目標:中華電信股票資訊
https://www.google.com/search?q=TPE: 2412
抓取股票資訊
目標網址:
https://www.google.com/search?q=
等於後面接上"個股"代號
中華電信代號為:TPE: 2412
因此目標位置為 https://www.google.com/search?q=TPE: 2412
1.先把整張網頁爬回來
#目標: https://www.google.com/search?q=
#TPE: 2412
import requests
#網址後方加上個股資訊. ex中華電信: TPE: 2412
targetURL = 'https://www.google.com/search?q='
def get_stock_page(url, stock_id):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/66.0.3359.181 Safari/537.36'}
resp = requests.get(url + stock_id, headers=headers)
if resp.status_code != 200:
print('Invalid url:', resp.url)
return None
else:
return resp.text
if __name__ == '__main__':
page = get_stock_page(targetURL, 'TPE: 2412')
print(page)
補充說明:
有時在爬一些網站的時候會一直連不上,因為有的網站是不允許被爬蟲的
所以我們可以設定User-Agent假裝自己是瀏覽器,因為User-Agent會告訴網站它是透過什麼工具
一般的網站可以分析出瀏覽器名稱、瀏覽器版本號、渲染引擎、操作系統 發送請求的
所以我們可以試寫下面這一段來假裝自己是用瀏覽器開啟的
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/66.0.3359.181 Safari/537.36'}
resp = requests.get(url + stock_id, headers=headers)按下F12 >>Network->隨便點選一頁>>就可以知道自己的User-Agent
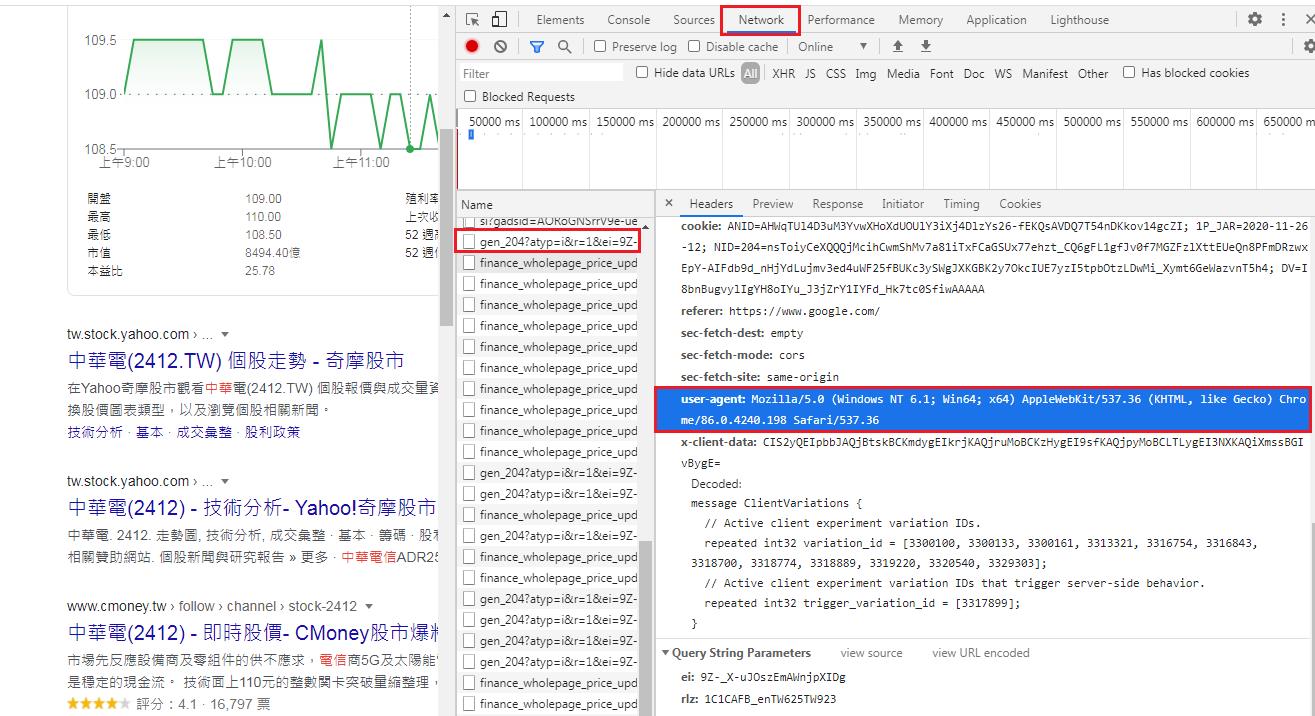
| 字串 | 說明 |
|---|---|
| Mozilla/5.0 | Mozilla/5.0 是一個通用標記符號,用來表示與 Mozilla 相容,這幾乎是現代瀏覽器的標配。[4] |
| (iPad; U; CPU OS 3_2_1 like Mac OS X; en-us) | 瀏覽器所執行的系統的詳細資訊 |
| AppleWebKit/531.21.10 | 瀏覽器所使用的平台 |
| (KHTML, like Gecko) | 瀏覽器平台的細節 |
