Automatically load local file to BigQuery table when file is uploaded to Bucket/Cloud Storage。
Implementing by Java、Eclipse and Maven。
環境與工具準備如下:
- 申請一個Google Cloud免費環境。
- 準備一個Ubuntu環境,安裝gsutil,用於與GCP(Google Cloud Platform)溝通(shell script部署Cloud Function與上傳檔案到Cloud Storage)。
- 安裝Maven套件的Eclipse,可下載Eclipse後自行加載Maven設定。
架構與說明
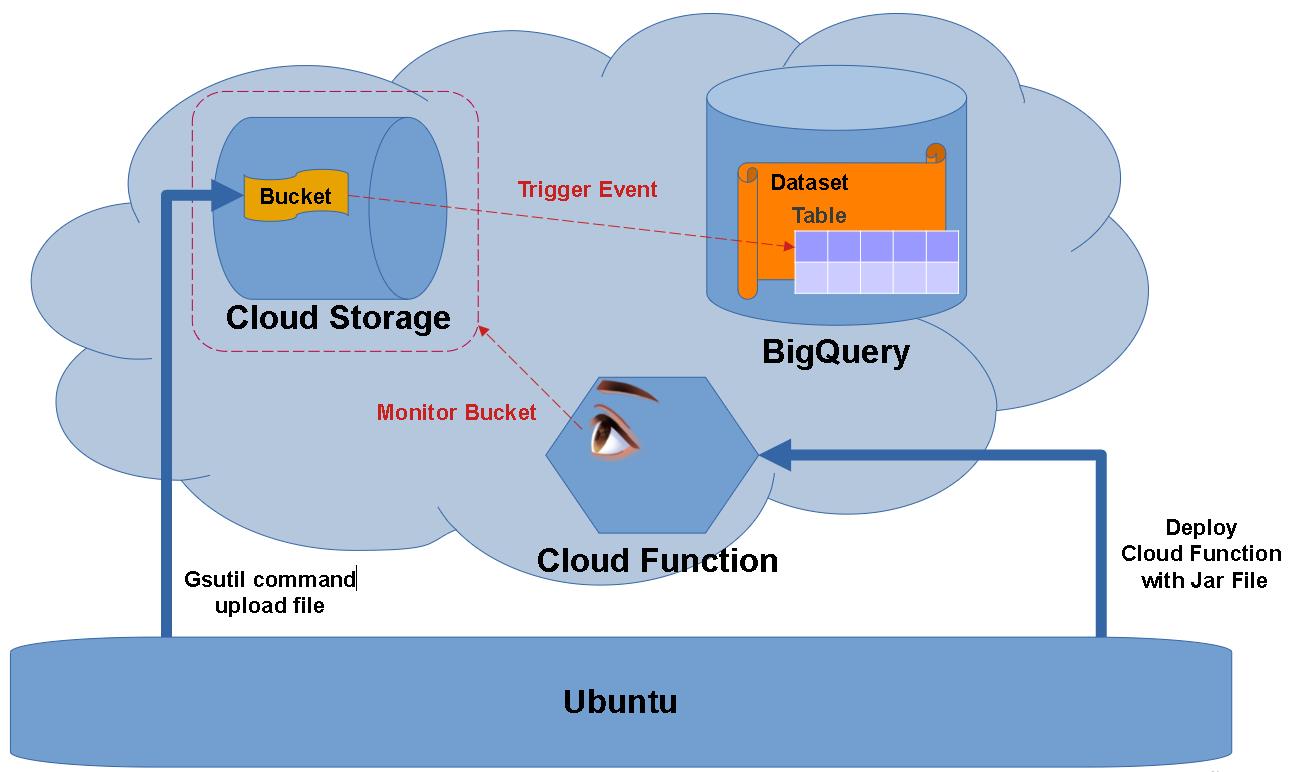
簡單說明要實作的scenario如下圖:
從地端的ubuntu server將parquet檔案下gstuil的指令上傳到指定的Bucket內,同時撰寫Cloud Function Event監控Bucket是否有檔案上傳,上傳完畢後自動將資料引入BigQuery 的table。
實作時所需要安裝的素材如下:
安裝Gsutil:https://cloud.google.com/storage/docs/gsutil_install#linux。
Eclipse與Maven下載:https://mirror.kakao.com/eclipse/technology/epp/downloads/release/2022-12/R/eclipse-java-2022-12-R-win32-x86_64.zip、https://dlcdn.apache.org/maven/maven-3/3.8.7/binaries/apache-maven-3.8.7-bin.zip。
其實GCP也有提供可以從地端server直接連向bigquery的table的code,但官方的建議是每次10MB以下的檔案這樣做(https://cloud.google.com/bigquery/docs/batch-loading-data),但一般企業資料上雲這件事情原本就是為了跑大數據的計算了,在地端的檔案通常不會小到哪裡去,要切成10MB再使用會產生一堆碎檔,因此採取官方的建議選擇先上傳到cloud storage再轉進到bigquery的實作方式,不過官方也有說用這種方式時檔案大小建議每個檔案不要大於50MB(等於還是間接限制你的單檔大小,不過至少比10MB好多了),否則可能會出現資源耗盡的問題(https://cloud.google.com/bigquery/docs/loading-data-cloud-storage-parquet)。


看完架構與限制,接下來要執行的步驟如下,依序分小節說明:
建立一個Cloud Storage的Bucket與BigQuery的table、撰寫Cloud Function並部屬、上傳parquet檔案觸發event寫入BigQuery。
在最後面,會有一些額外的補充資訊,我會慢慢補上。
建立一個Cloud Storage的Bucket與BigQuery的table
使用UI建立Buckets。
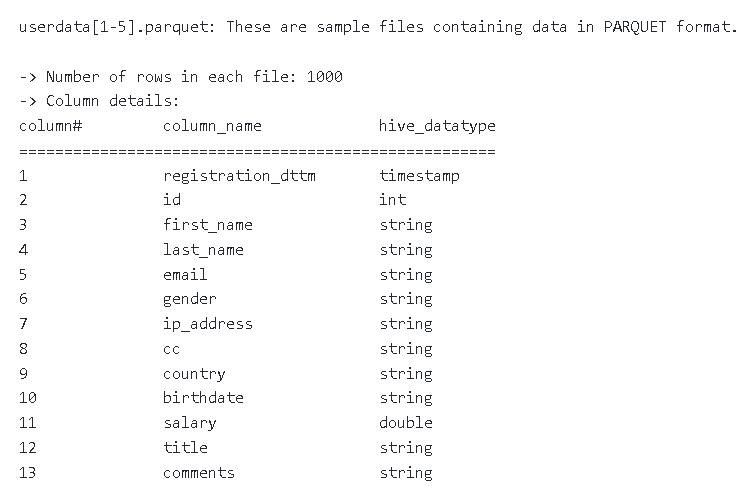
由於parquet檔是Apache Hadoop生態系統中的數據存儲格式,為節省時間,我們在網路上找現有的公開parquet檔使用,省去自己產生parquet檔的時間。
parquet檔下載:https://github.com/Teradata/kylo/tree/master/samples/sample-data/parquet
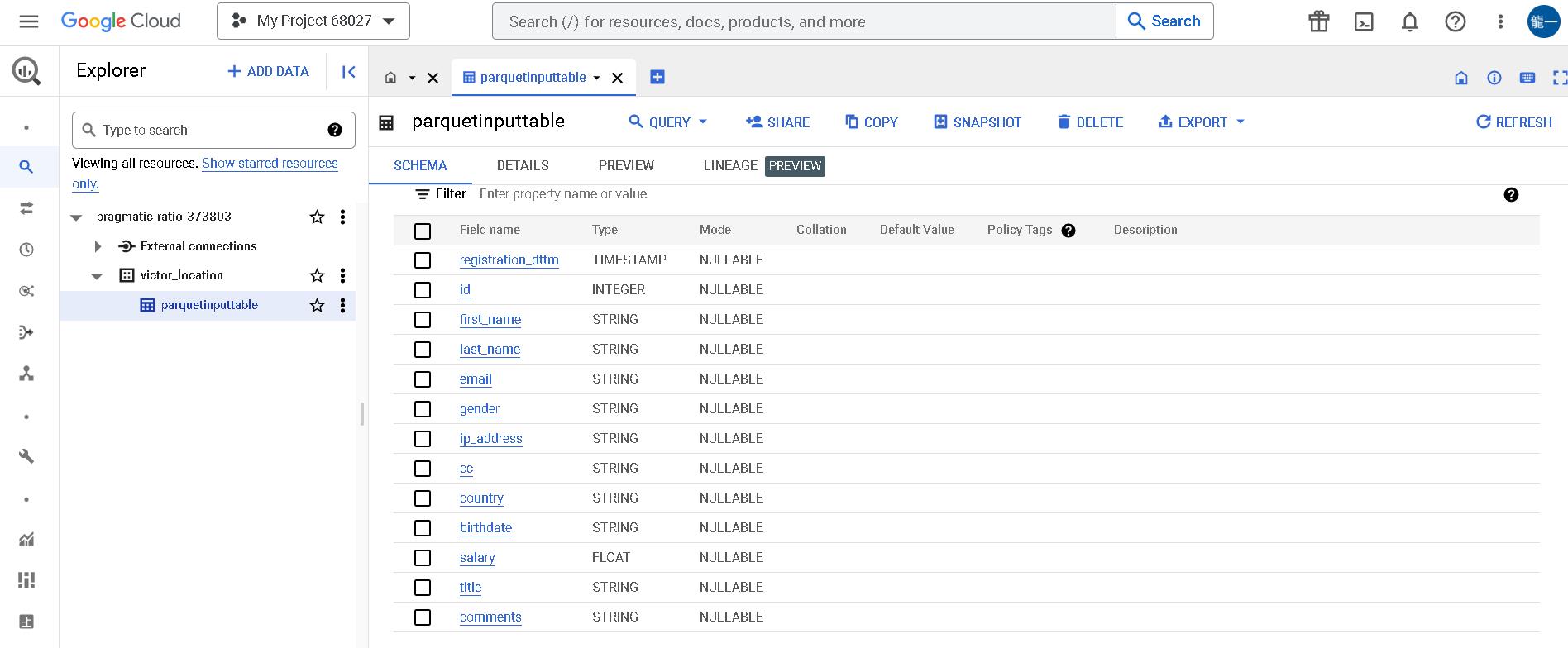
接著我們在BigQuery用UI建立對應的table欄位,以下圖來說,我在pragmatic-ratio-373803這個project id底下建立個一個叫做victor_location的dataset,並在這個dataset底下建立了一個叫做parquetinputtable的資料表。
撰寫Cloud Function並部屬
這段是本篇技術網誌最重要的部分,也是我try最久的地方(主要是因為我沒用過Maven…XD)。
google的github有提供一堆scenario的sample code,可以直接取用做修改,網址如下:
https://cloud.google.com/functions/docs/testing/test-event
pom.xml的設定可以參考https://cloud.google.com/functions/docs/concepts/java-deploy#deploy_from_a_jar
