文、意如
1. 題目說明:
請開啟PYD02.py檔案,依下列題意進行作答,使輸出值符合題意要求。作答完成請另存新檔為PYA02.py再進行評分。
2. 設計說明:
請撰寫一程式,爬取https://www.codejudger.com/target/5203.html,程式須回傳下列資訊:
- 大樂透的開出順序
- 大樂透的大小順序
- 大樂透的特別號
3. 輸入輸出:
輸入說明
爬取網頁
輸出說明
- 大樂透的開出順序
- 大樂透的大小順序
- 大樂透的特別號
範例輸入
無
範例輸出

題目題示:
# -*- coding: utf-8 -*-
import ___
import requests
url = '___'
# GET 請求
html = requests.___(___)
# 使用 lxml 解析器
objSoup = bs4.BeautifulSoup(html.text, '___')
dataTag = objSoup.select('.contents_box02')
balls = dataTag[2].find_all('___', {'class': '___'})
print("大樂透開獎 : ")
print('-------------')
# 開出順序
print("開出順序 : ", end='')
for i in range(6):
print(____.____, end=' ')
# 大小順序
print("\n大小順序 : ", end='')
for i in range(6, len(balls)):
print(____.____, end=' ')
# 特別號:資料位於 <div class="ball_red"></div>
redball = dataTag[2].find_all('___', {'class': '___'})
print("\n特別號 :", ____)
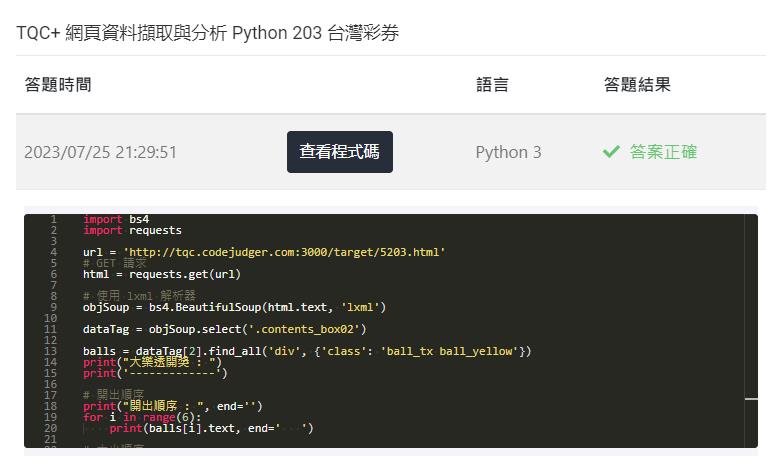
參考解答:
# -*- coding: utf-8 -*-
import bs4
import requests
url = 'https://www.codejudger.com/target/5203.html'
# GET 請求
html = requests.get(url)
# 使用 lxml 解析器
objSoup = bs4.BeautifulSoup(html.text, 'lxml')
dataTag = objSoup.select('.contents_box02')
balls = dataTag[2].find_all('div', {'class': 'ball_tx'})
print("大樂透開獎 : ")
print('-------------')
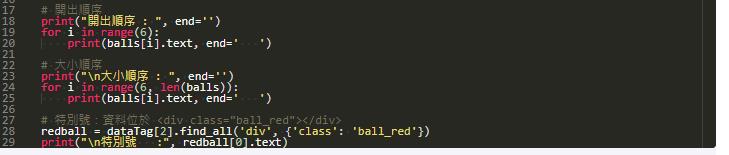
# 開出順序
print("開出順序 : ", end='')
for i in range(6):
print(balls[i].text, end=' ')
# 大小順序
print("\n大小順序 : ", end='')
for i in range(6, len(balls)):
print(balls[i].text, end=' ')
# 特別號:資料位於 <div class="ball_red"></div>
redball = dataTag[2].find_all('div', {'class': 'ball_red'})
print("\n特別號 :", redball[0].text)
執行結果:

Yiru@Studio - 關於我 - 意如