#目標位置>>Yahoo>>電影>>Yahoo本週新片
#https://tw.movies.yahoo.com/movie_thisweek.html
if __name__ == '__main__':
webpage = check_req_url(yahoo_movie_url)
#print(webpage)
if webpage:
movies = get_week_new_movies(webpage)
#print(movies)2.抓出所有的電影資訊
目標位址:https://tw.movies.yahoo.com/movie_thisweek.html
1.測試網頁是否請求成功或失敗
import requests
#Yahoo電影
yahoo_movie_url = 'https://tw.movies.yahoo.com/movie_thisweek.html' #目標位置
def check_req_url(url): #測試請求網址是否請求成功
resp = requests.get(url) #請求網址
print(resp.status_code) #錯誤時404,成功時200
if resp.status_code != 200: #如果請求失敗
print('Invalid url:', resp.url) #印出請求失敗的網址
return "fail" #回傳失敗提示訊息
else:
return resp.text #回傳請求成功的html文字
if __name__ == '__main__':
webpage = check_req_url(yahoo_movie_url)
print(webpage)
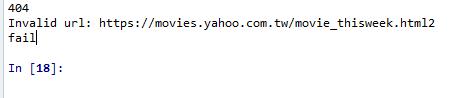
請求失敗回應:
請求成功回應: 整張網頁html轉text抓回來
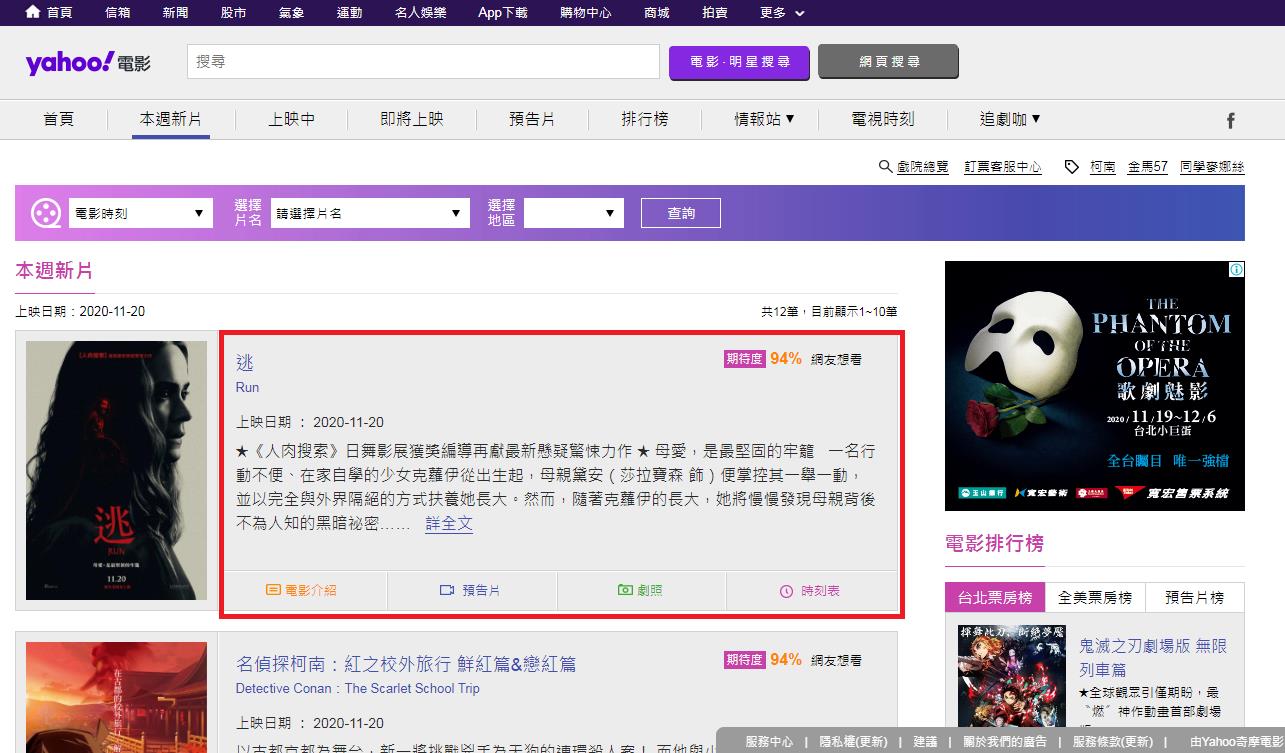
2.抓出所有的電影名稱
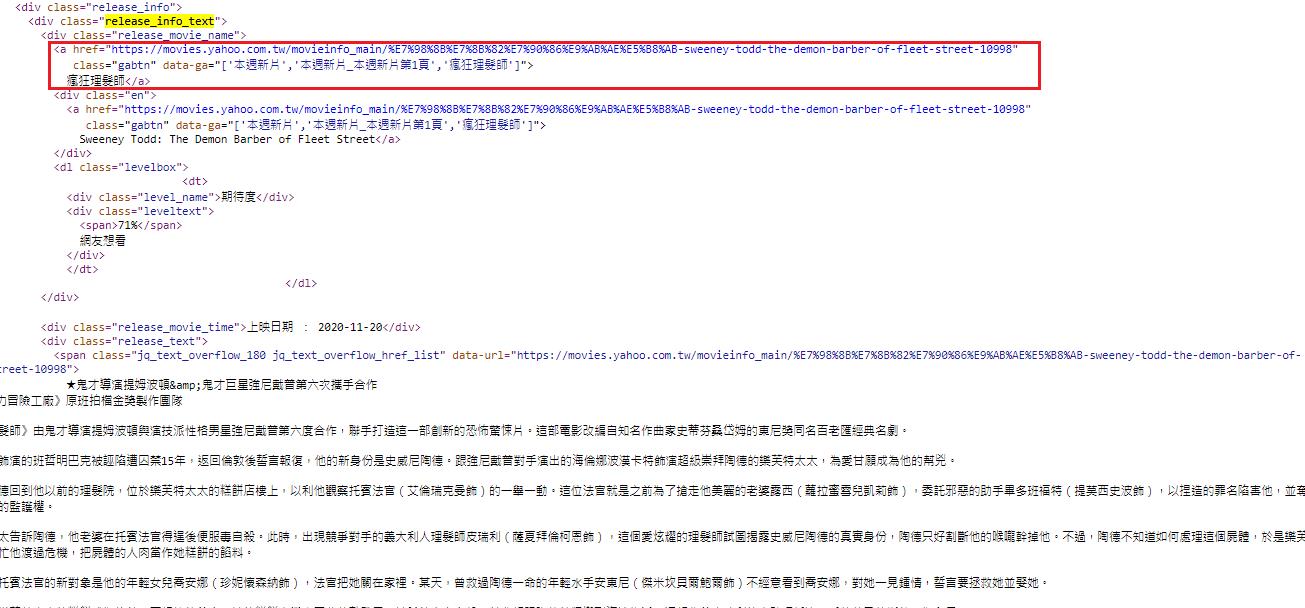
抓取的區域為這一區
F12尋找每一筆資料固定被什麼標籤包住
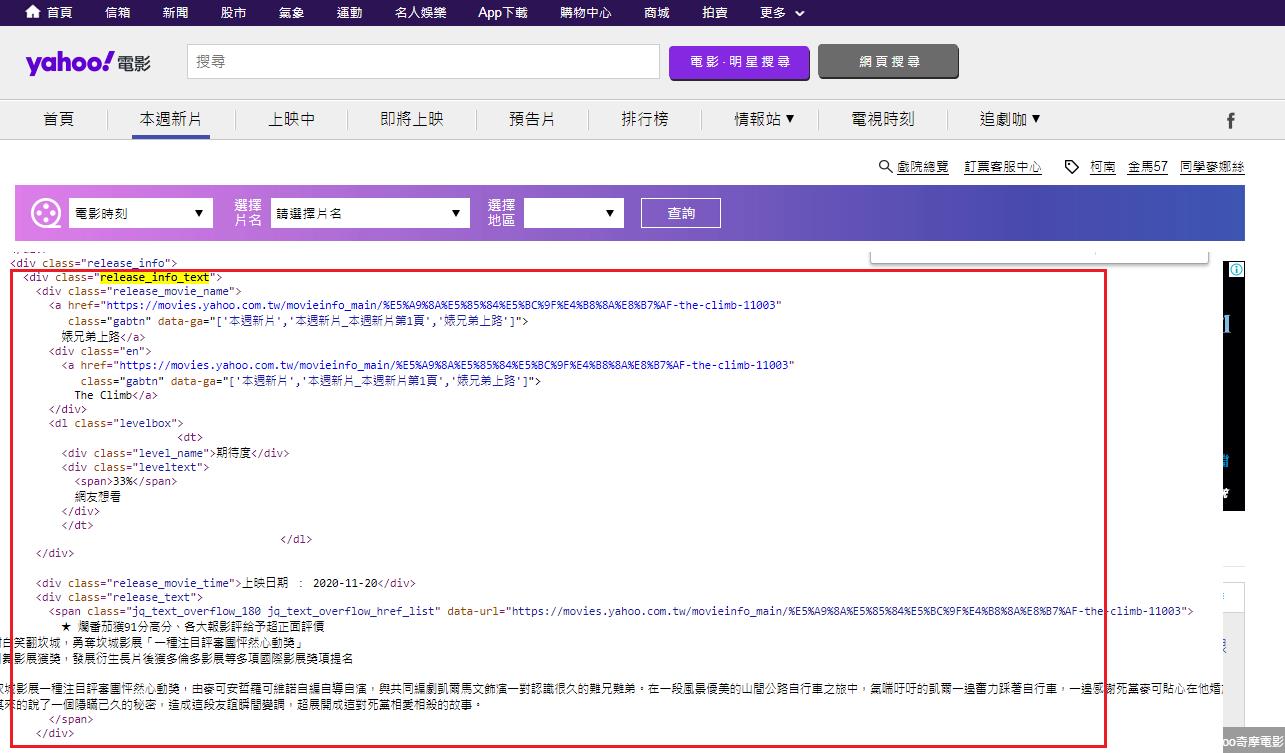
每一筆的資料固定被 <div class="release_info_text"></div> 給包住
所以先縮小範圍,把 <div class="release_info_text"></div>內的文字先抓回來
from bs4 import BeautifulSoup
def get_week_new_movies(webpage): #抓取電影資訊
soup = BeautifulSoup(webpage, 'html.parser') #網頁解析
movies = [] #域設電影資訊存這裡
#抓取<div class="release_info_text"></div>內文字
