在關聯式資料庫系統中,常聽到「基元值」(Atomic Value)這個專有名詞,許多非資訊背景的工作者,常有不知所措、不易理解的窘境。在此就以Excel處理資料,轉換資料的概念,為大家說明與實作。
前言
我們常會使用Excel工作表行列交錯的特性,進行資料的建置與編輯,例如:以下的資料即是在工作表上建立了一個員工專長背景的資料表。在實質的運作上,每一位員工的專長可能不止一項,因此,在「專長」欄位裡的儲存格內容便登錄了多項以上的專長,並以頓號作為分隔符號,這份資料表達既自然且明確,又容易閱讀與理解,不過嚴格來說,這並非結構化的RAW DATA,它僅是一份報表表格(Report Table),並不是關聯式資料庫眼中的結構化資料表(Data Table)。您也可以試想,若要理解有多少位員工懂得日文?或者想篩選出有哪些員工同時具備"資料分析" 與 "日文" 這兩項專長?這份非結構化的資料表,並不容易一下子就可以操作得出來喔!
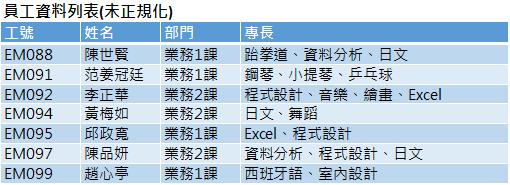
在資料電腦化的過程中必須按照特定的規則對原始資料進行整理、分析、重整、切割、…這個資料轉換過程即稱之為資料表的正規化(Normalization)作業。而在關聯式資料庫的資料表正規化中,對於資料表的諸多要求與規範中,就有一項「基元值」(Atomic Value)的特性,也就是在行列交錯的儲存格裡必須儲存"不可再分割的值",吾人稱之為基元值(Atomic Value)或稱為Scalars標量。通俗易懂的說法就是資料欄位的儲存格內容,是否都只儲存一個資料項目。以前述的員工專長背景資料表為例,就是「專長」欄位裡的每一個儲存格,僅能存放一個不會再細分的項目資料(一項專長),才稱得上是結構化的資料表。因此,我們可以將「專長」欄位裡的內容進行轉換,每一個專長項目獨立存放在單一的儲存格裡,以確認每一個儲存格都是不能再細分的「基元值」(Atomic Value)。

當然,這勢必也讓資料表的資料筆數(資料記錄)暴增,且重複性的資料也大增,例如:「工號」、「姓名」與「部門」等三個資料欄位的內容就產生了太多重複性。但不可諱言,這的確是一個容易設定關聯、統計運算的結構化資料表。例如:針對「專長」資料欄位,您很容易利用Microsoft 365的Excel 365所提供的UNIQUE函數,建立一份不含重複項目的專長列表,也可以利用Excel的Countif函數統計出各種專長項目的個數。但問題的癥結就在於對上述未結構化的資料,要將「專長」欄位轉換成符合基元值(Atomic Value)特性的結構化資料表,只能苦力式剪剪貼貼、複製貼上嗎?當然不是,這也正是Power Query擅長的基本功喔!
