一開始先說這篇,如果基本的Group 跟 基本的SQL函式還不會的話會看不懂喔
前面先消過毒後我們就繼續往下看吧
我先讓各位看今天我先select 出來的資料
select SO.EmployeeID as empid,
HE.FirstName as firstname,
HE.LastName as lastname,
YEAR(SO.OrderDate) as orderyear,
COUNT(SO.EmployeeID) as ordercnt
from Sales.Orders SO
inner join HR.Employees HE
on SO.EmployeeID = HE.EmployeeID
group by SO.EmployeeID,HE.FirstName,HE.LastName,YEAR(SO.OrderDate)
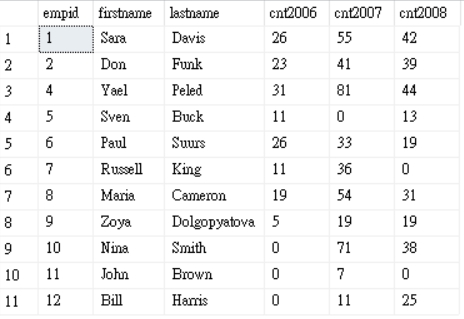
那如果今天有個需求是,我需要把OrderYear變成欄位來顯示
如上圖這樣,該怎麼做?
這時候我們會使用 PIVOT 這個關鍵字
PIVOT ( <aggregation function>(<column being aggregated>)
FOR [<column that contains the values that will become column headers>]
IN ( [first pivoted column], [second pivoted column], ... [last pivoted column]) ) AS <alias for the pivot table> <optional ORDER BY clause>;
這段是由MSDN 提供
可以看到使用方式就是 PIVOT 內放 運算集合
For 一個你要翻轉的欄位
IN 你對應到select 的欄位
As 為這新的PIVOT Table命名
於是乎我們就寫了這樣的Code
select empid,firstname,lastname,ISNULL([2006],0) as cnt2006 , ISNULL([2007],0) as cnt2007 , ISNULL([2008],0) as cnt2008
from(
select SO.EmployeeID as empid,
HE.FirstName as firstname,
HE.LastName as lastname,
YEAR(SO.OrderDate) as orderyear,
COUNT(SO.EmployeeID) as ordercnt
from Sales.Orders SO
inner join HR.Employees HE
on SO.EmployeeID = HE.EmployeeID
group by SO.EmployeeID,HE.FirstName,HE.LastName,YEAR(SO.OrderDate)
) as D
PIVOT(Sum(ordercnt) for orderyear
in([2006],[2007],[2008])
)as pvt
他其實就是再select 一次並透過子查詢、PIVOT的方式
重新做出一個PIVOT過後的Table
這個IN 的對應,就是外層Select 的欄位對應
結果就會如下圖
前陣子參加公司的WorkShop
才知道這個語法的,不然之前真的是完全沒用過
也因為覺得神奇所以把這個寫上來
以便我以後自己觀看,並且自己寫過文章後更是再記憶一次
提供給正在學SQL的人一起學習