官方寫到,不管你是要export出runnable jar(Uber jar,所有dependency全部包在裡面)或是JAR with external dependencies(乾淨的jar,額外使用classpath引入其他使用到的jar)做部屬,我試過兩者都是支援的,不過官方在乾淨jar的部屬似乎沒有交代清楚,在parsing event時用到的GcsEvent沒有交代是從哪裡來,導致有人用線上部屬時出錯(https://stackoverflow.com/questions/68930132/google-cloud-function-java-lang-noclassdeffounderror-while-following-example-cod),只能用Uber jar(也就是fat jar的方式部屬),本篇是用JAR with external dependencies做部屬,這部分後面我會說明我如何修改。
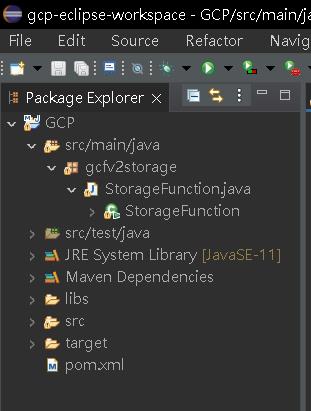
設定好Eclipse結合Maven後,請在建立一個Maven project,結構如下,並產生一個StorageFunction.java(主程式)與pom.xml(lib dependency自動下載引用),主程式與pom.xml內容如下。
package gcfv2storage;
import com.google.cloud.functions.CloudEventsFunction;
import io.cloudevents.CloudEvent;
import java.math.BigInteger;
import java.util.Map;
import java.util.logging.Logger;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.JsonMappingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.google.cloud.bigquery.BigQuery;
import com.google.cloud.bigquery.BigQueryException;
import com.google.cloud.bigquery.BigQueryOptions;
import com.google.cloud.bigquery.Field;
import com.google.cloud.bigquery.FormatOptions;
import com.google.cloud.bigquery.Job;
import com.google.cloud.bigquery.JobInfo;
import com.google.cloud.bigquery.LoadJobConfiguration;
import com.google.cloud.bigquery.Schema;
import com.google.cloud.bigquery.StandardSQLTypeName;
import com.google.cloud.bigquery.StandardTableDefinition;
import com.google.cloud.bigquery.TableDefinition;
import com.google.cloud.bigquery.TableId;
import com.google.cloud.bigquery.TableInfo;
import com.tku.edu.tw.EnhancedGeoHashUtils;
//Define a class that implements the CloudEventsFunction interface
public class StorageFunction implements CloudEventsFunction { //, HttpFunction
private static final Logger logger = Logger.getLogger(StorageFunction.class.getName());
public String datasetName = "victor_location";
public String tableName = "parquetinputtable";
// @Override
// public void service(HttpRequest request, HttpResponse response)
// throws IOException {
// var writer = response.getWriter();
