從前面的系列文章分享中,相信已經在函數的運用領域,幫大家打下了很好的基礎。接著,我們就邁入在Power Query領域裡函數議題與學習。首先為大家詳細介紹並實作Power Query內建函數的運作,對函數進行導讀與學習。
為什麼這一篇文章要說是Power Query內建函數的導讀呢?因為,Power Query是一套ETL工具,可以協助使用者匯入外部資料並整理資料,而產生有用的RAWDATA。這一切的過程都是功能選單與指令操作居多,而完成這些過程的主角,便是M語言與其內建函數,也就是說,M語言是一種函數式的語言,使用者在操作的過程中完全不需要親自撰寫,但可以修改、刪除、添增這些內建函數,因此,即便不需要無中生有的撰寫它,但總是要學看懂它,才能靈活的掌控它。
以下就以常見的各種外部檔案格式,諸如:csv、json、xml與PDF檔案格式,來為大家解讀匯入這些外部資料來源的檔案時,M語言的程式碼與內建函數各有甚麼不同。但要先讓各位明白的是,基於資料來源的檔案架構與規範略有不同,在使用Power Query匯入外部資料時也會略有差異。譬如:即便是同屬於XML檔案格式的資料,也會因為是否含有結構定義檔,而匯入過程的步驟與解析經歷是不會一樣的(可參考作者匯入XML檔案體驗Power Query的魅力系列文章)。所以,本文實作截圖或許與您實際工作的案例略有不同,請自行判別與演練。
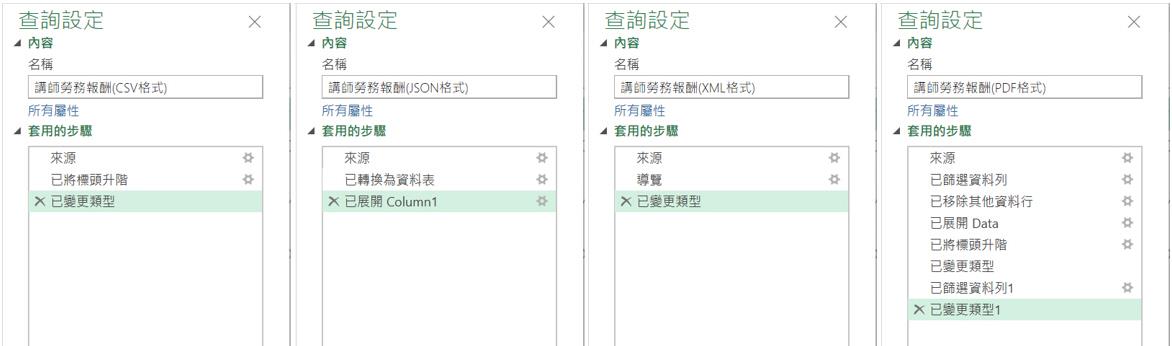
匯入csv檔案
其特性是純文字格式,欄位由分隔符(通常是逗號)分隔,是屬於輕量且易於處理,適合儲存結構化平面資料。常被廣泛應用於資料匯出和匯入。不過CSV檔案並無層次結構,僅適合簡單表格資料,也無法儲存諸如資料類型、欄位描述等元數據(Metadata)。如下便是典型的csv檔案格式:
在進行資料匯入與轉換時,這類型的檔案格式必須確保分隔符號一致(例如逗號、分號或制表符)。在儲存特殊字符(如引號或斜線)和空白欄位時也要有特殊的處理,亦要進行文字編碼(如UTF-8)的核對,避免產生亂碼問題。
Csv.Document()函數
在此範例中透過Power Query操作匯入csv檔案時,會執行3個操作步驟:
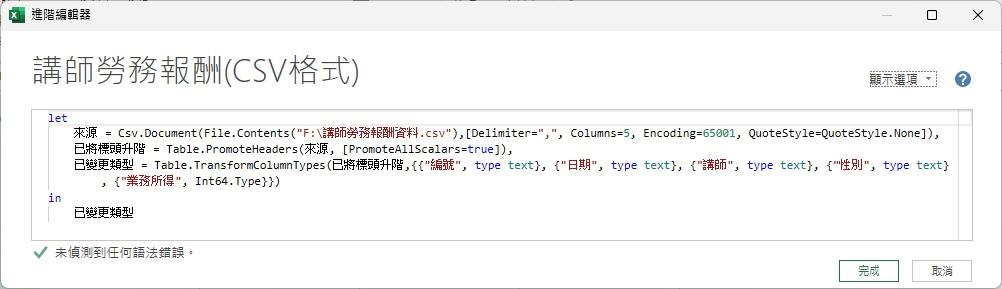
其中,第1個操作步驟便是Csv.Document()函數。

