Retrieve tesla charger point [detail] using geohash based method.
geohash、tesla charger、plugshare.com
在上一集的技術網誌中,我們提到了使用geohash為概念的方式取得充電站的代號(第2欄)與經緯度(第3、4欄),抓取結果請參考下圖。

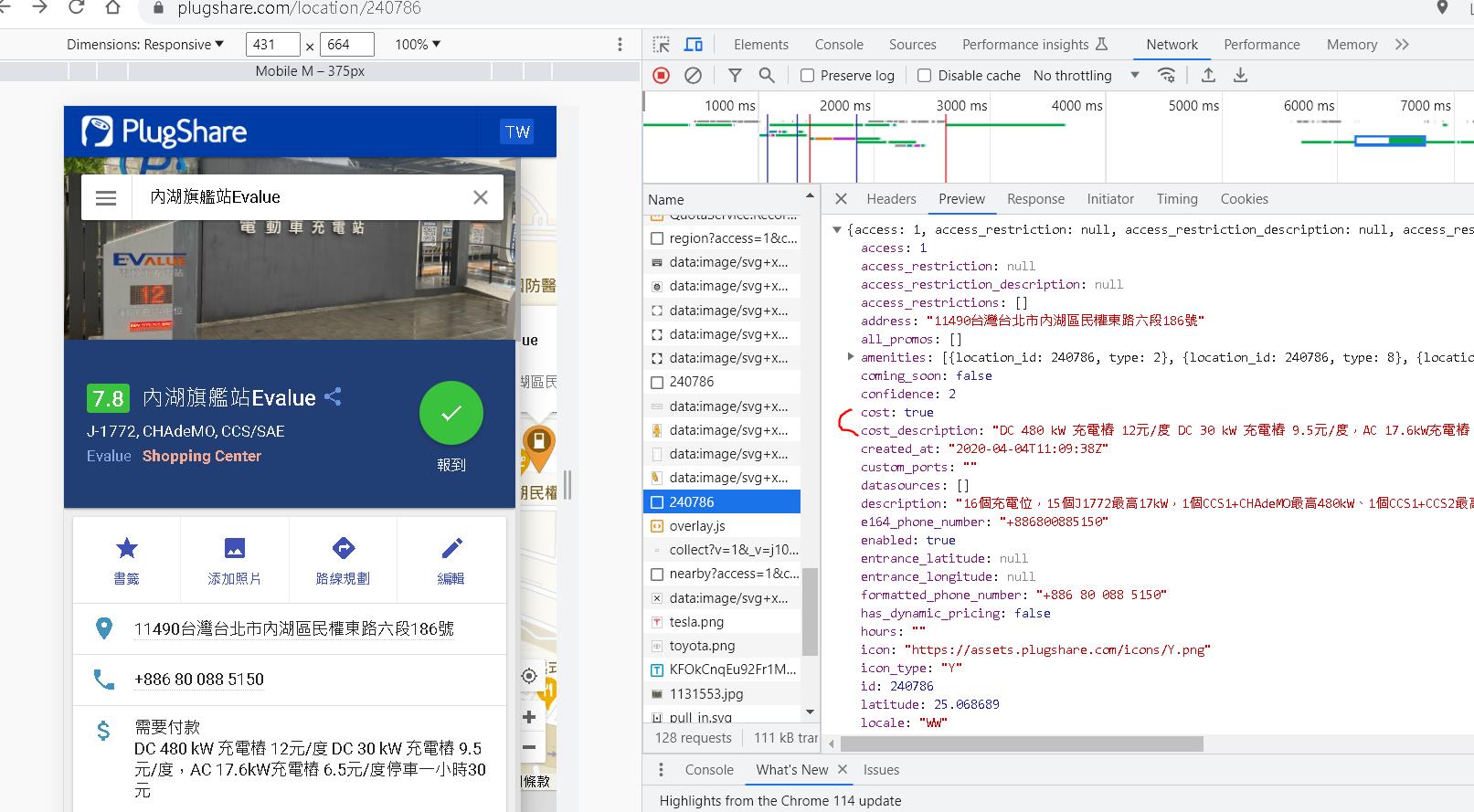
作者後續又接到另一個任務是要取得每個充電站的樁數、各類型插座數、是否收費以及收費資訊,也就是如下圖的內容。
由於上集我們已經取得每一個充電站的唯一id值與對應細節頁面的url,藉由輸入url觀察chrome的f12模式,可以發現到其中有一個request api是取得細節,可以在preview可以觀察到回傳的Json內容。

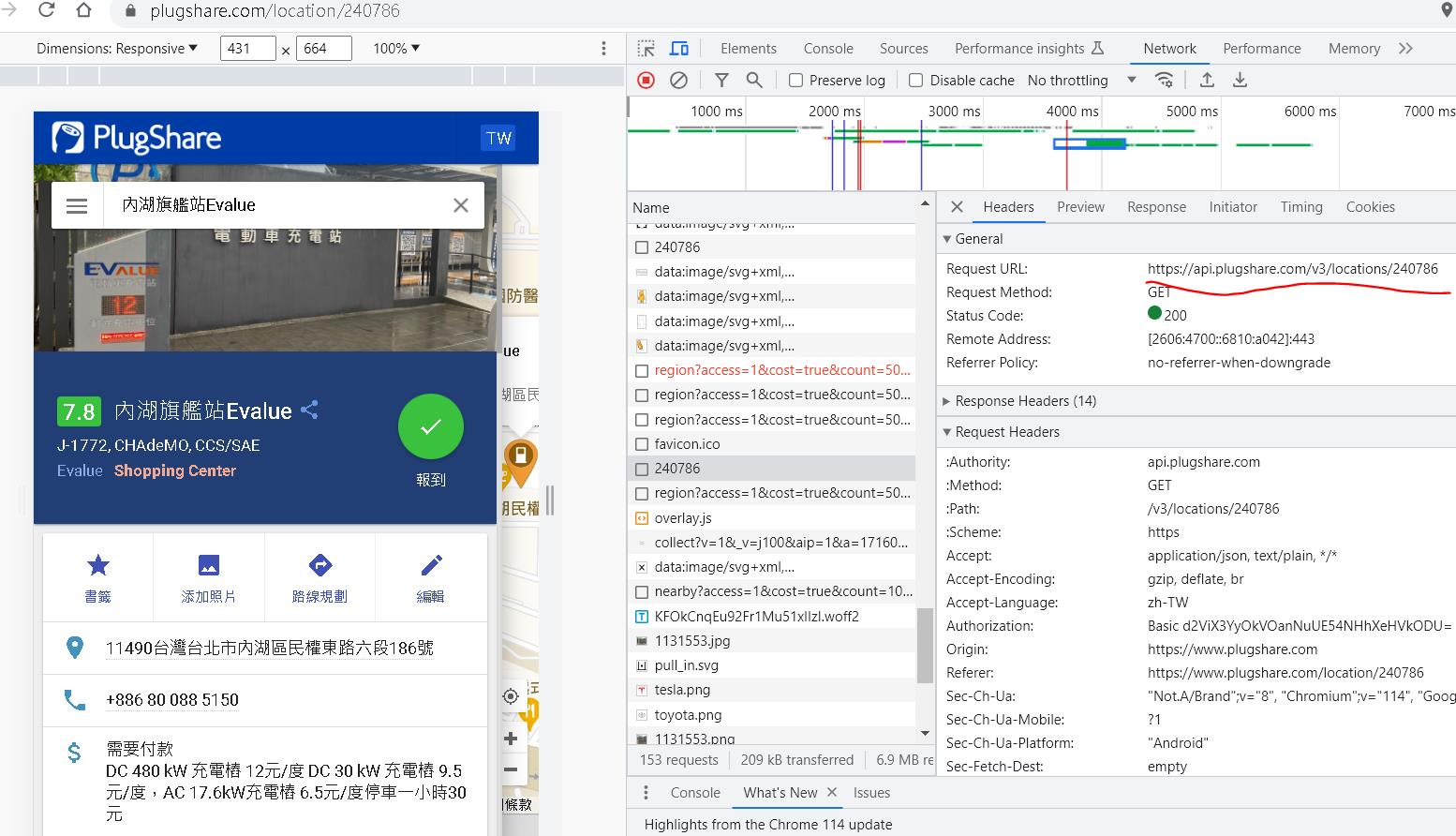
接下來開始分析Json的內容。
我們可以從Json的內容觀察,該站有20支充電樁(label為stations下的陣列0~19),數量可透過點選更多內容的icon驗證。
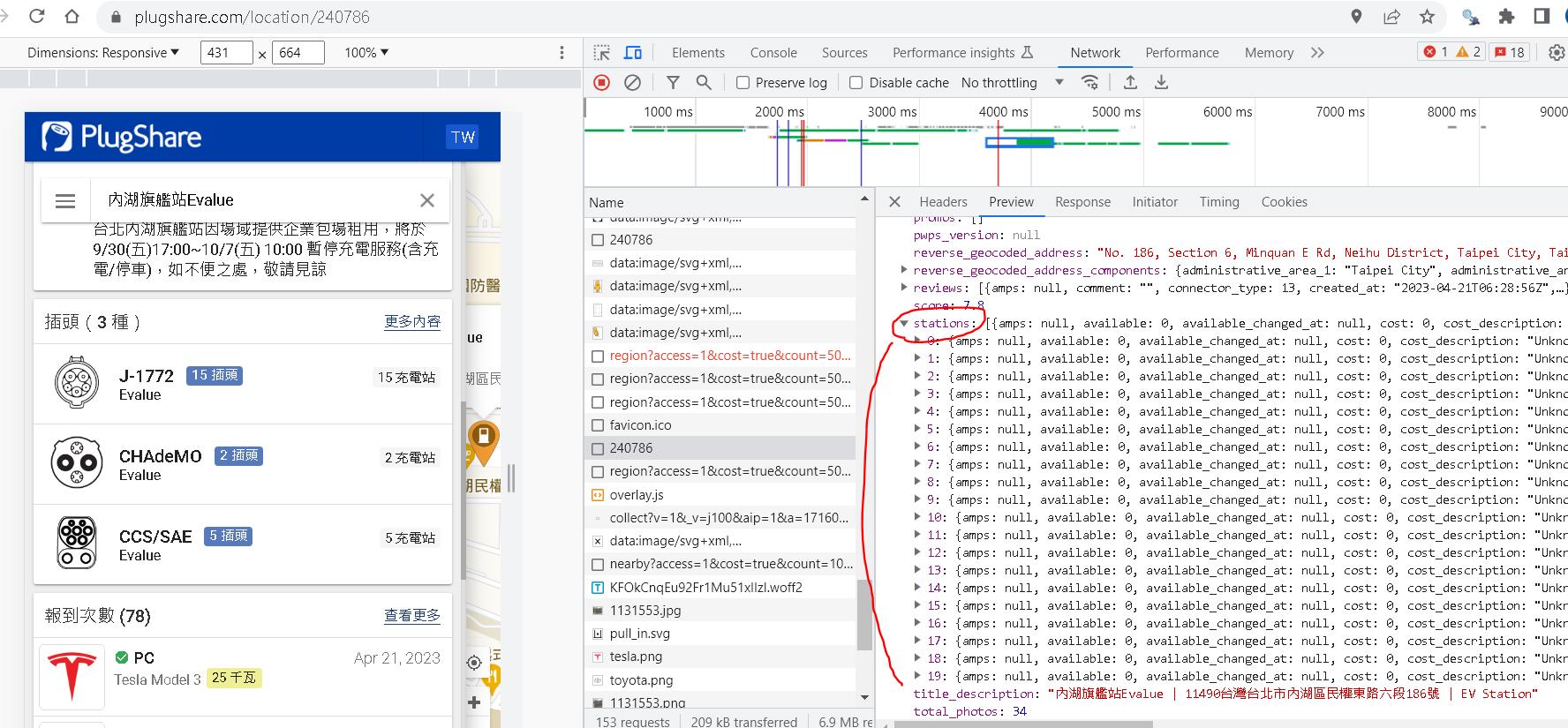
往下點開可以發現有outlets選項,以我們的例子來看,陣列index第17個樁有兩個插座,分別是ChAdeMO與COMBO各一個。
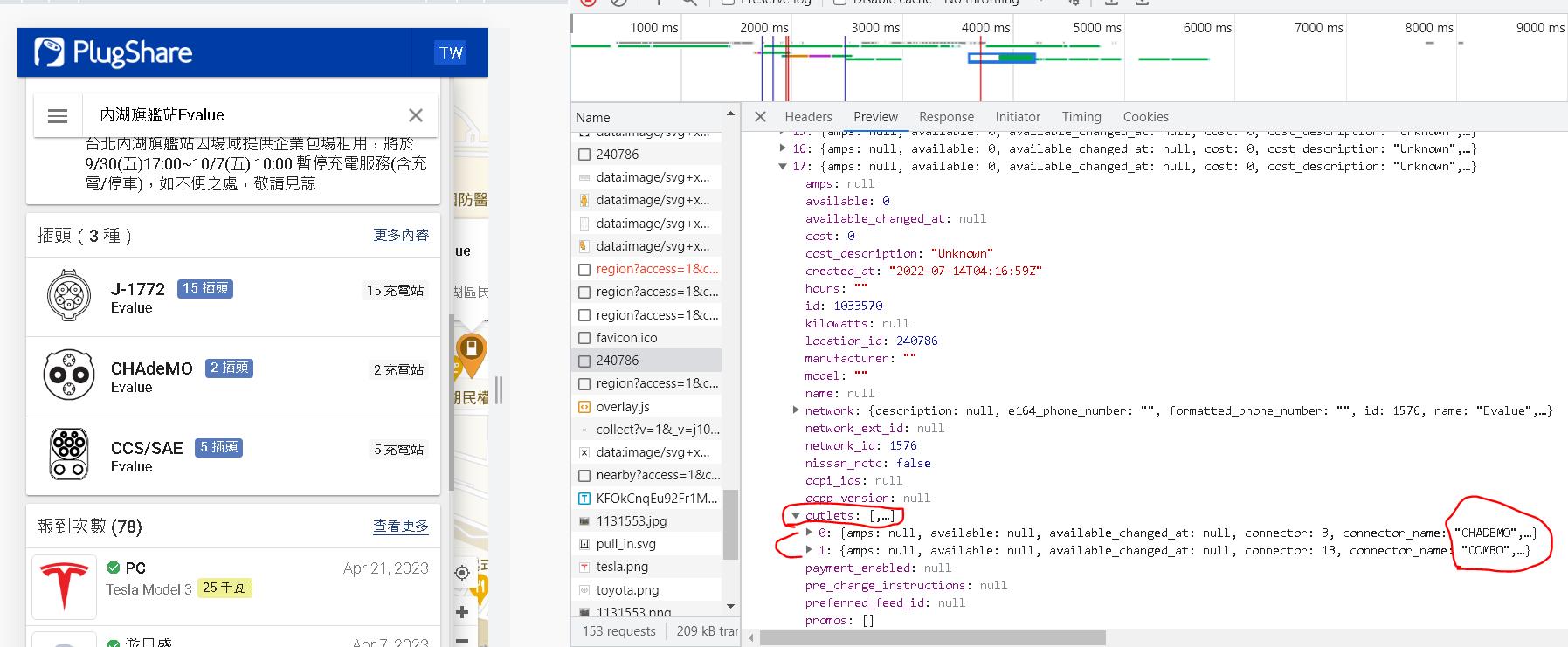
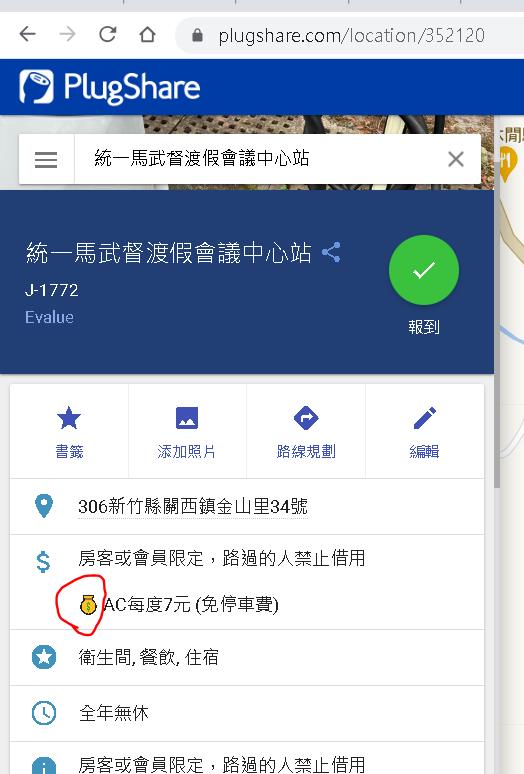
收費資訊就比較簡單了,就是在amenities label下的cost與cost_description label。
了解了整個回傳結構後,便可以開始進行爬網取資料parsing。
與上集的方式一樣,需要使用cloudscraper的套件進行爬網,且須注意帶入的參數,避免被plugshare擋下來。
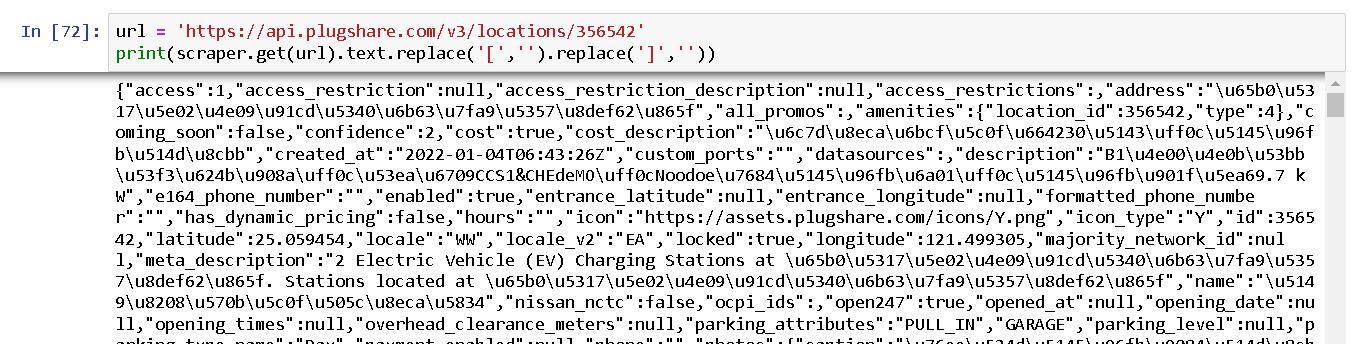
我直接讀取上集爬完取得的檔案,取出每個站的唯一id值,整成https://api.plugshare.com/v3/locations/{id},進行request。
