本章簡單介紹什麼是 RAG(Retrieval Augmented Generation),為什麼它可以讓 LLM 像考試OpenBook 一樣:先查資料再回答問題。
了解 RAG 怎麼提升LLM 回答的品質,減少亂掰、避免知識過期。以及適合用 RAG 的情況。
概念介紹
RAG 概念是
在充滿特定domain知識的向量資料庫中,搜尋出數個與問題相關的答案,並請LLM 依據答案回答問題。
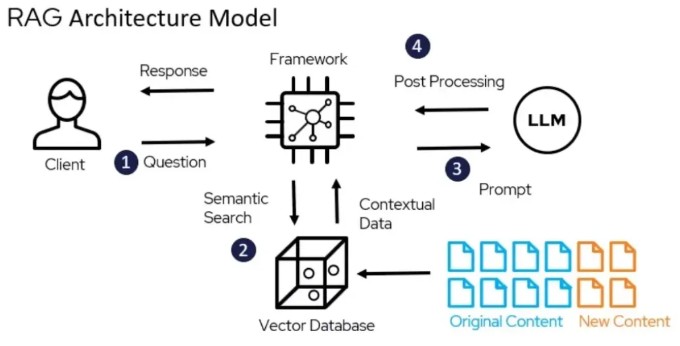
流程如下:
- 使用者輸入問題
- 問題轉成向量,在向量資料庫中找到與問題最相關的文件
- 把使用者輸入問題及文件交給 LLM
- LLM 依據文件產生答案,回傳給使用者
可以注意到右下角的文件(Content) 有不同顏色,代表你可以隨時在資料庫裡面加上新的知識,讓LLM 以最新的資料回答問題。免除了以往預訓練好的LLM 受限於資料集內容,而無法回答訓練完成時間點以後的知識的問題。
要完成一個RAG 架構會有以下步驟,本文也會照這個步驟實作:
- 釐清需求
- 選用向量資料庫
- 選擇Embedding Model
- 產生向量資料
- 結合LLM + RAG
釐清需求
這系列的文章假設我們營運一個電商網站,網站服務的是使用繁體中文的客群。系統流程大概可以分幾個模組,例如:會員註冊、下單購物、物流追蹤、退貨退款、客服申訴。
我們希望AI 客服可以針對不同的模組,產生更精確地回答,所以規劃使用具有payload功能 (附加在向量上的結構化資料) 的Qdrant,除了單純向量的搜尋之外,也可以自訂一些標籤,在後續查詢資料庫可以下filter 指定標籤,以找出更精確的參考資料。
儲存的資料結構類似:
{
"id": 1,
"vector": [0.12, 0.98, ...], // 參考資料轉換成的向量
"payload": {
"title": "哈利波特:神秘的魔法石",
"author": "J.K.羅琳",
"book": "1"
}
}舉個例子,假設我要想知道在哈利波特第一集裡面,有沒有用到葛萊芬多寶劍。如果沒有payload,RAG 可能會找到其他集數的資料,LLM 再產生幻覺給我。有了payload 在下搜尋條件就可以指定payload.book = 1 ,將RAG 搜尋的資料範圍限縮在第一集裡面。
選用向量資料庫 : Qdrant
Qdrant 主打以下幾個特點
- Open Source
- 高準確度、低延遲
- 支援 payload 篩選: 除了向量,還可以自訂屬性,用更精準地filter 找到參考資料
- 提供方便整合的 REST API 和 gRPC 接口
- Web UI
使用docker 方式下載並執行容器,看到port 6333通 就代表安裝成功。
docker pull qdrant/qdrant
docker run -d -p 6333:6333 qdrant/qdrant
curl localhost:6333
> {"title":"qdrant - vector search engine","version":"1.16.3","commit":"bd49f45a8a2d4e4774cac50fa29507c4e8375af2"}選擇Embedding Model
Embedding Model 也是一個預訓練好的模型,負責將文字轉換成向量。Embedding Model 對於檢索資料的準確性有很大的影響,因為檢索資料時是使用向量相似度比對,而因為訓練資料的語言差異,最好選用多語言或特定語言的Embedding Model。
感謝已經有大神依照Embedding model 的繁體中文檢索能力做出了排名 (還持續更新到2025/09!!)。因為是免費仔,所以選用微軟開源的 intfloat/multilingual-e5-large
產生向量資料
從IP:6333/dashboard進入Qdrant Web UI,建立一個知識庫(domain) 的collection。要注意Vector configuration 的dimensions 要跟embedding model 的embedding size 一樣。
embedding size 通常在model 的介紹頁面可以找到,也可以用程式試算一段文字,查看輸出的embedding size。
/5c6637ce-873c-469a-b11e-a1449266844a/1769483553.png.png)
然後新增Payload,用type 表示不同模組。
/5c6637ce-873c-469a-b11e-a1449266844a/1769484280.png.png)
接著寫python 處理,將資料轉embedding 並存入Qdrant
from langchain_core.embeddings import Embeddings