// writer.write("Hello developers!");
// }
//
// Implement the accept() method to handle CloudEvents
@Override
public void accept(CloudEvent event) throws JsonMappingException, JsonProcessingException {
// Your code here
// Access the CloudEvent data payload via event.getData()
// To get the data payload as a JSON string, use:
// new String(event.getData().toBytes())
/**
* Cloud Event data Tuturu: { "kind": "storage#object",
* "id": "lsrcloudstorage/dataToGcp.txt/1672714295288661",
* "selfLink": "https://www.googleapis.com/storage/v1/b/lsrcloudstorage/o/dataToGcp.txt",
* "name": "202212/dataToGcp.txt",
* "bucket": "lsrcloudstorage",
* "generation": "1672714295288661",
* "metageneration": "1",
* "contentType": "text/plain",
* "timeCreated": "2023-01-03T02:51:35.441Z",
* "updated": "2023-01-03T02:51:35.441Z",
* "storageClass": "STANDARD",
* "timeStorageClassUpdated": "2023-01-03T02:51:35.441Z",
* "size": "1966",
* "md5Hash": "YEH+lhIROqHQAwWJj5V++A==",
* "mediaLink": "https://storage.googleapis.com/download/storage/v1/b/lsrcloudstorage/o/dataToGcp.txt?generation=1672714295288661&alt=media",
* "contentLanguage": "en",
* "crc32c": "HmfjrQ==",
* "etag": "CNXGhquyqvwCEAE=" }
*/
logger.info("Event: " + event.getId());
logger.info("Event Type: " + event.getType());
if (event.getData() != null) {
String eventString = new String(event.getData().toBytes());
String geohash = EnhancedGeoHashUtils.encode(23.63983154296875, 121.5911865234375, 12);
logger.info("Cloud Event data: " + eventString);
logger.info("Geohash: " + geohash);
/**
* 自行硬parsingjson string
String eventArr[] = eventString.replace("\r", "").replace("\n", "").replace(" ", "").replace("\",\"", "@~").split("@~");
for(int i=0 ; i<eventArr.length ; i++) {
logger.info("eventArr[i]: "+eventArr[i]);
}
String fileName = eventArr[3].split("\":\"")[1];//name":"userdata1.parquet
String bucketName = eventArr[4].split("\":\"")[1];//bucket":"lsrcloudstorage
String sourceUri = "gs://"+bucketName+"/"+fileName;
logger.info("sourceUri: " + sourceUri);
*/
ObjectMapper mapper = new ObjectMapper();