中間需要解決兩個問題,一個是網站回傳的中文為unicode的問題,另一個是回傳表情符號的問題。
中文unicode問題可用python encode decode解決,表情符號會造成轉換失敗,需要額外處理將他轉為?號(str.encode('utf-8','replace'))。
2023年11月重新review時發現網站回吐編碼已變成utf-16,包含utf-16 emotion符號,作者修改程式為了之後產生csv檔,將非utf-8的編碼全部去除
str = str.encode('utf-8').decode("unicode_escape")
str = re.sub('[\ud800-\udfff]+', '', str)
剩下的就是parsing json的苦功而已,我是習慣用關鍵字去split,靠著左切右切直接把內容切出來。
import requests
import cloudscraper
import cfscrape
import time
import re
#使用cloudscraper準備request header#
session = requests.Session()
session.headers = {
'browser' :'firefox', #Cloudflare Error 1020解決 #參數替換 firefox, chrome
'Authority' :'api.plugshare.com',
'Method' :'GET',
'Path' :'/v3/locations/356542',
'Scheme' :'https',
'Accept' :'application/json, text/plain, */*',
'Accept-Encoding' :'gzip, deflate, br',
'Accept-Language' :'zh-TW',
'Authorization' :'Basic d2ViX3YyOkVOanNuUE54NHhXeHVkODU=',
