文、意如
1. 題目說明:
請開啟PYD03.py檔案,依下列題意進行作答,使輸出值符合題意要求。作答完成請另存新檔為PYA03.py再進行評分。
2. 設計說明:
請撰寫一程式,讀取登革熱近12個月每日確定病例統計read.csv,接著依序輸出下列項目:
a. 以遞減順序顯示居住縣市的病例人數
b. 顯示感染病例人數最多的5個國家,並按遞減順序顯示
c. 顯示台北市各區病例人數
d. 顯示台北市最近病例的日期
3. 輸入輸出:
輸入說明
讀取read.csv
輸出說明
分別輸出下列四段資料:
a. 以遞減順序顯示居住縣市的病例人數
b. 顯示感染病例人數最多的5個國家,並按遞減順序顯示
c. 顯示台北市各區病例人數
d. 顯示台北市最近病例的日期
範例輸入
無
範例輸出
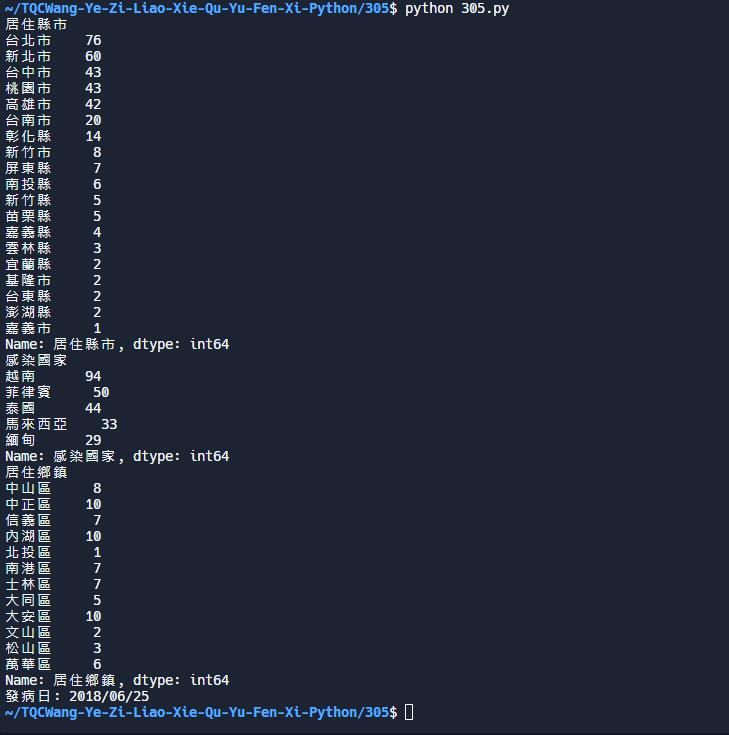
居住縣市
台北市 76
新北市 60
台中市 43
桃園市 43
高雄市 42
台南市 20
彰化縣 14
新竹市 8
屏東縣 7
南投縣 6
新竹縣 5
苗栗縣 5
嘉義縣 4
雲林縣 3
宜蘭縣 2
基隆市 2
台東縣 2
澎湖縣 2
嘉義市 1
Name: 居住縣市, dtype: int64
感染國家
越南 94
菲律賓 50
泰國 44
馬來西亞 33
緬甸 29
Name: 感染國家, dtype: int64
居住鄉鎮
中山區 8
中正區 10
信義區 7
內湖區 10
北投區 1
南港區 7
士林區 7
大同區 5
大安區 10
文山區 2
松山區 3
萬華區 6
Name: 居住鄉鎮, dtype: int64
發病日: 2018/06/25題目提示:
檔案連結:read.csv (請另存檔案,必須與程式同一資料夾)
# 載入 pandas 模組縮寫為 pd
import ___ as ___
# 讀取csv檔
df1 = pd.read_csv(___, encoding="utf-8", sep=",", header=0)
# 居住縣市病例人數,並按遞減順序顯示
df_county = df1.groupby("居住縣市")["___"].___
print(df_county.sort_values(___=___))
# 顯示感染病例人數最多的5個國家,並按遞減順序顯示
df_country = df1.groupby("感染國家")["___"].___
print(df_country.sort_values(___=___).___)
# 台北市各區病例人數
df_taipei = df1[df1.居住縣市 == "___"]
print(df_taipei.groupby("居住鄉鎮")["___"].___)
# 台北市最近病例的日期
print("發病日: " + df_taipei.___.___())
參考解答
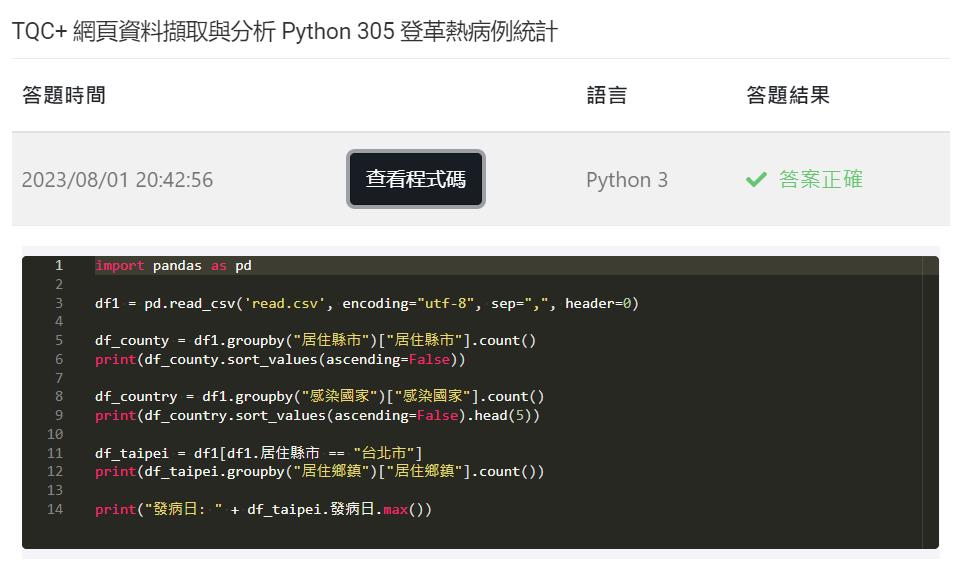
# -*- coding: utf-8 -*-
# 載入 pandas 模組縮寫為 pd
import pandas as pd
# 讀取csv檔
df1 = pd.read_csv("read.csv", encoding="utf-8", sep=",", header=0)
# 居住縣市病例人數,並按遞減順序顯示
df_county = df1.groupby("居住縣市")["居住縣市"].count()
print(df_county.sort_values(ascending=False, kind='mergesort'))
# 顯示感染病例人數最多的5個國家,並按遞減順序顯示
df_country = df1.groupby("感染國家")["感染國家"].count()
print(df_country.sort_values(ascending=False, kind='mergesort').head(5))
# 台北市各區病例人數
df_taipei = df1[df1.居住縣市 == "台北市"]
print(df_taipei.groupby("居住鄉鎮")["居住鄉鎮"].count())
# 台北市最近病例的日期
print("發病日: " + df_taipei.發病日.max())
Yiru@Studio - 關於我 - 意如