Map<String, String> map = mapper.readValue(eventString, Map.class);
String fileName = map.get("name");
String bucketName = map.get("bucket");
String sourceUri = "gs://"+bucketName+"/"+fileName;
logger.info("sourceUri: " + sourceUri);
if(fileName.endsWith(".parquet")) {//parquet檔才處理
/**
* Create BigQuery Table
*/
/*String datasetName = "victor_location";
String tableName = "parquetinputtable";
Schema schema =
Schema.of(
Field.of("stringField", StandardSQLTypeName.STRING),
Field.of("booleanField", StandardSQLTypeName.BOOL));
createTable(datasetName, tableName, schema);*/
/**
* insert BigQuery Table
* String sourceUri = "gs://cloud-samples-data/bigquery/us-states/us-states.parquet";
*/
loadParquet(datasetName, tableName, sourceUri);
} else {
logger.info("File Type not match: " + sourceUri);
}
}
}
/*
* ★ Limitations
* You are subject to the following limitations when you load data into BigQuery from a Cloud Storage bucket:
* ◆ If your dataset's location is set to a value other than the US multi-region, then the Cloud Storage bucket must be in the same region or contained in the same multi-region as the dataset.
* ◆ BigQuery does not guarantee data consistency for external data sources. Changes to the underlying data while a query is running can result in unexpected behavior.
* ◆ BigQuery does not support Cloud Storage object versioning. If you include a generation number in the Cloud Storage URI, then the load job fails.
*
* ★ Input file requirements
* To avoid resourcesExceeded errors when loading Parquet files into BigQuery, follow these guidelines:
* ◆ Keep record sizes to 50 MB or less.
* ◆ If your input data contains more than 100 columns, consider reducing the page size to be smaller than the default page size (1 * 1024 * 1024 bytes). This is especially helpful if you are using significant compression.
*/
public static void loadParquet(String datasetName, String tableName, String sourceUri) {
try {
// Initialize client that will be used to send requests. This client only needs to be created
// once, and can be reused for multiple requests.