from langchain_qdrant import QdrantVectorStore
from uuid import uuid4
from langchain_core.documents import Document
from sentence_transformers import SentenceTransformer
# 準備文件
document_1 = Document(
page_content="賣家在7-11寄出商品,需要3~4天抵達取貨門市",
metadata={"type": "物流追蹤"},
)
document_2 = Document(
page_content="賣家請芙莉蓮運送商品,馬上就可以抵達指定地址",
metadata={"type": "物流追蹤"},
)
document_3 = Document(
page_content="要確認目前物流狀態,需要將物流單號翻譯成爬說語,交給佛地魔",
metadata={"type": "物流追蹤"},
)
document_4 = Document(
page_content="如果商品一直沒有抵達,可能是被星之卡比吃掉",
metadata={"type": "物流追蹤"},
)
document_5 = Document(
page_content="買家收到商品後,發現有問題7天內可以無條件退貨退款",
metadata={"type": "退貨退款"},
)
document_6 = Document(
page_content="注意退款處理專員是否為兩津勘吉,該專員可能會偷偷A走你的退款",
metadata={"type": "退貨退款"},
)
document_7 = Document(
page_content="退款將統一使用日幣,將於賣家收到退貨商品後,三千個工作天內完成退款",
metadata={"type": "退貨退款"},
)
document_8 = Document(
page_content="若退貨包裹遺失,請聯絡高速婆婆處理",
metadata={"type": "退貨退款"},
)
documents = [document_1, document_2, document_3, document_4,
document_5, document_6, document_7, document_8]
# 初始化embedding model
embedding_model = SentenceTransformer('intfloat/multilingual-e5-large')
class E5Embedding(Embeddings):
def embed_query(self, text: str):
return embedding_model.encode(f"query: {text}", normalize_embeddings=True).tolist()
def embed_documents(self, texts):
return [
embedding_model.encode(f"passage: {t}", normalize_embeddings=True).tolist()
for t in texts
]
# 初始化
vector_store = QdrantVectorStore.from_existing_collection(
embedding=E5Embedding(),
collection_name="domain",
url=qdrant_url,
)
# 給每一個document uuid
uuids = [str(uuid4()) for _ in range(len(documents))]
vector_store.add_documents(documents=documents, ids=uuids)
vector_store.client.close()就可以去Qdrant dashboard 上看,資料確實存入
/5c6637ce-873c-469a-b11e-a1449266844a/1770714214.png.png)
如此一來,我們的知識向量資料庫已經準備好了。下一篇文章,再來實作 RAG 的流程
references:
第十四篇:向量資料庫(Vector Database)的介紹與設置 - iT 邦幫忙::一起幫忙解決難題,拯救 IT 人的一天
生成式AI(9) — 向量資料庫簡介 - Tako - Medium
【Day 18】Embeddings 的家 - 向量資料庫 - iT 邦幫忙::一起幫忙解決難題,拯救 IT 人的一天
第十五篇:詞嵌入模型(Embedding Model)的設置與使用 - iT 邦幫忙::一起幫忙解決難題,拯救 IT 人的一天