| Mobile/7B405 | 被瀏覽器用於指示特定的直接由瀏覽器提供或者通過第三方提供的可用的增強功能。這方面的一個實例是Microsoft Live Meeting,它註冊了一個擴充以使Live Meeting服務知道該軟體是否已經安裝上,這意味著它可以為加入會議提供一個簡化的體驗。 |
抓取
1.已收盤: 11月26日 下午1:30 [GMT+8] ·
2.免責聲明
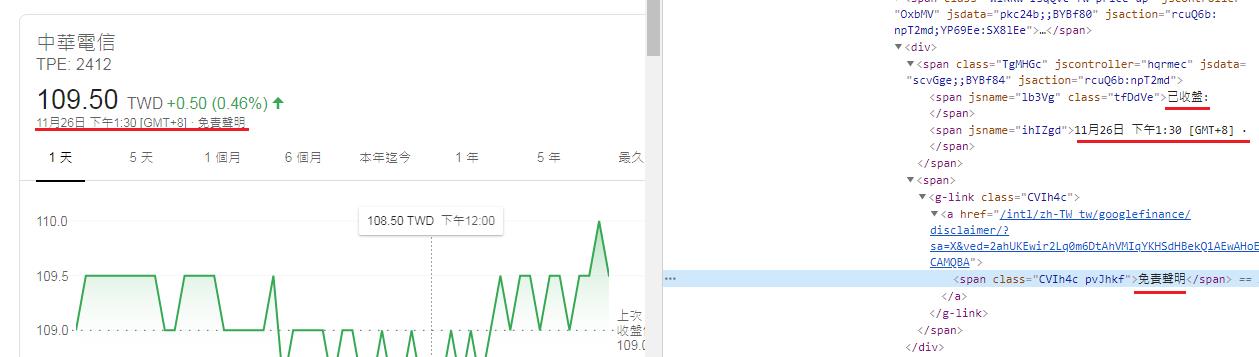
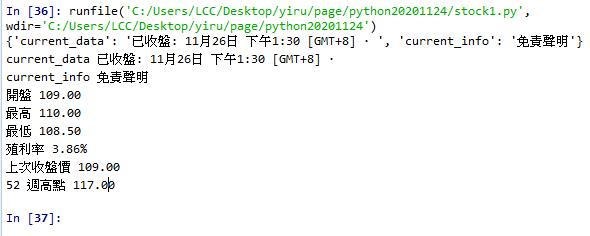
存成dict(字典) key:value 格式
例如: {'current_data': '已收盤: 11月26日 下午1:30 [GMT+8] · ', 'current_info': '免責聲明'}
def get_stock_info(webtxt):
soup = BeautifulSoup(webtxt, 'html.parser')
stock = dict()
sections = soup.find_all('g-card-section')
#print(sections)
myspans = sections[1].find_all('div', recursive=False)[1].find_all('span', recursive=False)
#Beautiful Soup會查詢目前tag的子孫節點,如果只想要搜詢tag的直接子節點,參數可以使用recursive=False
#print(myspans)
stock['current_data'] = myspans[0].text
stock['current_info'] = myspans[1].text
print(stock)
if __name__ == '__main__':
page = get_stock_page(targetURL, 'TPE: 2412')
if page:
stock = get_stock_info(page)

抓取股票資訊
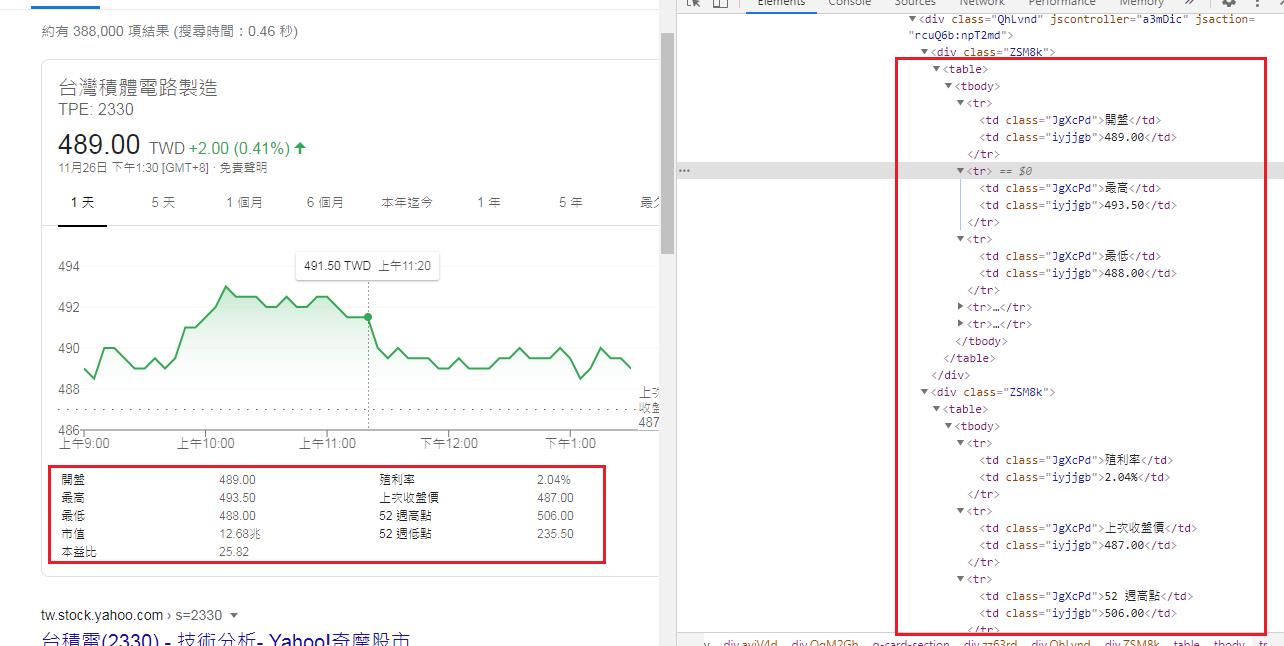
# 第 4 個 g-card-section, 有左右兩個 table 分別存放股票資訊
for table in sections[3].find_all('table'):
for tr in table.find_all('tr')[:3]: #[:3] 取得3個字
key = tr.find_all('td')[0].text.lower().strip() #lower()轉小寫。 strip()去除頭尾空格
value = tr.find_all('td')[1].text.strip()
stock[key] = value
return stock
if __name__ == '__main__':
page = get_stock_page(targetURL, 'TPE: 2412')
if page:
stock = get_stock_info(page)
for k, v in stock.items():
print(k, v)
完整程式碼:
#目標: https://www.google.com/search?q=
#TPE: 2412
import requests
from bs4 import BeautifulSoup
#網址後方加上個股資訊. ex中華電信: TPE: 2412
targetURL = 'https://www.google.com/search?q='
def get_stock_page(url, stock_id):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/66.0.3359.181 Safari/537.36'}
resp = requests.get(url + stock_id, headers=headers)
if resp.status_code != 200:
print('Invalid url:', resp.url)
return None
else:
return resp.text
def get_stock_info(webtxt):
soup = BeautifulSoup(webtxt, 'html.parser')
stock = dict()
sections = soup.find_all('g-card-section')
#print(sections)
myspans = sections[1].find_all('div', recursive=False)[1].find_all('span', recursive=False)
#print(myspans)
stock['current_data'] = myspans[0].text
stock['current_info'] = myspans[1].text
print(stock)
# 第 4 個 g-card-section, 有左右兩個 table 分別存放股票資訊
for table in sections[3].find_all('table'):
for tr in table.find_all('tr')[:3]: #[:3] 取得3個字
key = tr.find_all('td')[0].text.lower().strip() #lower()轉小寫。 strip()去除頭尾空格
value = tr.find_all('td')[1].text.strip()
stock[key] = value
return stock
if __name__ == '__main__':
page = get_stock_page(targetURL, 'TPE: 2412')
if page:
stock = get_stock_info(page)
for k, v in stock.items():
print(k, v)
Yiru@Studio - 關於我 - 意如