BigQuery bigquery = BigQueryOptions.getDefaultInstance().getService();
TableId tableId = TableId.of(datasetName, tableName);
Schema schema =
Schema.of(
Field.of("registration_dttm", StandardSQLTypeName.TIMESTAMP),
Field.of("id", StandardSQLTypeName.INT64),
Field.of("first_name", StandardSQLTypeName.STRING),
Field.of("last_name", StandardSQLTypeName.STRING),
Field.of("email", StandardSQLTypeName.STRING),
Field.of("gender", StandardSQLTypeName.STRING),
Field.of("ip_address", StandardSQLTypeName.STRING),
Field.of("cc", StandardSQLTypeName.STRING),
Field.of("country", StandardSQLTypeName.STRING),
Field.of("birthdate", StandardSQLTypeName.STRING),
Field.of("salary", StandardSQLTypeName.FLOAT64),
Field.of("title", StandardSQLTypeName.STRING),
Field.of("comments", StandardSQLTypeName.STRING));
LoadJobConfiguration configuration =
LoadJobConfiguration.builder(tableId, sourceUri)
.setFormatOptions(FormatOptions.parquet())
.setSchema(schema)
.build();
// For more information on Job see:
// https://googleapis.dev/java/google-cloud-clients/latest/index.html?com/google/cloud/bigquery/package-summary.html
// Load the table
Job job = bigquery.create(JobInfo.of(configuration));
// Blocks until this load table job completes its execution, either failing or succeeding.
Job completedJob = job.waitFor();
if (completedJob == null) {
System.out.println("Job not executed since it no longer exists.");
return;
} else if (completedJob.getStatus().getError() != null) {
System.out.println(
"BigQuery was unable to load the table due to an error: \n"
+ job.getStatus().getError());
return;
}
// Check number of rows loaded into the table
BigInteger numRows = bigquery.getTable(tableId).getNumRows();
System.out.printf("Loaded %d rows. \n", numRows);
System.out.println("GCS parquet loaded successfully.");