Csv.Document( )是Power Query的內建函數,其目的是讀取以逗點為分隔符號的文字檔案。函數裡的第1個參數是描述要讀取的csv檔案之完整路徑與檔案名稱,常在此搭配另一個內建函數File.Contents( ) 。
從File.Contents("F:\講師勞務報酬資料.csv")的描述,也很容易解讀該csv資料檔案的檔案名稱為「講師勞務報酬資料.csv」,並儲存在硬碟F裡。至於Csv.Document( )函數的第2個參數是可選用的參數,此參數是屬於記錄 (Record) 資料形態(在Power Query的容器表達式中,是以一對中括號[...]代表記錄型態的資料),用來指定 CSV 檔案的解析選項。其中包含了Delimiter 、Columns、Encoding、 QuoteStyle等欄位:
- Delimiter欄位,Delimiter="," 則表示這個欄位指定了 CSV 檔案中各個欄位之間的分隔符號為逗號 (,)。這是 CSV 檔案最常見的分隔符號。
- Columns 欄位,Columns=5 則表示預期 CSV 檔案中包含的欄位 (資料行) 數量為 5。Power Query 會根據這個設定來解析資料。
- Encoding欄位,Encoding=65001 這將表示此CSV 檔案的字元編碼格式為 65001,代表這是 UTF-8 編碼。UTF-8 是一種通用的字元編碼,可以支援各種語言的文字,包括中文。
- QuoteStyle欄位,QuoteStyle=QuoteStyle.None,在此表示解析 CSV 檔案時如何處理引號。QuoteStyle.None 表示不使用任何引號樣式。這意味著 Power Query 不會將雙引號或其他引號視為特殊字元來包圍欄位值。如果您的 CSV 檔案中包含可能需要引號包圍的欄位(例如,包含逗號或換行符號的文字),則這個設定可能需要調整。
Table.PromoteHeaders()函數
透過此函數匯入外部資料後,再藉由第2個查詢步驟Table.PromoteHeaders()函數,將資料檔案的第一列內容升格為資料行的標頭,也就是資料行名稱(資料欄位名稱)。根據預設,只有文字或數值會升階為標頭。

PromoteAllScalars參數也是屬於記錄(Record)容器的資料型態,因此其外圍會有一對對中括號,而此記錄內容裡包含了一個名為PromoteAllScalars的欄位,此欄位是屬於邏輯資料型態的布林值(Boolean),因此,其值不是True就是False,而其功能決定了是否要將所有純量值(scalar values)視為可以成為資料行名稱的內容。
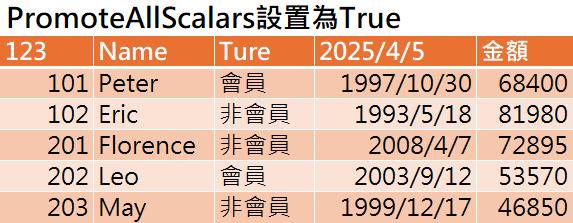
- 在預設狀態下,此參數的值為False,這意味著資料來源第一個資料列的內容,只有可做為有效欄位名稱的文字型態內容,才會升階為資料行名稱,至於不是文字型態或者無法轉換成文字性型態的值,譬如:數字、日期、邏輯值等資料,就會產生錯誤或者自動產生Column1、Column2、…等預設的資料行名稱。
- 如果將PromoteAllScalars設置為True,則即使資料來源第一個資料列的內容是數值或其他類型的純量值(諸如日期、布林值)也可以被提升為資料行名稱。
例如:若資料來源是:
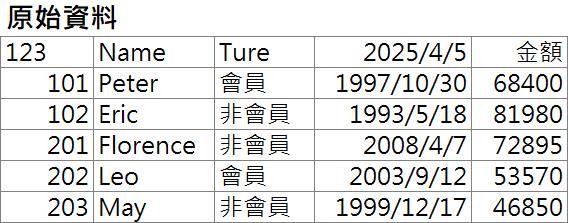
Table.PromoteHeaders()函數的參數PromoteAllScalars設為True時,輸出結果為:
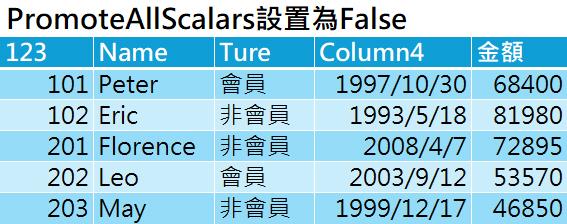
Table.PromoteHeaders()函數的參數PromoteAllScalars設為False時,輸出結果為:
什麼是純量值 (Scalar Values)
在這裡所謂的「純量值」通常指的是簡單的單一值、不可再分解的基本數據類型,例如文字、數字、日期、邏輯值與null等等。而複雜的結構化值(諸如 List、Record或Table等容器)則不算是純量值,通常不會被提升為標題。
Table.TransformColumnTypes()函數
接著,我們再來聊聊另一個在操作Power Query時的常見函數,那就是Table.TransformColumnTypes()函數。在進行資料的匯入、轉換等作業時,Power Query常常會主動執行此函數,試圖調整出最理想的資料型態。此函數的基本格式為:

第1個參數是資料表型態的資料來源,第2個參數是清單(List)型態的轉換清單,所以外圍會有一對大括號,裡面又是一組組的清單,描述著資料行名稱,以及要設定的資料型態。譬如若此參數如此撰寫:
{{"工號", type text}, {"雇用日期", type date}, {"獎金", Int64.Type}}
即表示要將「工號」資料行設定為文字型態;要將「雇用日期」資料行設定為日期型態;要將「獎金」資料行設定為整數型態。
綜觀在操作Power Query匯入外部資料檔案的型態若為csv檔案時,依序便是執行這3個查詢步驟,透過:
- Csv.Document()
- File.Contents()
- Table.PromoteHeaders()
- Table.TransformColumnTypes()
等M語言的內建函數來完成。