1.只抓指定標籤有套用css類別 ,例如:<h3 class="article__title">
2.把標籤去除掉,只留下文字
目標網址:https://www.dotblogs.com.tw/YiruAtStudio
1.只抓指定標籤有套用css類別 ,例如:所有的<h3 class="article__title"></h3>
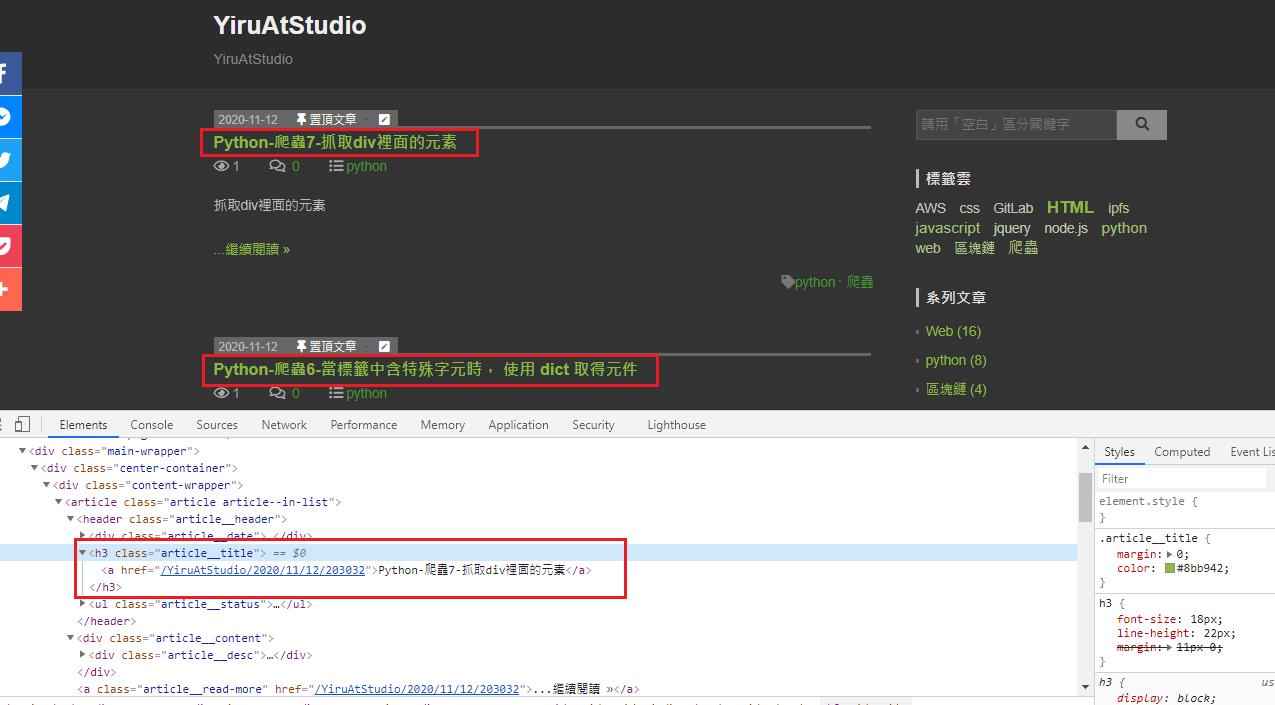
import requests
from bs4 import BeautifulSoup
def main():
resp = requests.get('https://www.dotblogs.com.tw/YiruAtStudio')
soup = BeautifulSoup(resp.text, 'html.parser')
#方法1:
mytitle = soup.find_all('h3', 'article__title') #把符合條件的存入[]
print(mytitle)
#方法2:
B2 = soup.find_all('h3', {'class': 'article__title'})
print(B2)
print("=====================================")
#方法3 #由於 class 是 Python 程式語言的保留字,所以 Beautiful Soup 改以 class_ 這個名稱代表 HTML 節點的 class 屬性
#拿完整的 class 字串來進行比對
B3 = soup.find_all('h3', class_='article__title')
print(B3)
print("=====================================")
if __name__ == '__main__':