rows = soup.find_all('div', 'release_info_text')
print(rows)
return movies
if __name__ == '__main__':
webpage = check_req_url(yahoo_movie_url)
print(webpage)
if webpage:
movies = get_week_new_movies(webpage)
print(movies)我們已經把所有的電影資訊都抓回來了。
每一筆的資訊都存在<div class="release_info_text"></div>
我們必須一筆筆讀出來。使用for 迴圈
接著繼續抓取電影名稱
def get_week_new_movies(webpage): #抓取電影資訊
soup = BeautifulSoup(webpage, 'html5lib') #網頁解析
movies = [] #預設電影資訊存這裡
#抓取<div class="release_info_text"></div>內文字
rows = soup.find_all('div', 'release_info_text')
data_movie = dict()
#print(rows)
for row in rows:
data_movie = dict() #存成{"key":"value"}格式
#電影名稱
data_movie['ch_name'] = row.find('div', 'release_movie_name').a.text.strip()
#print(data_movie)#每一圈 都會被取代成下一筆資料 data_movie['ch_name']
#第一圈
#data_movie['ch_name']={'ch_name': '逃'}
#第二圈
#data_movie['ch_name']={'ch_name': '名偵探柯南:紅之校外旅行 鮮紅篇&戀紅篇'}
#第三圈
#data_movie['ch_name']={'ch_name': '惡童當街 經典重映'}
movies.append(data_movie) #再被取代前先存入for 外面的movies=[]
#第一圈存入
#[{'ch_name': '逃'}]
#第二圈存入
#[{'ch_name': '逃'}, {'ch_name': '名偵探柯南:紅之校外旅行 鮮紅篇&戀紅篇'}]
#第三圈存入
#[{'ch_name': '逃'}, {'ch_name': '名偵探柯南:紅之校外旅行 鮮紅篇&戀紅篇'}, {'ch_name': '惡童當街 經典重映'}]
#print(movies)
return movies
if __name__ == '__main__':
webpage = check_req_url(yahoo_movie_url)
