文、意如
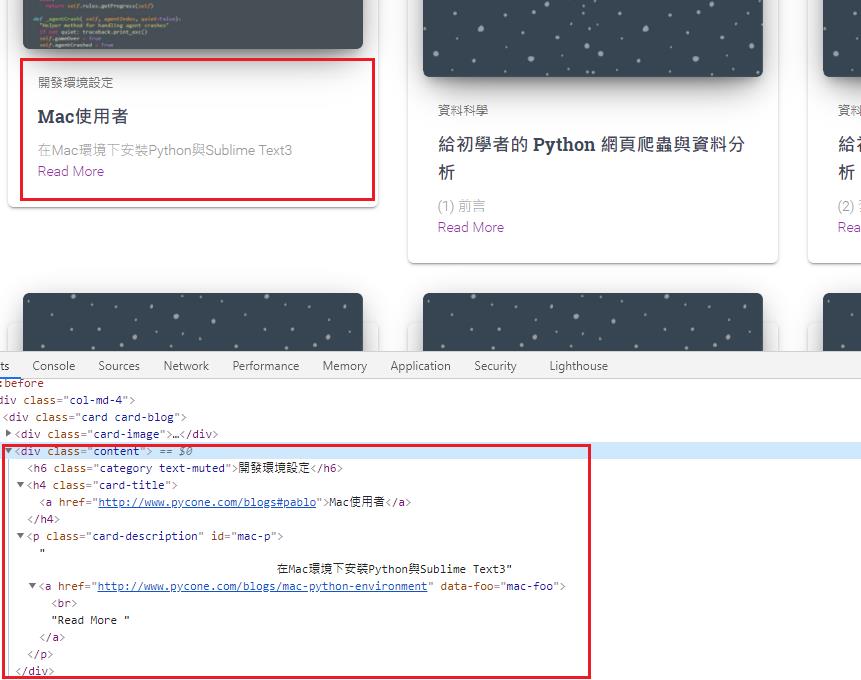
抓取div裡面的元素
import requests
from bs4 import BeautifulSoup
def main():
resp = requests.get('http://jwlin.github.io/py-scraping-analysis-book/ch2/blog/blog.html')
soup = BeautifulSoup(resp.text, 'html.parser')
# 取得各篇 blog 的所有文字
divs = soup.find_all('div', 'content')
#print(divs)
for div in divs:
# 方法一, 使用 text (會包含許多換行符號)
#print(div.text)
# 方法二, 使用 tag 定位
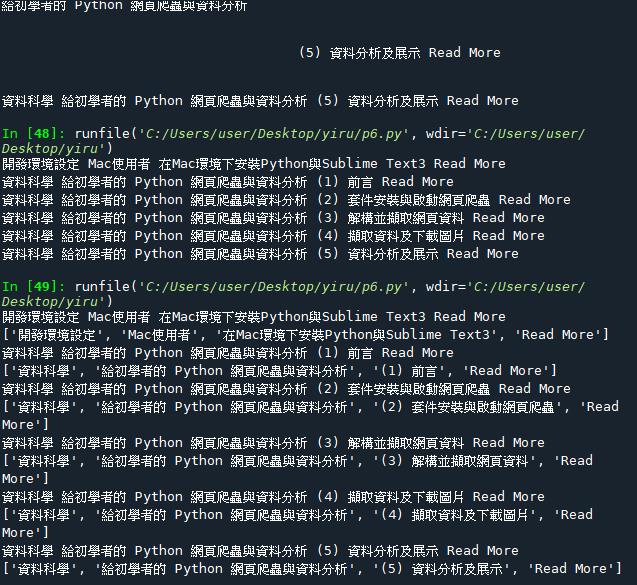
print(div.h6.text.strip(), div.h4.a.text.strip(), div.p.text.strip())
if __name__ == '__main__':
main()
Yiru@Studio - 關於我 - 意如