我們就開始這非結構化資料轉換成結構化資料表的旅行囉!首先,請先下載這個實作範例檔案。開啟這個範例活頁簿後,裡面包含了已經事先設定為Excel資料表格式,且名稱為[員工專長清單]的資料表。
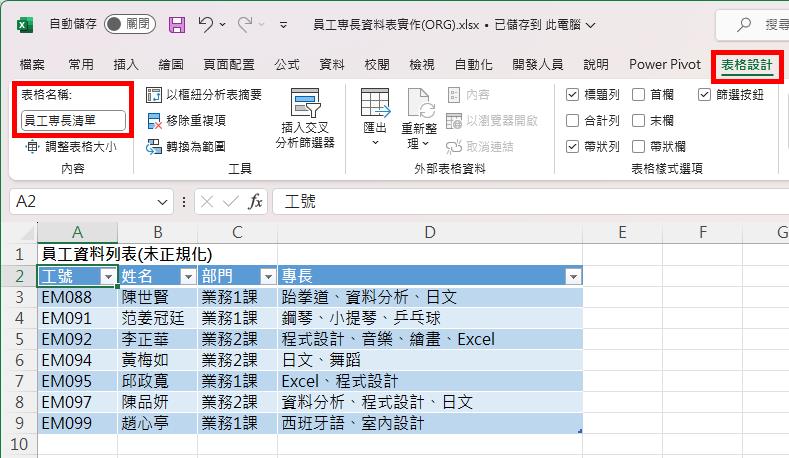
然後,點按[資料]索引標籤裡的[從表格/範圍]命令按鈕,將此份資料傳送到Power Query查詢編輯器。
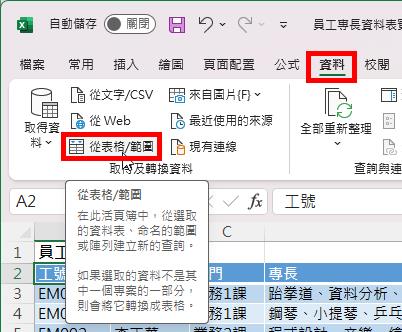
開啟Power Query查詢編輯器後,點選[專長]資料行,然後,點按[常用]索引標籤裡的[分割資料行]命令按鈕,再從展開的功能選單中點選[依分隔符號]功能選項。
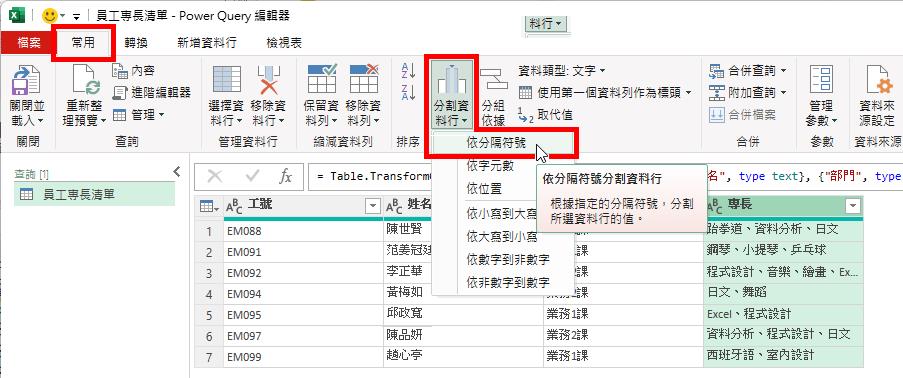
隨即開啟[依分隔符號分割資料行]對話方塊,Power Query自動識別並預設此資料行的分隔符號為頓號,而分割處預設為[每個出現的分隔符號]選項。
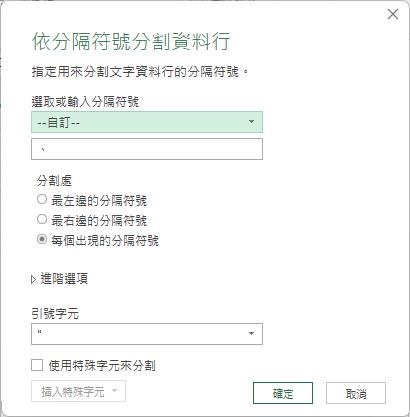
分割成功後,此例分割出5個資料行,表示每一位員工最多登錄的專長項目是5項,而這5個資料行的內容都僅有一個值,或是null(空值),也正是結構化資料表中的基元值(Atomic Value)特性了。此時,我們就同時選取這5個專長資料行,以滑鼠右鍵點選其中一個資料行的資料行名稱後,即可從展開的快顯功能表中點選[取消資料行樞紐]功能選項。
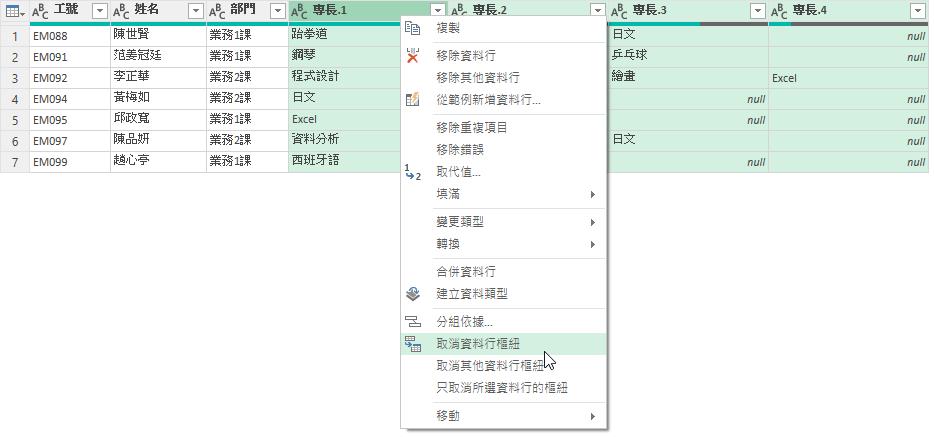
隨即可以看到剛剛選取的多個專長資料行,立即轉換成[屬性]與[值]這兩個資料行。其中,[值]資料行的內容便是每一位員工的每一項專長,逐列顯示在資料表裡,而[屬性]資料行在此並沒有甚麼用途,我們可以將其刪除。
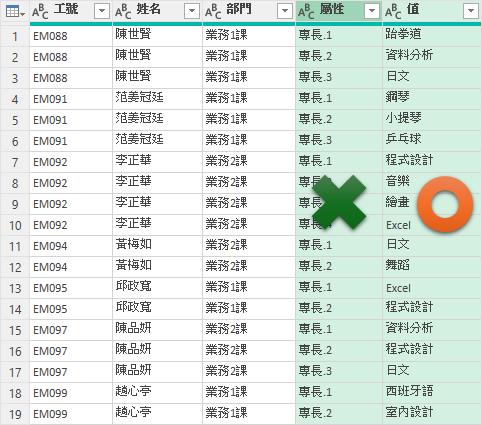
當然[值]資料行的名稱也並不貼切,我們可以改成名符其實的[專長]資料行,這就是我們所要的結果了,將原本非結構化的資料表,轉換成結構化資料表。基本上這就是一份可以進行摘要統計與分析的RAW DATA了。
【下載此實作範例檔案】