#print(webpage)
if webpage:
movies = get_week_new_movies(webpage)
print(movies)

完整程式碼:
#目標位置>>Yahoo>>電影>>Yahoo本週新片
#https://tw.movies.yahoo.com/movie_thisweek.html
import requests
from bs4 import BeautifulSoup
#Yahoo電影
yahoo_movie_url = 'https://tw.movies.yahoo.com/movie_thisweek.html' #目標位置
def check_req_url(url): #測試請求網址是否請求成功
resp = requests.get(url) #請求網址
#print(resp.status_code) #錯誤時404,成功時200
if resp.status_code != 200: #如果請求失敗
print('Invalid url:', resp.url) #印出請求失敗的網址
return "fail" #回傳失敗提示訊息
else:
return resp.text #回傳請求成功的html文字
def get_week_new_movies(webpage): #抓取電影資訊
soup = BeautifulSoup(webpage, 'html.parser') #網頁解析
movies = [] #域設電影資訊存這裡
#抓取<div class="release_info_text"></div>內文字
rows = soup.find_all('div', 'release_info_text')
data_movie = dict()
#print(rows)
for row in rows:
data_movie = dict() #存成{"key":"value"}格式
#電影名稱
data_movie['ch_name'] = row.find('div', 'release_movie_name').a.text.strip()
#print(data_movie)#每一圈 都會被取代成下一筆資料 data_movie['ch_name']
#第一圈
#data_movie['ch_name']={'ch_name': '逃'}
#第二圈
#data_movie['ch_name']={'ch_name': '名偵探柯南:紅之校外旅行 鮮紅篇&戀紅篇'}
#第三圈
#data_movie['ch_name']={'ch_name': '惡童當街 經典重映'}
movies.append(data_movie) #再被取代前先存入for 外面的movies=[]
#第一圈存入
#[{'ch_name': '逃'}]
#第二圈存入
