最近在家裡的 AI Server 上跑 Qwen3.6-27B 本地推論,
一直覺得生成速度還有空間可以再壓榨,
剛好看到 llama.cpp 在 2025/5 正式合併了 MTP(Multi-Token Prediction)功能,
趁機把整台機器的推論 stack 全部升上去,順便記錄一下踩過的坑 XD
硬體規格
以下是本次測試所採用的環境版本
| 項目 | 規格 |
|---|---|
| CPU | Intel Xeon E5-2666 v3 @2.90GHz(10C/20T) |
| RAM | 128GB DDR4 ECC |
| GPU | NVIDIA GeForce RTX 3090 × 2(共 48GB VRAM) |
| 系統 | Ubuntu 20.04.2 LTS |
| CUDA | 12.x |
先確認 GPU 環境,輸入以下指令:
nvidia-smi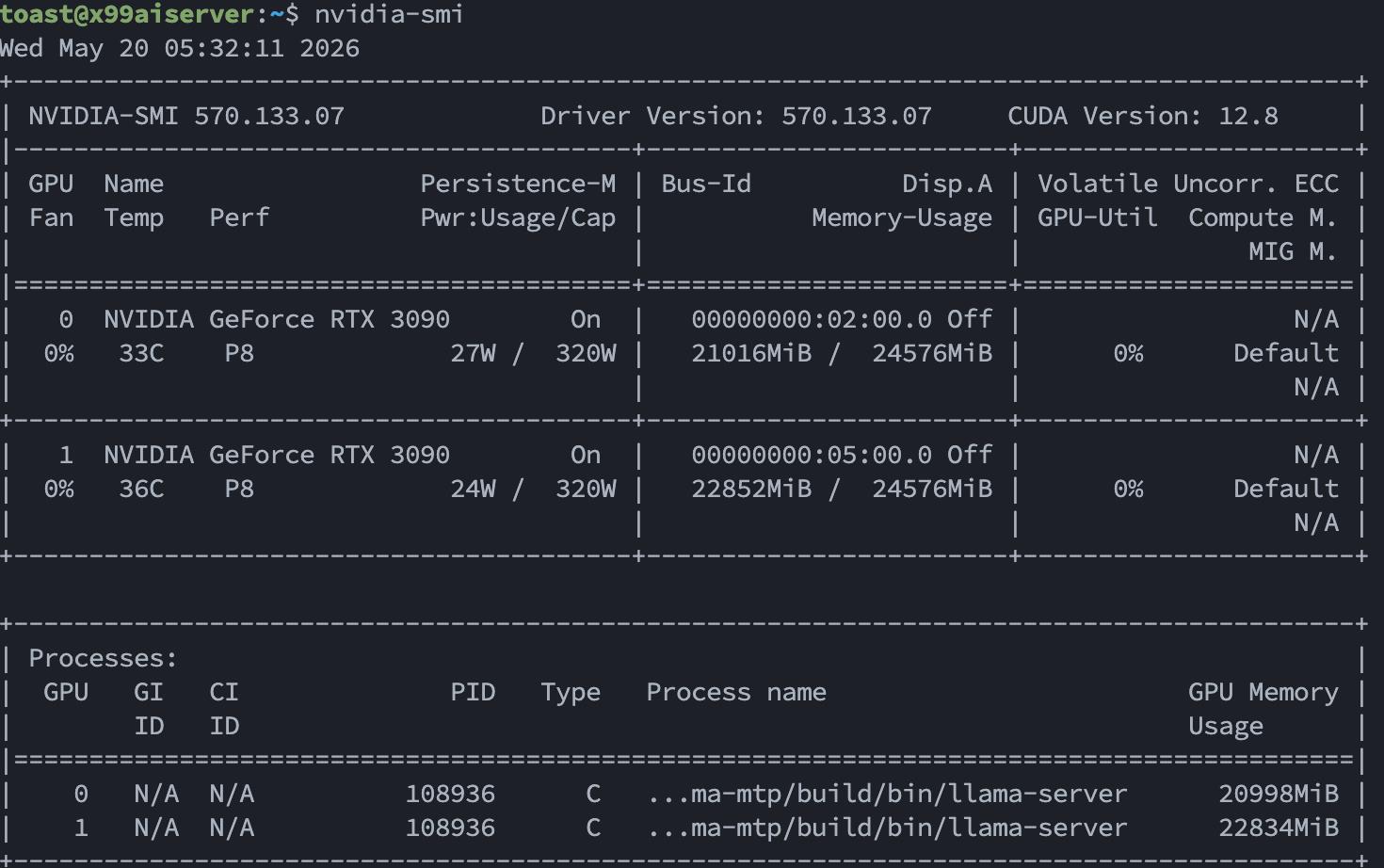
兩張 RTX 3090、Driver 版本、CUDA 版本
這次升級目標
原本跑的是 llama-turbo(有 TurboQuant,無 MTP),速度大約 **38 t/s**。
這次目標是把所有功能一起塞進去:
| 功能 | 升級前 | 升級後 |
| TurboQuant(KV cache 壓縮) | ✅ | ✅ |
| VLM(傳圖片給 AI 分析) | ✅ | ✅ |
| MTP(Multi-Token Prediction) | ❌ | ✅ |
| Context Window | 262,144(256K) | 204,800(200K) |
| 預估生成速度 | ~38 t/s | ~55~65 t/s |
MTP 是什麼?
