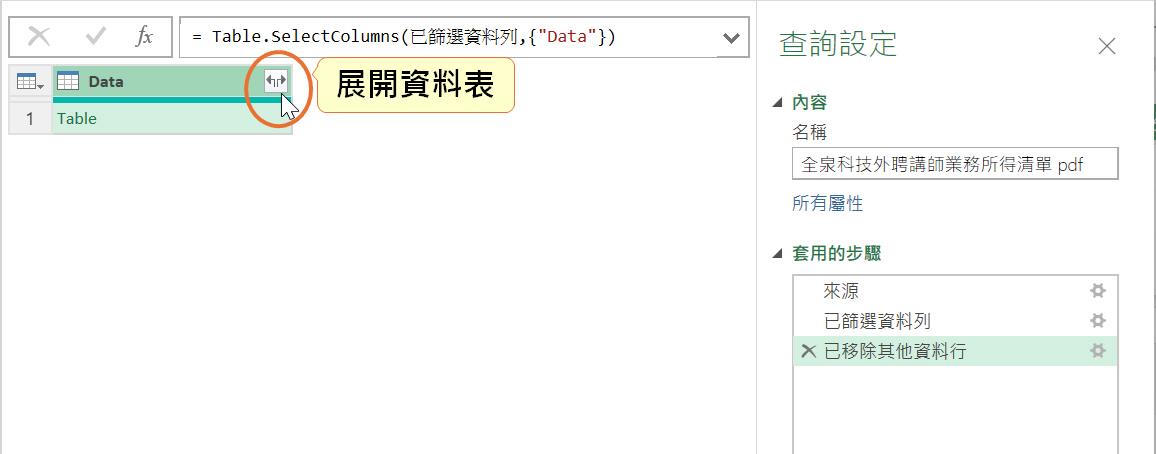
然後,在展開的下拉式選單中,取消[使用原始資料行名稱做為前置詞]核取方塊的勾選。
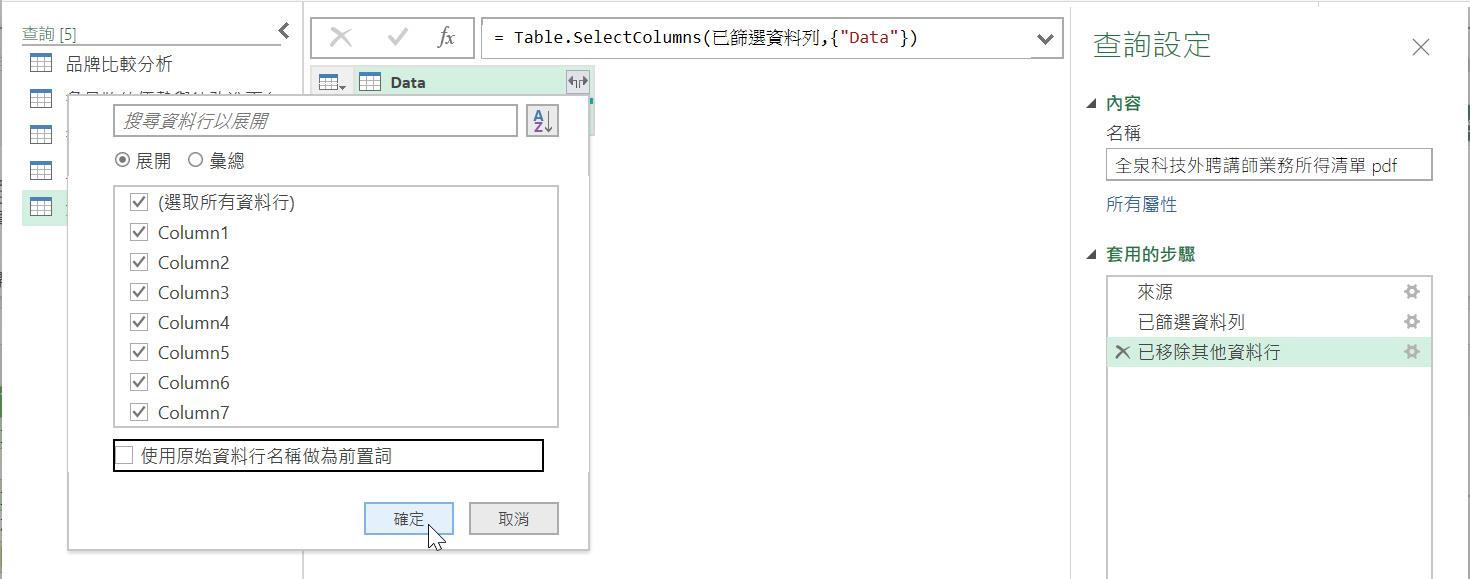
這個展開內容為資料表的資料行之操作過程,是藉由Table.ExpandTableColumn()函數來完成,以此例而言,M語言程式碼如下:
= Table.ExpandTableColumn(已移除其他資料行, "Data", {"Column1", "Column2", "Column3", "Column4", "Column5", "Column6", "Column7"}, {"Column1", "Column2", "Column3", "Column4", "Column5", "Column6", "Column7"})
分散在各頁面的同一資料表格就彙整起來了,此時便可以點按[常用]索引標籤裡的[使用第一個資料列做為標頭]命令按鈕,將查詢結果的首列升級為真正的資料行名稱。也就是先前我們曾經學習過的Table.PromoteHeaders()函數。
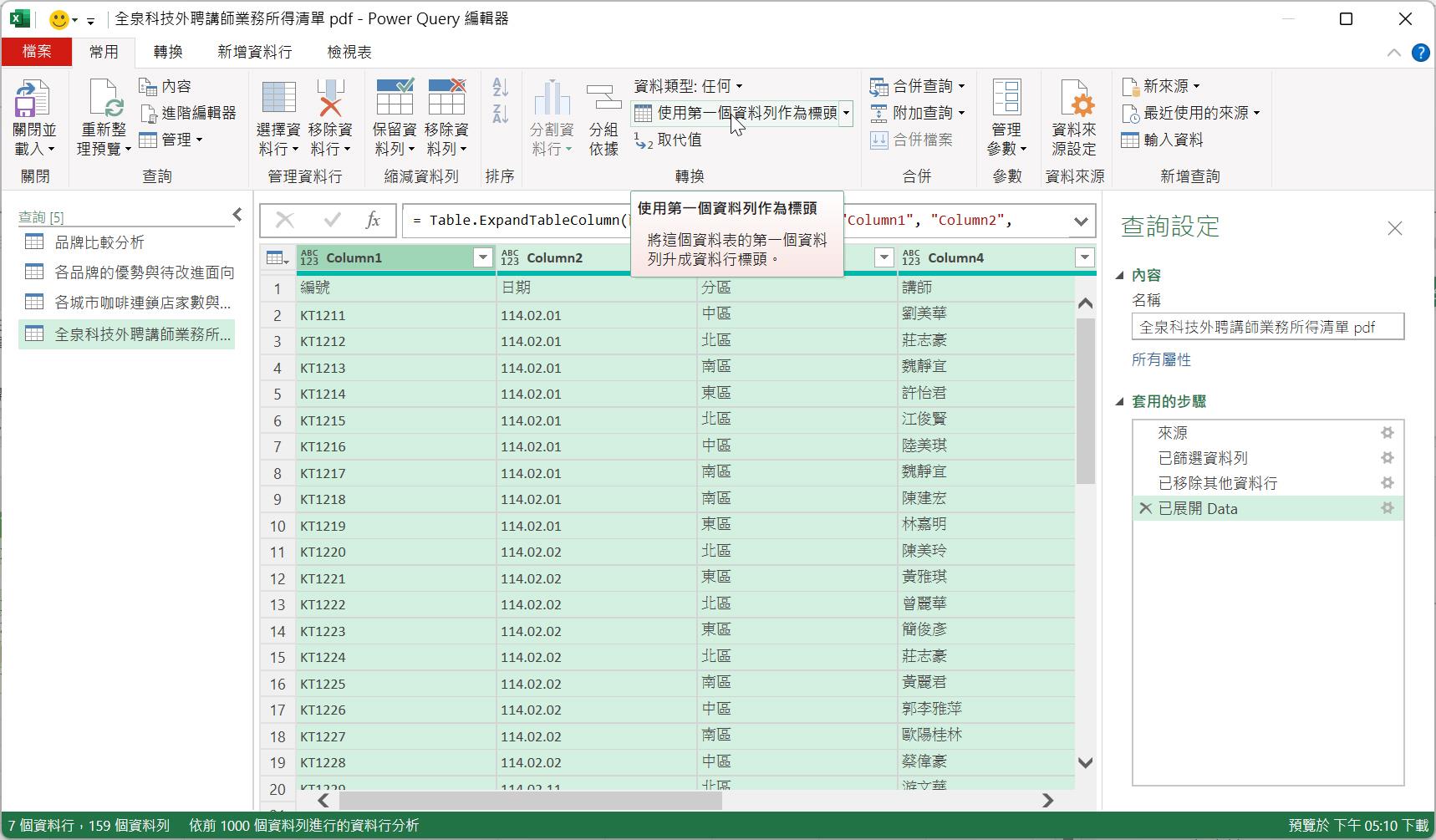
最後,可以將此查詢結果重新命名為較符合意義,也較易理解的查詢名稱。例如:「二月份外聘講師業務所得」。完成的查詢結果將形成一張包含158筆資料紀錄的資料表。藉由[檔案]索引標籤裡的[關閉並載入]命令按鈕。,