#[{'ch_name': '逃'}, {'ch_name': '名偵探柯南:紅之校外旅行 鮮紅篇&戀紅篇'}]
#第三圈存入
#[{'ch_name': '逃'}, {'ch_name': '名偵探柯南:紅之校外旅行 鮮紅篇&戀紅篇'}, {'ch_name': '惡童當街 經典重映'}]
#print(movies)
return movies
if __name__ == '__main__':
webpage = check_req_url(yahoo_movie_url)
#print(webpage)
if webpage:
movies = get_week_new_movies(webpage)
print(movies)
接下來練習抓取其他資料:
期待度、英文名稱、電影介紹
for row in rows:
data_movie = dict() #存成{"key":"value"}格式
#電影名稱
data_movie['ch_name'] = row.find('div', 'release_movie_name').a.text.strip()
#英文名稱
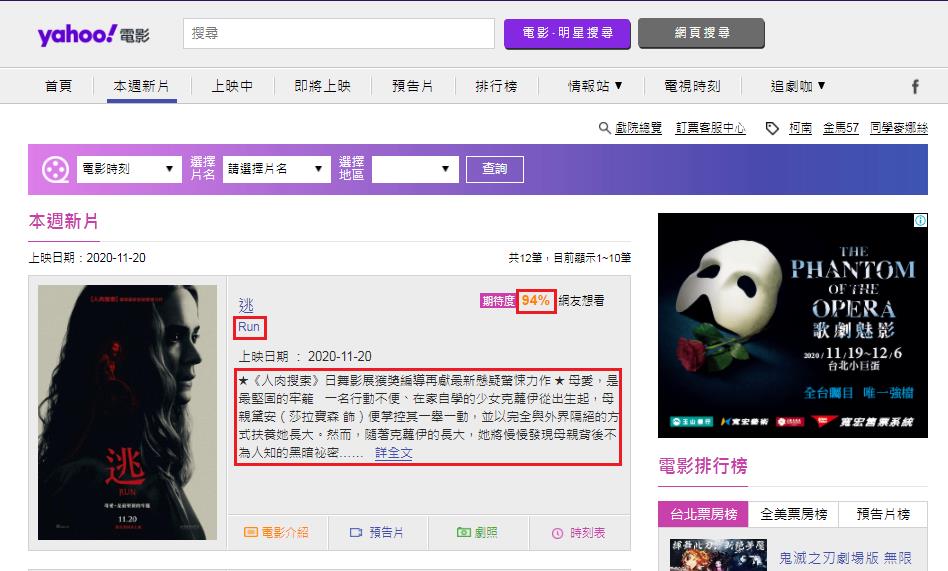
data_movie['english_name'] = row.find('div', 'release_movie_name').find('div', 'en').a.text.strip()
#電影介紹
data_movie['info'] = row.find('div', 'release_text').text.strip()
#期待度
data_movie['expectation'] = row.find('div', 'leveltext').span.text.strip()

完整:
#目標位置>>Yahoo>>電影>>Yahoo本週新片
#https://tw.movies.yahoo.com/movie_thisweek.html
import requests
from bs4 import BeautifulSoup
#Yahoo電影
yahoo_movie_url = 'https://tw.movies.yahoo.com/movie_thisweek.html' #目標位置
def check_req_url(url): #測試請求網址是否請求成功
resp = requests.get(url) #請求網址
#print(resp.status_code) #錯誤時404,成功時200
if resp.status_code != 200: #如果請求失敗
print('Invalid url:', resp.url) #印出請求失敗的網址
return "fail" #回傳失敗提示訊息
else:
return resp.text #回傳請求成功的html文字
def get_week_new_movies(webpage): #抓取電影資訊