} catch (BigQueryException | InterruptedException e) {
System.out.println("GCS Parquet was not loaded. \n" + e.toString());
}
}
public static void createTable(String datasetName, String tableName, Schema schema) {
try {
// Initialize client that will be used to send requests. This client only needs to be created
// once, and can be reused for multiple requests.
BigQuery bigquery = BigQueryOptions.getDefaultInstance().getService();
TableId tableId = TableId.of(datasetName, tableName);
TableDefinition tableDefinition = StandardTableDefinition.of(schema);
TableInfo tableInfo = TableInfo.newBuilder(tableId, tableDefinition).build();
bigquery.create(tableInfo);
logger.info("Table created successfully");
} catch (BigQueryException e) {
logger.info("Table was not created. \n" + e.getMessage());
}
}
public static void main(String[] args) {
}
}<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>GCP</groupId>
<artifactId>GCP</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>GCP</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
</properties>
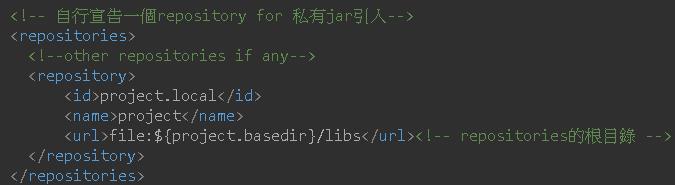
<!-- 自行宣告一個repository for 私有jar引入-->
<repositories>
<!--other repositories if any-->
<repository>
<id>project.local</id>
<name>project</name>
<url>file:${project.basedir}/libs</url><!-- repositories的根目錄 -->
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.google.cloud.functions</groupId>
<artifactId>functions-framework-api</artifactId>
<version>1.0.4</version>
</dependency>
<dependency>
<groupId>io.cloudevents</groupId>
<artifactId>cloudevents-api</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-bigquery</artifactId>
<version>2.20.1</version>
</dependency>
<!-- 正式引入私有jar -->
<dependency>
<groupId>com.example</groupId><!-- repositories根目錄/com/example -->
<artifactId>EnhancedGeohash</artifactId><!-- repositories根目錄/com/example/EnhancedGeohash -->