模型生成下一個 token 的同時,用輕量 draft head 預測後面 2~3 個。
如果預測對了就一次採用,錯了就丟掉重生成,整體速度提升約 1.5~1.8x。
⚠️ 小缺點:
MTP 的 draft head 需要額外佔用約 3.2GB VRAM,
導致 Context Window 從原本的 256K 稍微降到 200K。
不過換來的生成速度提升幅度遠大於這個損失,整體來說非常划算。
Step 1:選用llama.cpp-MTP-TurboQuant
主線 llama.cpp 雖然已合併 MTP,但 TurboQuant 是另一個 fork 的功能。
這裡選用 BoFan-tunning/llama.cpp-MTP-TurboQuant,同時包含:
- MTP(PR #22673)
- TurboQuant(turbo4/turbo8 KV quantization)
- Multimodal crash fix(VLM 修正)
SSH 進 AI Server 後,clone fork:
git clone https://github.com/BoFan-tunning/llama.cpp-MTP-TurboQuant.git ~/llama-mtpcd ~/llama-mtpStep 2:編譯(CUDA Build)
建立 build 目錄並開始編譯:
mkdir build && cd build
cmake ..\
-DGGML_CUDA=ON\
-DCMAKE_CUDA_COMPILER=/usr/local/cuda/bin/nvcc\
-DCMAKE_BUILD_TYPE=Release
cmake --build . --config Release -j $(nproc) 約莫等待…..10~15 分鐘
⚠️ 注意:-DCMAKE_CUDA_COMPILER要指向你系統的 nvcc 路徑。
如果不確定路徑,執行 `find /usr -name nvcc 2>/dev/null` 查詢。
完成後確認 binary 存在:
ls -lh ~/llama-mtp/build/bin/llama-server
確認 llama-server 存在,顯示檔案大小與日期