soup = BeautifulSoup(webpage, 'html.parser') #網頁解析
movies = [] #域設電影資訊存這裡
#抓取<div class="release_info_text"></div>內文字
rows = soup.find_all('div', 'release_info_text')
data_movie = dict()
#print(rows)
for row in rows:
data_movie = dict() #存成{"key":"value"}格式
#電影名稱
data_movie['ch_name'] = row.find('div', 'release_movie_name').a.text.strip()
#英文名稱
data_movie['english_name'] = row.find('div', 'release_movie_name').find('div', 'en').a.text.strip()
#電影介紹
data_movie['info'] = row.find('div', 'release_text').text.strip()
#期待度
data_movie['expectation'] = row.find('div', 'leveltext').span.text.strip()
#預告片
#print(data_movie)#每一圈 都會被取代成下一筆資料 data_movie['ch_name']
#第一圈
#data_movie['ch_name']={'ch_name': '逃'}
#第二圈
#data_movie['ch_name']={'ch_name': '名偵探柯南:紅之校外旅行 鮮紅篇&戀紅篇'}
#第三圈
#data_movie['ch_name']={'ch_name': '惡童當街 經典重映'}
movies.append(data_movie) #再被取代前先存入for 外面的movies=[]
#第一圈存入
#[{'ch_name': '逃'}]
#第二圈存入
#[{'ch_name': '逃'}, {'ch_name': '名偵探柯南:紅之校外旅行 鮮紅篇&戀紅篇'}]
#第三圈存入
#[{'ch_name': '逃'}, {'ch_name': '名偵探柯南:紅之校外旅行 鮮紅篇&戀紅篇'}, {'ch_name': '惡童當街 經典重映'}]
#print(movies)
return movies
if __name__ == '__main__':
webpage = check_req_url(yahoo_movie_url)
#print(webpage)
if webpage:
movies = get_week_new_movies(webpage)
print(movies)
Yiru@Studio - 關於我 - 意如