<version>1.0</version><!-- repositories根目錄/com/example/EnhancedGeohash/1.0/EnhancedGeohash-1.0.jar -->
</dependency>
<!-- 正式引入私有jar -->
</dependencies>
<build>
<plugins>
<!--add classpath in MANIFEST.MF-->
<plugin>
<artifactId>maven-jar-plugin</artifactId>
<version>2.5</version>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>libs/</classpathPrefix>
</manifest>
</archive>
</configuration>
</plugin>
<!--add classpath in MANIFEST.MF-->
<!-- 官方https://cloud.google.com/functions/docs/concepts/java-deploy#deploy_from_a_jar -->
<plugin>
<artifactId>maven-dependency-plugin</artifactId>
<version>2.5</version>
<executions>
<execution>
<id>copy-dependencies</id>
<phase>package</phase>
<goals>
<goal>copy-dependencies</goal>
</goals>
<configuration>
<overWriteReleases>false</overWriteReleases>
<includeScope>runtime</includeScope>
<excludeTransitive>false</excludeTransitive>
<outputDirectory>${project.build.directory}/libs</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>2.5</version>
<executions>
<execution>
<id>copy-resources</id>
<phase>package</phase>
<goals><goal>copy-resources</goal></goals>
<configuration>
<outputDirectory>${project.build.directory}/deployment</outputDirectory>
<resources>
<resource>
<directory>${project.build.directory}</directory>
<includes>
<include>${project.build.finalName}.jar</include>
<include>libs/**</include>
</includes>
<filtering>false</filtering>
</resource>
</resources>
</configuration>
</execution>
</executions>
</plugin>
<!-- 官方https://cloud.google.com/functions/docs/concepts/java-deploy#deploy_from_a_jar -->
</plugins>
</build>
</project>
我取用了官方的sample code做了一些修改,主要調整的幾個地方。
StorageFunction.java中,主要做了幾項修改:
多了if(fileName.endsWith(".parquet")),判斷當Bucket上傳的是parquet檔才做處理。