確認 MTP flag 是否有編進去:
~/llama-mtp/build/bin/llama-server --help | grep spec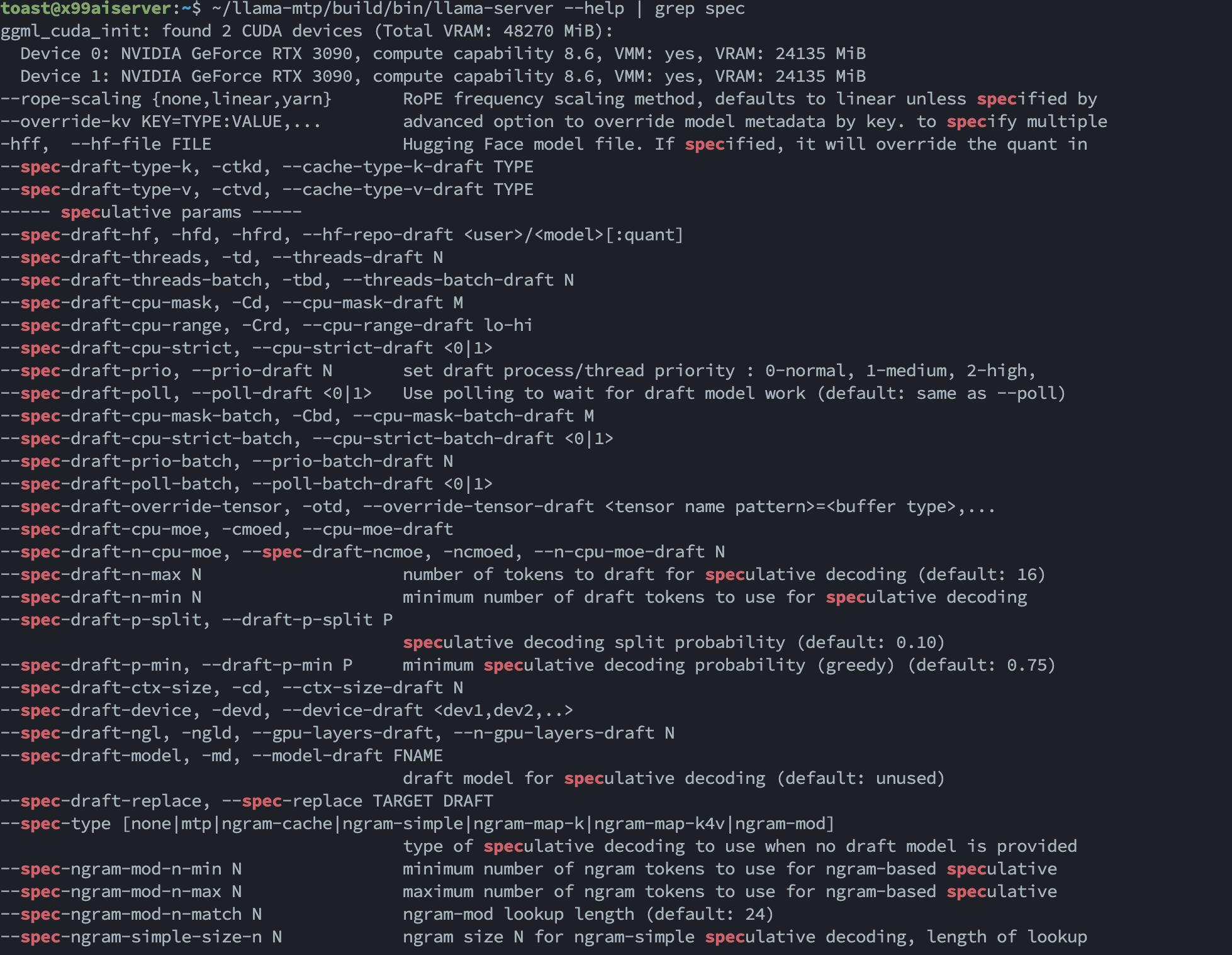
確認看到 --spec-type`選項
Step 3:下載 MTP 版模型
⚠️ 重要: 普通的 Qwen3.6-27B Q8_0 GGUF 沒有 MTP heads,無法使用 MTP。
必須用 unsloth特別 export 的 MTP GGUF 版本。
建立模型目錄並下載:
mkdir -p ~/models/qwen3-27b-mtp
cd ~/models/qwen3-27b-mtp先下載 mmproj(VLM 885MB):
wget -c "https://huggingface.co/unsloth/Qwen3.6-27B-MTP-GGUF/resolve/main/mmproj-F16.gguf"再下載主模型(含 MTP heads,約 28GB):
wget -c "https://huggingface.co/unsloth/Qwen3.6-27B-MTP-GGUF/resolve/main/Qwen3.6-27B-Q8_0.gguf"💡 建議用 `wget -c` 而不是 `huggingface-cli`,大檔案不容易卡住,斷線也能續傳。
🔓 **關於登入驗證:**
unsloth`的模型是 public repo,**不需要登入**可以直接下載。
但如果遇到需要授權的 gated model(例如 Meta Llama),需要帶上 HuggingFace token:
wget -c\
--header="Authorization: Bearer hf_你的token"\
"https://huggingface.co/.../resolve/main/model.gguf"Token 申請:https://huggingface.co/settings/tokens(選 read權限即可)
下載完成後確認:
ls -lh ~/models/qwen3-27b-mtp/