'Origin' :'https://www.plugshare.com',
'Referer' :'https://www.plugshare.com/location/356542',
'Sec-Ch-Ua' :'"Google Chrome";v="113", "Chromium";v="113", "Not-A.Brand";v="24"',
'Sec-Ch-Ua-Mobile' :'?1',
'Sec-Ch-Ua-Platform' :'"windows"',#windows,Android
'Sec-Fetch-Dest' :'empty',
'Sec-Fetch-Mode' :'cors',
'Sec-Fetch-Site' :'same-site',
'User-Agent' :'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Mobile Safari/537.36'}
scraper = cloudscraper.create_scraper(delay=10, sess=session, browser={'browser': 'firefox','platform': 'windows','mobile': False})#, browser={'browser': 'chrome','platform': 'windows','desktop': True}
#讀檔and取得tesla充電站id#
teslaPointIdList = []
f = open('D:/workSpaceReunion/dataInOutput/plugShareDataParsing/step3_requestAPIResultParsing/teslaRequestAPIResultParsing.csv', 'r', encoding="utf-8")
line = f.readline()
#teslaPointId.append()
while line:
#print(line)
if line.strip() != '': #strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符, 這裡判斷如果是空行不處理
teslaPointId = line.split(",")[1]
teslaPointIdList.append(teslaPointId)
#print(teslaPointId)
line = f.readline()
f.close()
#依據teslaPointId開始爬網parsing#
chargerDetailResultList = []
for teslaId in teslaPointIdList:
#進入正題
url = 'https://api.plugshare.com/v3/locations/' + teslaId
#print(scraper.get(url).text.replace('[','').replace(']',''))
apiResponseJsonStr = scraper.get(url).text
#print(apiResponseJsonStr) #檢查是不是又被當作是機器人
strSplit = str.split(apiResponseJsonStr, "connector_name\":\"")
first = True
chargerTypeDict = dict()
for line in strSplit:
if first:
first = False#要跳過第一個
#利用跳過的機會取得cost資訊
if "\"amenities\":" in line: #有資訊才執行
strSplitAmenities = str.split(line, "\"amenities\":")
amenities = strSplitAmenities[1]
strSplitCreatedAt = str.split(amenities, ",\"created_at\":")
createdAt = strSplitCreatedAt[0]
strSplitCost = str.split(createdAt, "\"cost\":")
cost = strSplitCost[1]