main()
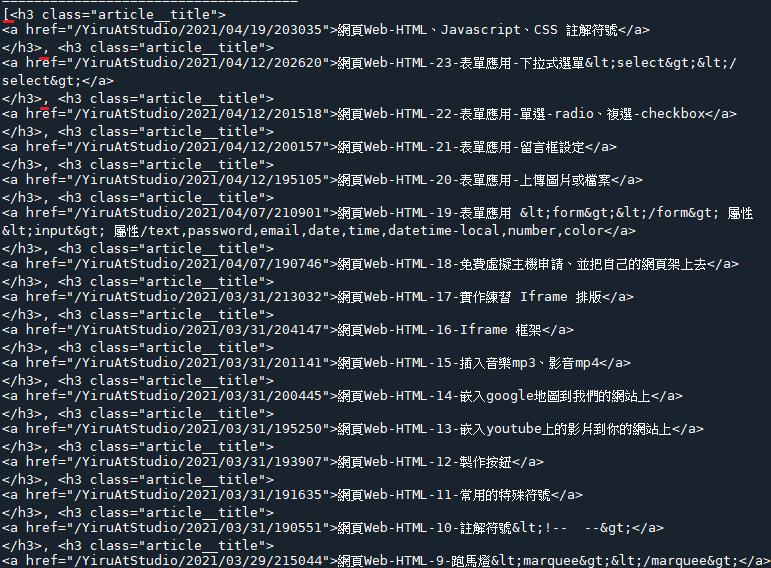
2.把標籤去除掉,只留下文字
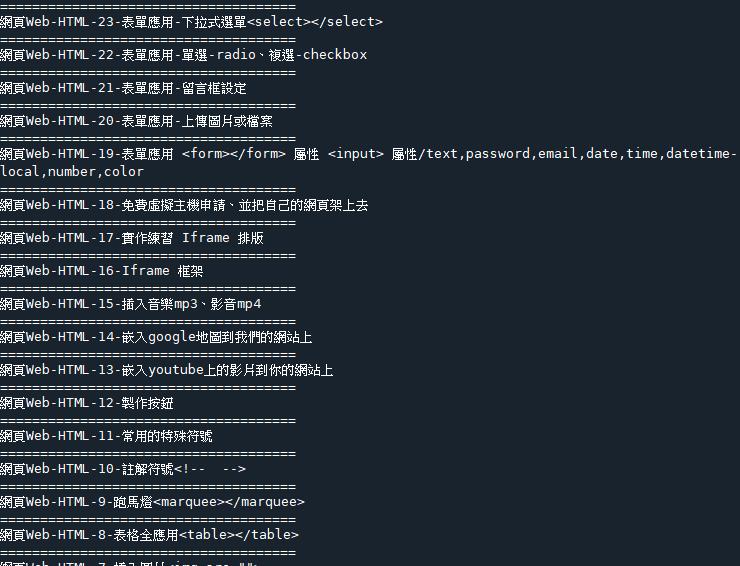
B4 = soup.find_all('h3', class_='article__title')
for title in B4 :
print(title.a.text)
import requests
from bs4 import BeautifulSoup
def main():
resp = requests.get('https://www.dotblogs.com.tw/YiruAtStudio')
soup = BeautifulSoup(resp.text, 'html.parser')
#方法1:
mytitle = soup.find_all('h3', 'article__title') #把符合條件的存入[]
print(mytitle)
#方法2:
B2 = soup.find_all('h3', {'class': 'article__title'})
print(B2)
print("=====================================")
#方法3
B3 = soup.find_all('h3', class_='article__title')
print(B3)
print("=====================================")
for title in B3 :
print(title.a.text)
if __name__ == '__main__':
main()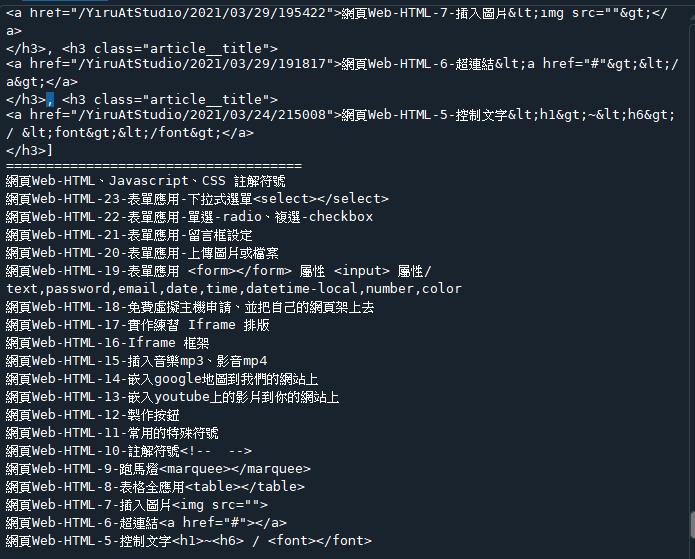
Yiru@Studio - 關於我 - 意如