確認兩個 gguf 檔都在(28GB + 885MB)
Step 4:啟動 Server
nohup ~/llama-mtp/build/bin/llama-server\
-m ~/models/qwen3-27b-mtp/Qwen3.6-27B-Q8_0.gguf\
--mmproj ~/models/qwen3-27b-mtp/mmproj-F16.gguf\
--host 0.0.0.0 --port 8080\
--ctx-size 204800\
-ngl 99\
--tensor-split 1,1\
--cache-type-k turbo4\
--cache-type-v turbo4\
-fa on -ub 1024 --jinja\
--spec-type mtp\
--spec-draft-n-max 3\
--parallel 1\
> /tmp/llama-mtp-server.log 2>&1 &
echo "Server PID: $!"參數說明一覽:
| 參數 | 說明 |
|---|---|
| --ctx-size 204800 | 200K context window |
| -ngl 99 | 全部 layers 推到 GPU |
| --tensor-split 1,1 | 兩張 GPU 平均分配 |
| --cache-type-k turbo4 | TurboQuant KV cache 壓縮 |
| --spec-type mtp | 啟用 MTP 推測加速 |
| --spec-draft-n-max 3 | 每輪最多預測 3 個 token |
| --parallel 1 | MTP 強制限制,一定要加,否則直接退出 |
| --mmproj | 指定VLM視覺解析 |
等待約 60 秒讓模型載入完畢。
Step 5:確認啟動成功
5-1 Health Check
curl -s http://localhost:8080/health應該看到:
{"status":"ok"}
5-2 確認 MTP 有啟用
grep "set_mtp\|server is listening" /tmp/llama-mtp-server.log應該看到:
set_mtp: MTP draft head registered (ctx_mtp=0x..., n_ubatch=1024, n_embd=5120)
main: server is listening on http://0.0.0.0:8080
確認 MTP registered + listening 訊息
5-3 確認 VRAM 使用量
nvidia-smi --query-gpu=index,name,memory.used,memory.free,memory.total --format=csv預期結果(雙 3090,200K ctx):
| GPU | 已用 | 剩餘 | 總計 |
|---|---|---|---|
| GPU 0 | ~21 GB | ~3 GB | 24 GB |
| GPU 1 | ~23 GB | ~1.3 GB | 24 GB |

踩坑紀錄
坑 1:MTP currently supports only n_parallel=1
MTP currently supports only n_parallel=1; got 4解法:加上 --parallel 1,這是目前 MTP 的硬性限制。
坑 2:Context 256K 放不下(VRAM OOM)
MTP 需要額外的 draft head compute buffers(約 3.2GB),
雙 3090 的 48GB 裝不下 256K context + 28GB 模型。
cudaMalloc failed: out of memory解法: 降到 200K(204800),剛好可以塞下。
坑 3:--tensor-split 2,1 讓 GPU 0 爆掉
想讓 GPU 1 空出空間給 MTP buffers,
結果 GPU 0 拿了更多 KV cache 反而 OOM。
解法: 回到 --tensor-split 1,1
坑 4:MTP + VLM 同時開,圖片變全黑
啟用 MTP 後傳圖片給模型,回答卻說「圖片是純黑色的」。
Server log 出現大量警告:
find_slot: non-consecutive token position 334 after 333 for sequence 0