strSplitCostDes = str.split(cost, ",\"cost_description\":")
needCost = strSplitCostDes[0]
#轉碼,並將,轉換掉避免切csv時出問題
cost_description = strSplitCostDes[1].encode('utf-8').decode("unicode_escape").replace("\"","").replace(",","_").replace("\n","_").replace("\r","_")
#cost_description = strSplitCostDes[1].encode('utf-8','replace').decode("utf-8").replace("\"","").replace(",","_").replace("\n","_").replace("\r","_")
##移除utf-16 emotion符號 https://stackoverflow.com/questions/67854195/removing-part-of-string-starting-with-ud
cost_description = re.sub('[\ud800-\udfff]+', '', cost_description)#print(needCost)
#print(cost_description)
else:
needCost = ""
cost_description = ""
else:
strSplitIn = str.split(line, "\",\"connector_type\"")
chargerType = strSplitIn[0]
if chargerType not in chargerTypeDict:
chargerTypeDict[chargerType] = 1
else:
chargerTypeDict[chargerType] = chargerTypeDict[chargerType] + 1
#print(strSplitIn[0])
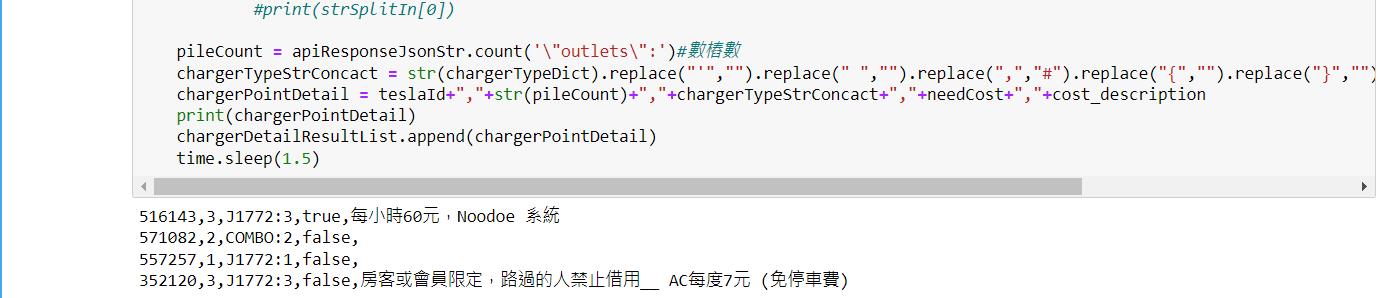
pileCount = apiResponseJsonStr.count('\"outlets\":')#數樁數
chargerTypeStrConcact = str(chargerTypeDict).replace("'","").replace(" ","").replace(",","#").replace("{","").replace("}","")
chargerPointDetail = teslaId+","+str(pileCount)+","+chargerTypeStrConcact+","+needCost+","+cost_description
print(chargerPointDetail)
chargerDetailResultList.append(chargerPointDetail)
time.sleep(1.5)
#寫入檔案#
chargerDetailPath = 'D://workSpaceReunion/dataInOutput/plugShareDataParsing/step4_requestChargerDetail/chargerDetail.csv'
with open(chargerDetailPath, 'w', encoding='utf-8') as f:
#f.write('\ufeff')#Utf8-BOM
#lines = ['Hello World\n', '123', '456\n', '789\n']
f.write('\n'.join(chargerDetailResultList))在程式的最後我有在打每個api之間sleep1.5秒,因為實驗過程中我發現即使我的header組成可以成功突破網站限制使用api,但打太快打到一半還是會被擋下來視為bot,1.5秒是我實驗過後可突破的最短間隔。
執行結果如下圖:
最後我們寫程式將上集和下集的內容join起來,變成一個完整的充電站爬網資訊。
#讀取上集充電樁主檔#
teslaPointMasterDict = dict()