查詢結果便以資料表的型態輸出至Excel的空白工作表上,而此工作表的名稱即預設為當初設定的查詢名稱「二月份外聘講師業務所得」。
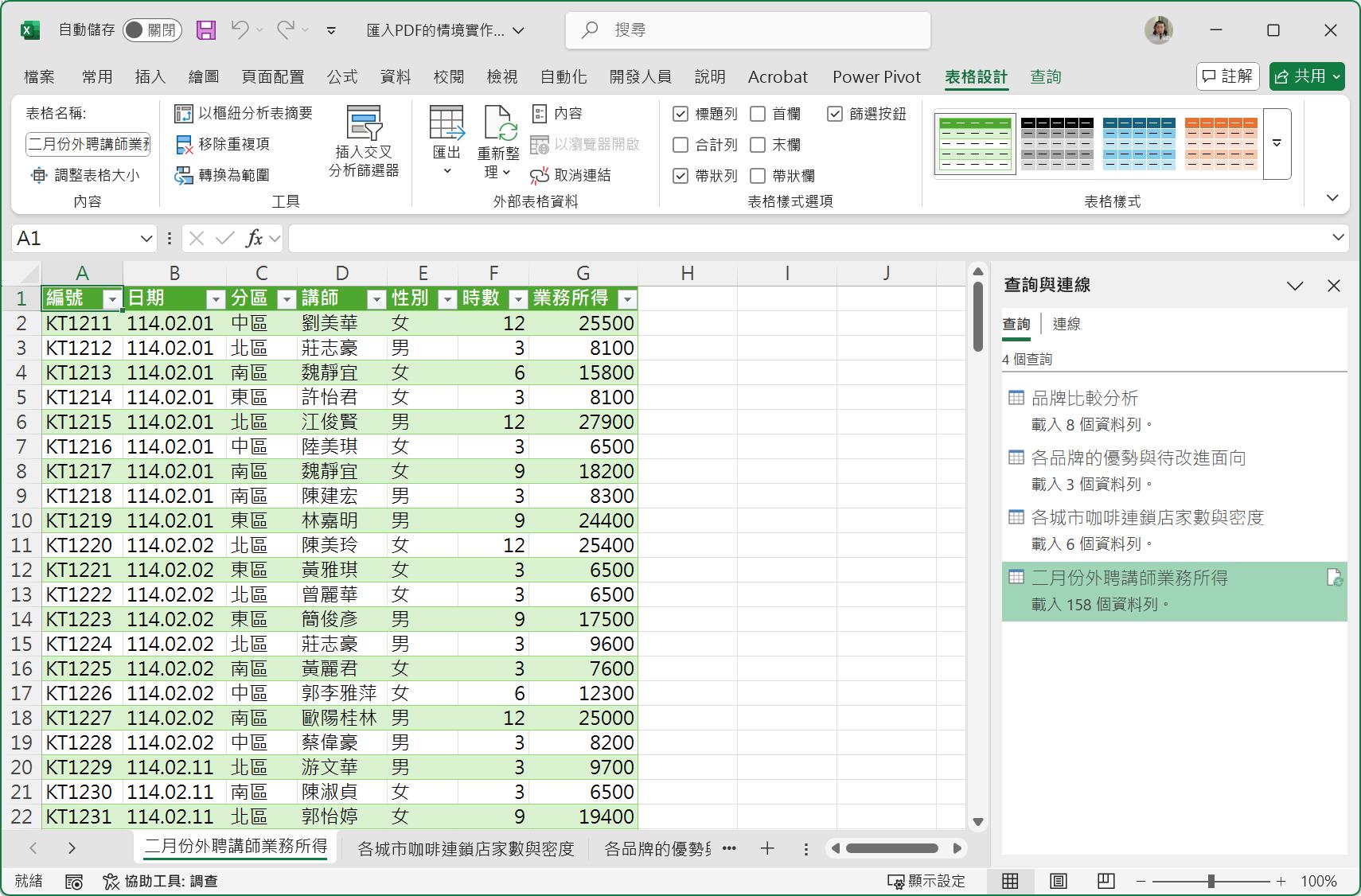
此番匯入PDF指定頁面的完成程式碼如下所示:
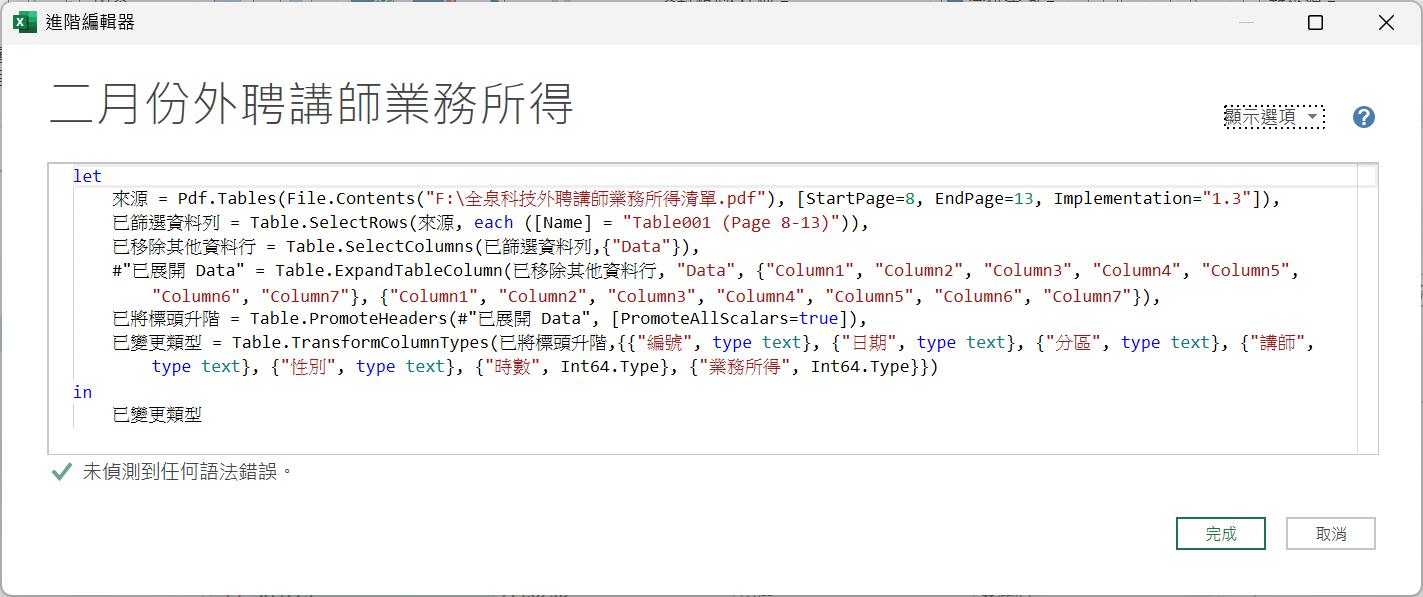
最重要的便是第一個步驟入,匯入PDF檔案的Pdf.Tables()函數,以及其中的參數變化。