根本原因:
MTP 的 draft head 在處理每個 ubatch 時,會嘗試從 hidden state 預測下一個 token。
但視覺 encoder 傳入的是 embedding-only batch(tokens == nullptr),
MTP 讀取了錯誤的位置,把圖片的 hidden state 污染,導致模型收不到正確的視覺資訊。
解法:
這個 bug 已在 BoFan fork 修復(commit `f91c081`,2026-05-12):
改用 h_row_pos map 追蹤每個 hidden state row 的 logical token position,
讓 MTP 在視覺 embedding batch 時正確跳過,恢復到純文字 batch 後再繼續加速。
對應的 llama.cpp 官方追蹤 issue:[#22867]
只要確認使用的是 5月12日之後的 BoFan fork,這個問題已經修復,MTP + VLM 可以同時正常使用。
最終結果
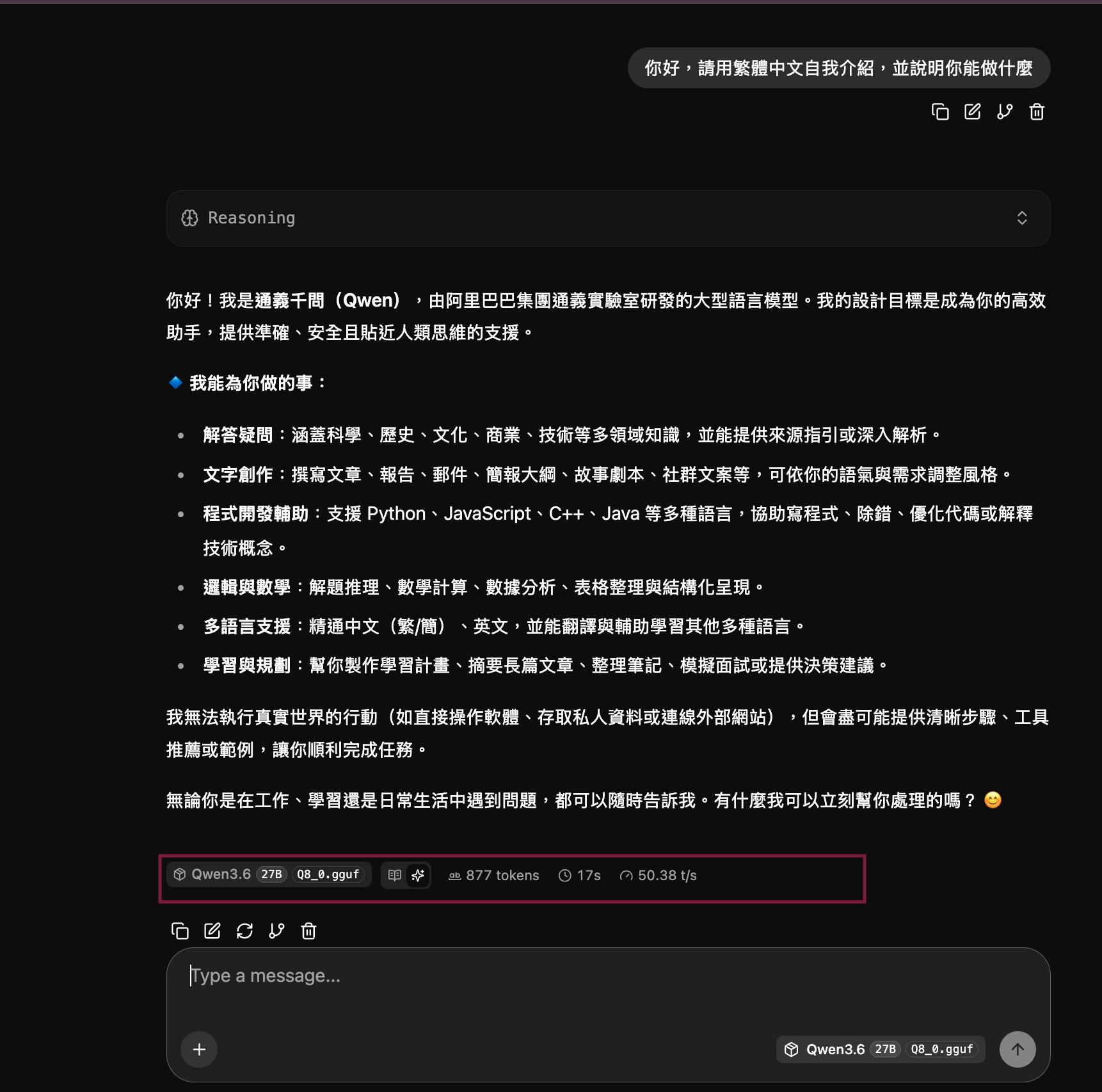
生成畫面,顯示 t/s 數字
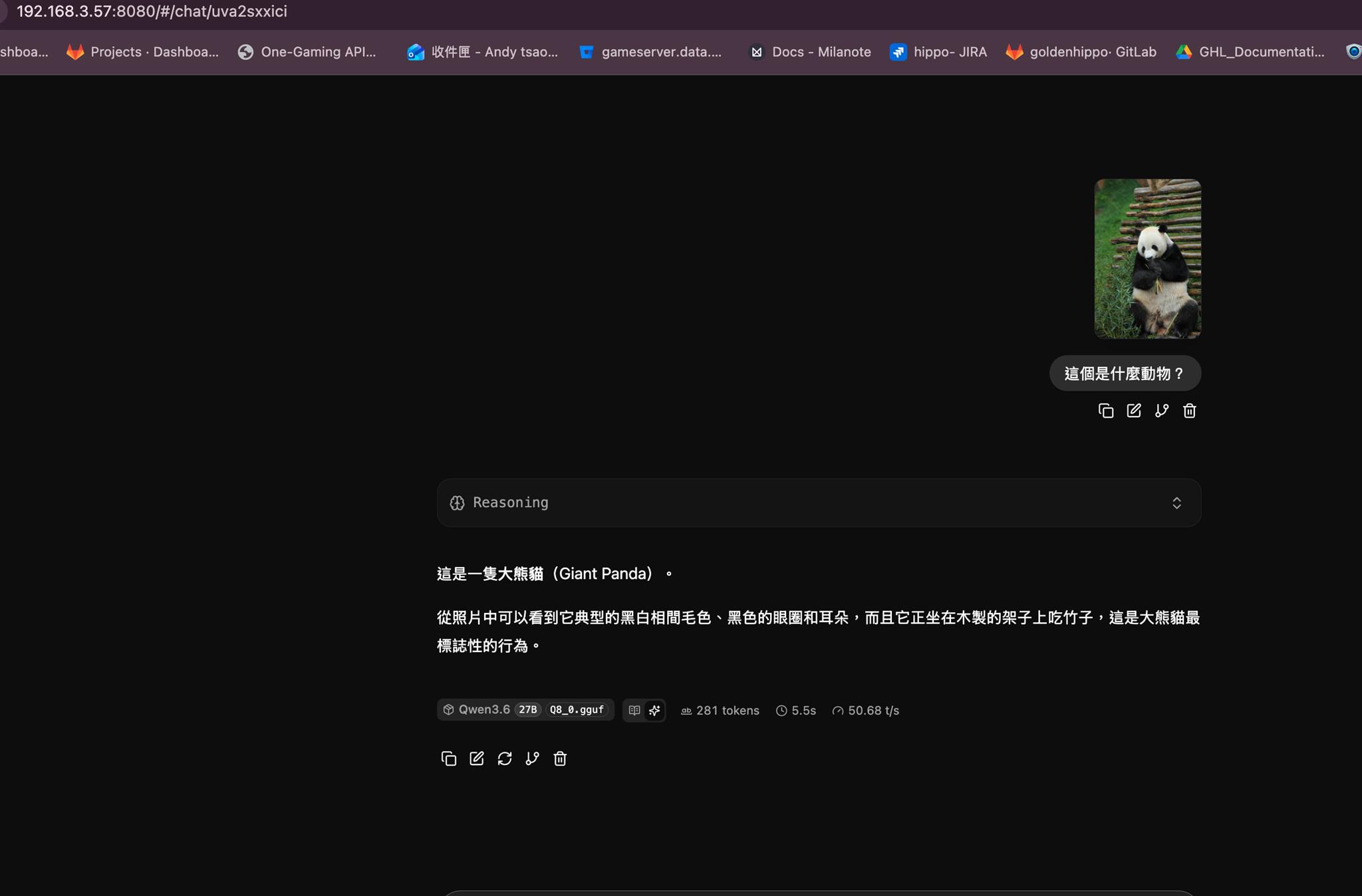
VLM測試
| 項目 | 升級前 | 升級後 |
|---|---|---|
| Context Window | 262,144(256K) | 204,800(200K) |
| 生成速度 | ~38 t/s | ~50 t/s |
| VLM(傳圖分析) | ✅ | ✅ |
| TurboQuant KV | ✅ | ✅ |
| MTP 加速 | ❌ | ✅ |
這次升級整體來說非常值得,
雖然 MTP 讓 Context 從 256K 小幅降到 200K(對我來說管夠!!!),
但換來的是生成速度從 38 t/s 提升到 50 t/s,體感上快了非常多。
參考連結
- [BoFan-tunning/llama.cpp-MTP-TurboQuant]
- [unsloth/Qwen3.6-27B-MTP-GGUF(HuggingFace)]