f = open('D:/workSpaceReunion/dataInOutput/plugShareDataParsing/step3_requestAPIResultParsing/teslaRequestAPIResultParsing.csv', 'r', encoding="utf-8")
line = f.readline()
#teslaPointId.append()
while line:
#print(line)
if line.strip() != '': #strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符, 這裡判斷如果是空行不處理
teslaPointId = line.split(",")[1]
teslaPointMasterDict[teslaPointId] = line.replace("\n","").replace("\r","")
#print(teslaPointId)
line = f.readline()
f.close()
#讀取本篇結果, 並使用站點id join, 用上集的主檔dict判斷,若本篇結果存在則Join起來#
chargerDetailPath = 'D://workSpaceReunion/dataInOutput/plugShareDataParsing/step4_requestChargerDetail/chargerDetail.csv'
chargerDetailResultList = []
f = open(chargerDetailPath, 'r', encoding="utf-8")
line = f.readline()
#teslaPointId.append()
while line:
if line.strip() != '': #strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符, 這裡判斷如果是空行不處理
teslaPointId = line.split(",")[0]
teslaPointPileCnt = line.split(",")[1]
if teslaPointPileCnt != "0":
seqs = line.split(",")[1:]
seq = ','.join(seqs)
teslaPointMasterDict[teslaPointId] = teslaPointMasterDict[teslaPointId] + ',' + seq.replace("\n","").replace("\r","")
print(teslaPointMasterDict[teslaPointId])
#將結果pop出來至list
chargerDetailResultList.append(teslaPointMasterDict[teslaPointId])
else:
print(teslaPointId + ' EMPTY')
teslaPointMasterDict[teslaPointId] = line.replace("\n","").replace("\r","")
#print(teslaPointId)
line = f.readline()
f.close()
#存檔#
chargerDetailFinalPath = 'D://workSpaceReunion/dataInOutput/plugShareDataParsing/step5_joinMasterDetail/chargerDetailJoinFinal.csv'
with open(chargerDetailFinalPath, 'w', encoding="utf-8") as f:
f.write('\ufeff')#Utf8-BOM
#lines = ['Hello World\n', '123', '456\n', '789\n']
f.write('\n'.join(chargerDetailResultList))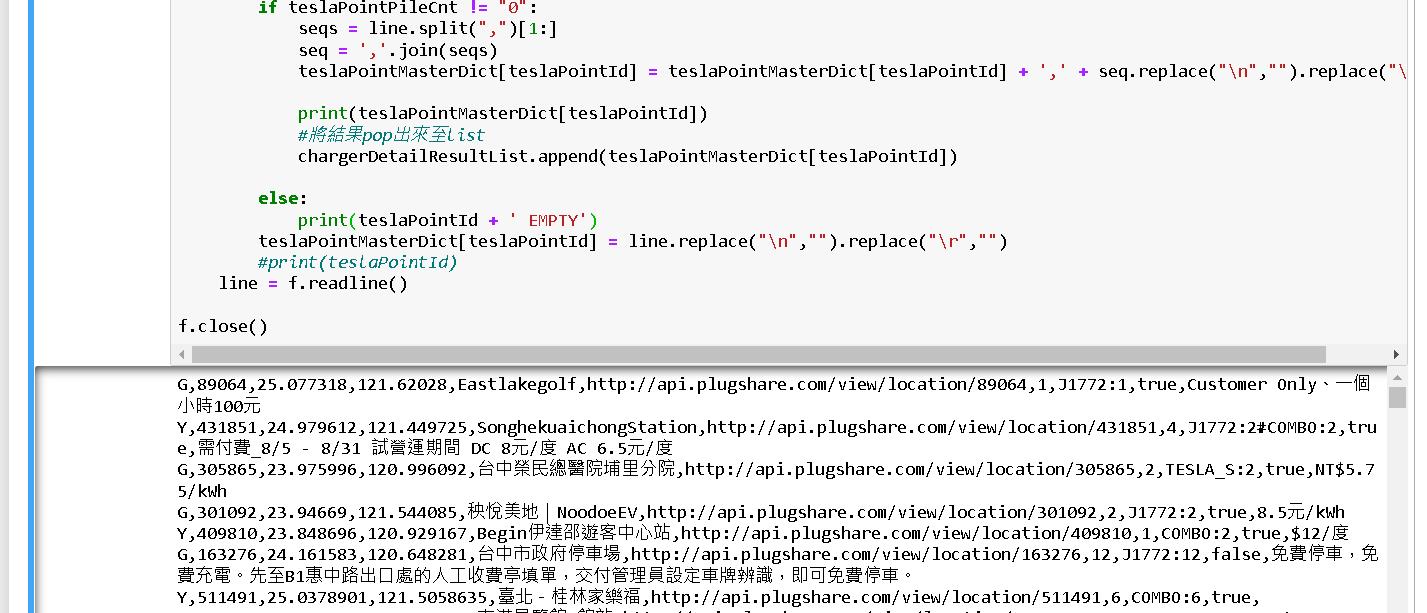

目前為止上集和下集的程式都可以正確地爬取充電站資訊,希望plugshare不要太快改版,不然每次都要改爬網程式太累了。