使用ObjectMapper mapper = new ObjectMapper();做event資訊的parsing,官方原本的code用import functions.eventpojos.GcsEvent;去parsing event的json資訊,但我怎樣都找不到要引用哪個dependency,最後想想反正只是parsing json,用哪個都一樣。
import com.tku.edu.tw.EnhancedGeoHashUtils;是我使用了自訂的私有jar檔,下面的pom調整會說明。
pom.xml中,多了一個私有jar的dependency引入,這也是這次study留下的一個很重要的設定:
將私有jar檔放在Maven project底下的libs資料夾底下的com/example/EnhancedGeohash/1.0/中,同時注意你的jar檔名稱上要有對應的版號1.0。
其實這個設定是可以理解的,因為預設的Maven repository產生的邏輯也是一樣。
可以參考https://gist.github.com/timmolderez/92bea7cc90201cd3273a07cf21d119eb
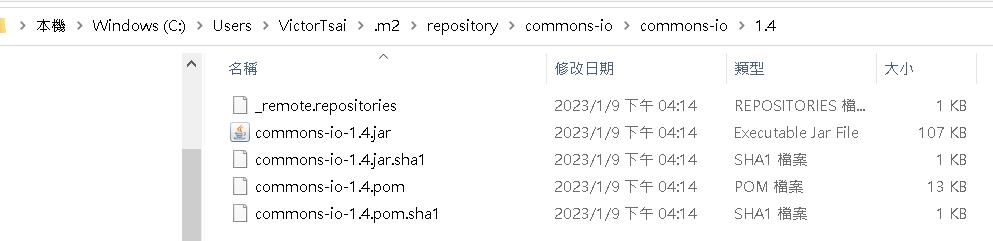

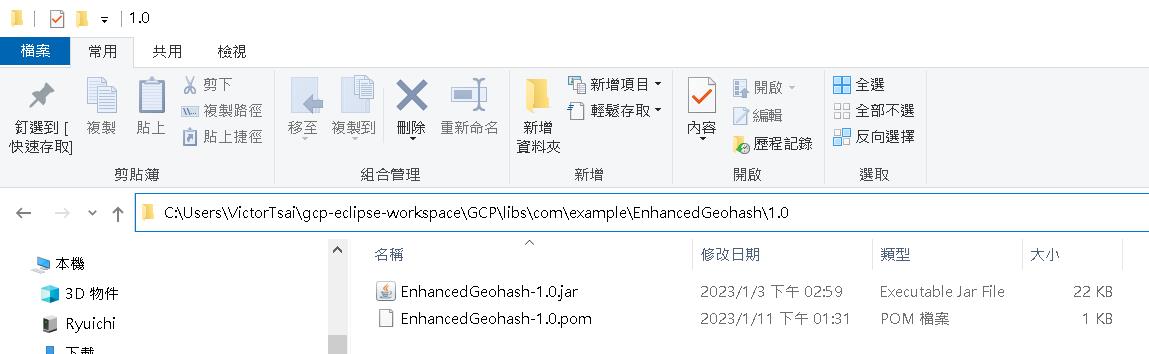
其中EnhancedGeohash-1.0.pom的內容如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>lib</artifactId>
<version>1.0</version>
<description>POM was created from install:install-file</description>
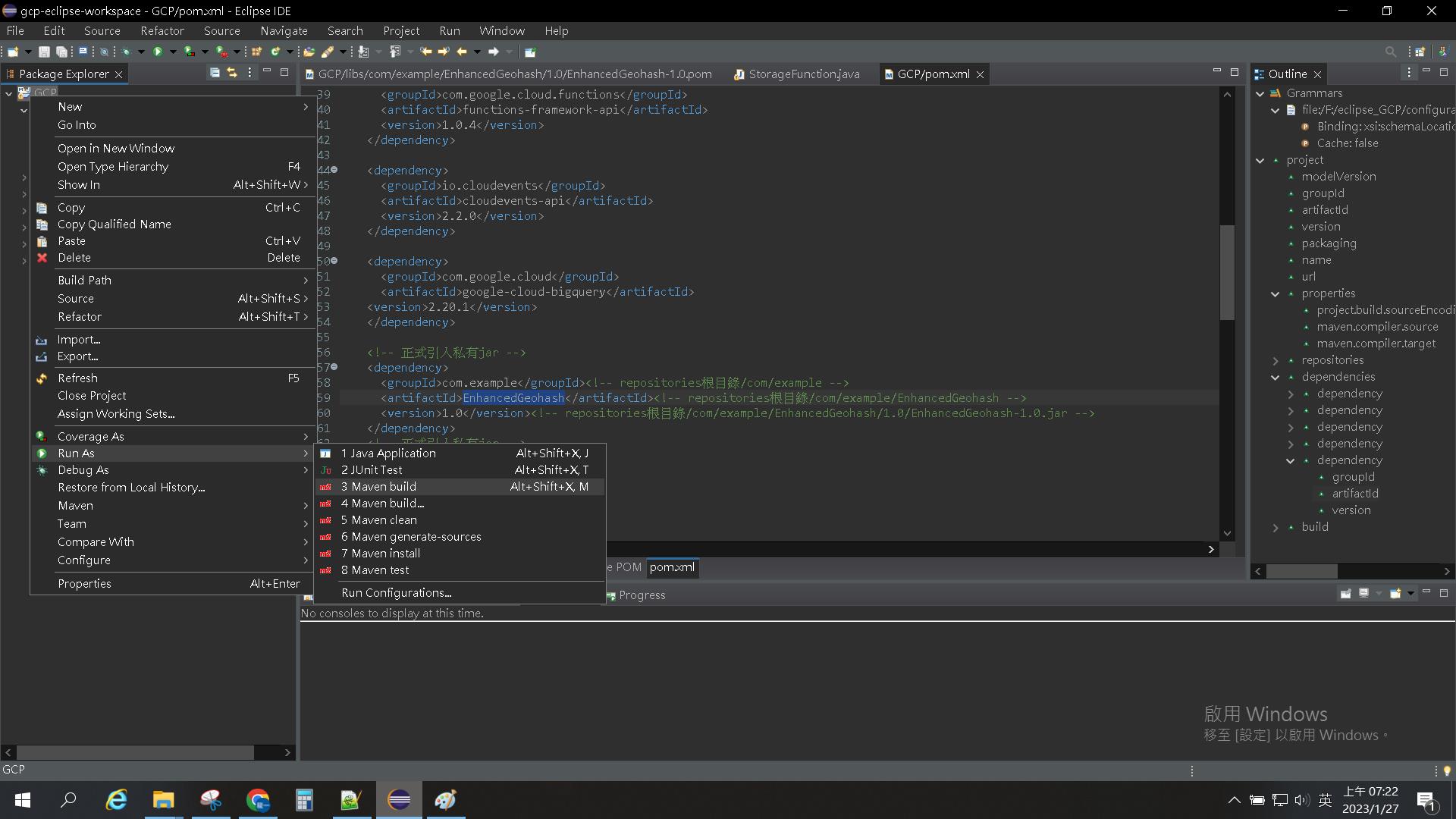
</project>程式和xml都設定好之後,跑Maven build(第二次跑請跑Run Configuration,否則會多一堆設定在下圖第二張左邊紅圈處)
Goals設定clean verify package,按下右下角的Run開始包版。
完成後我們可以在專案路徑下的target/deployment中看到我們包出來的內容。

可以從GCP-0.0.1-SNAPSHOT.jar內的MANIFEST.MF裡看到,有使用到的dependency路徑通通有被引入,包含我們的私有jar檔。

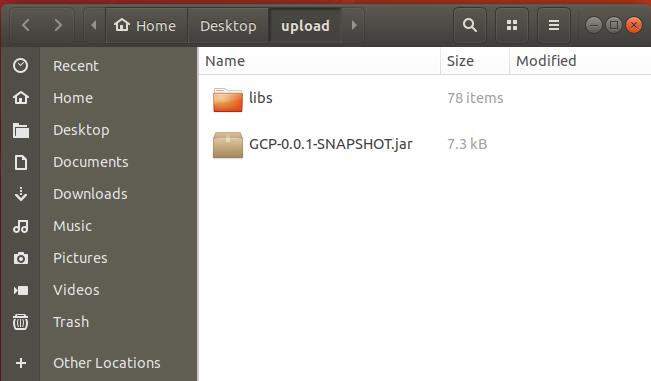
接著我們將我們包好的東西部屬到雲端,部屬可以有兩種方式,一種是使用GCP提供的UI介面,一種是用Gsutil下指令,本篇是要實作自動化,因此採用Gsutil方便之後掛上排程。
我將東西放在本地端的/home/victortsai/Desktop/upload資料夾路徑下,並打開console下指令。
shell code指令如下:
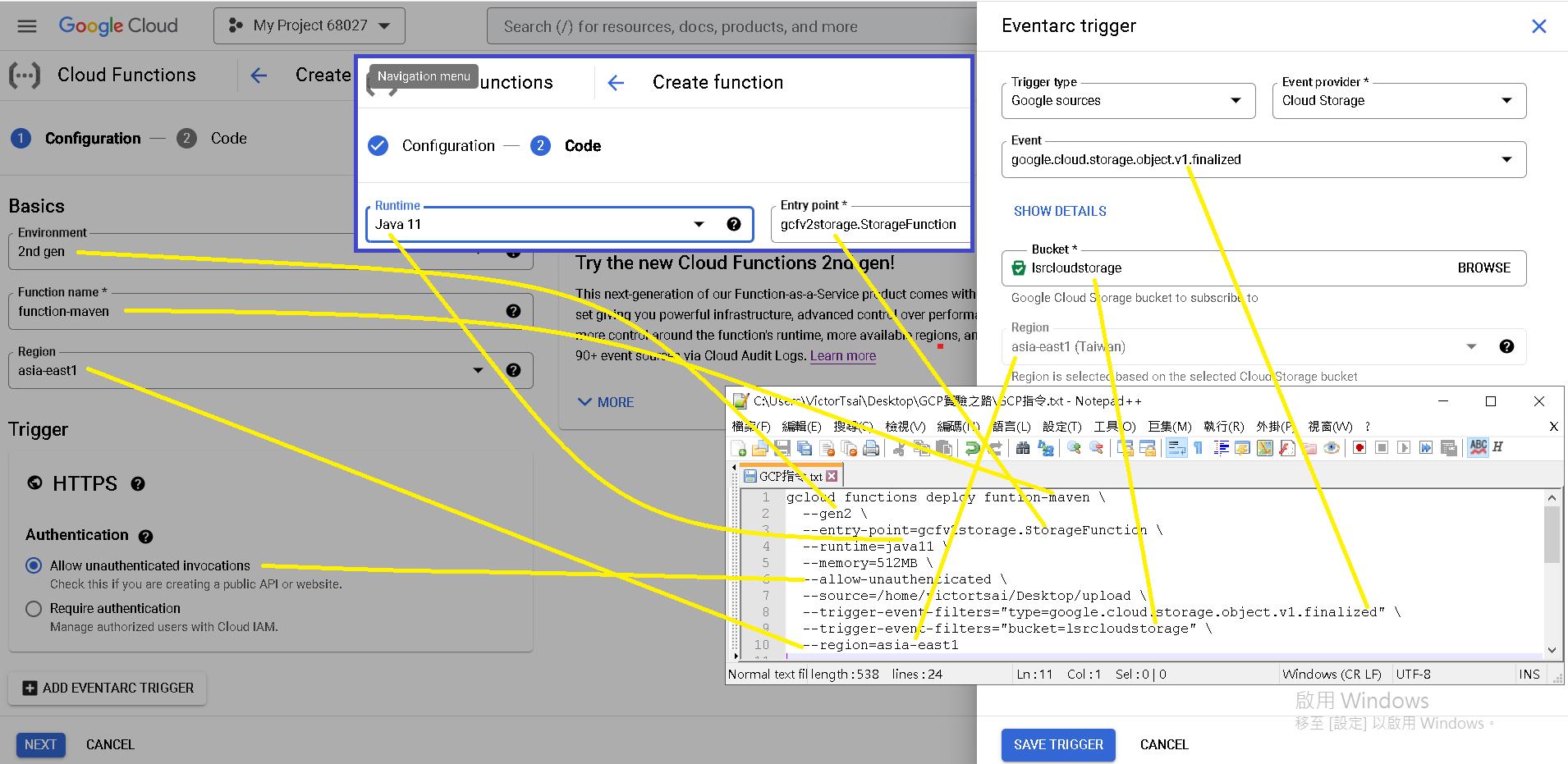
gcloud functions deploy funtion-maven \
--gen2 \
--entry-point=gcfv2storage.StorageFunction \
--runtime=java11 \
--memory=512MB \
--allow-unauthenticated \
--source=/home/victortsai/Desktop/upload \
--trigger-event-filters="type=google.cloud.storage.object.v1.finalized" \
--trigger-event-filters="bucket=lsrcloudstorage" \
--region=asia-east1google.cloud.storage.object.v1.finalized代表Cloud Function的event,指的是偵測到lsrcloudstorage這個Buckets有檔案上傳完畢時的觸發動作。
另外我也附上這些設定與對應的UI選項,用圖與連線的方式表示:
開始執行Gsutil,同時我也將console回應的結果log下來:
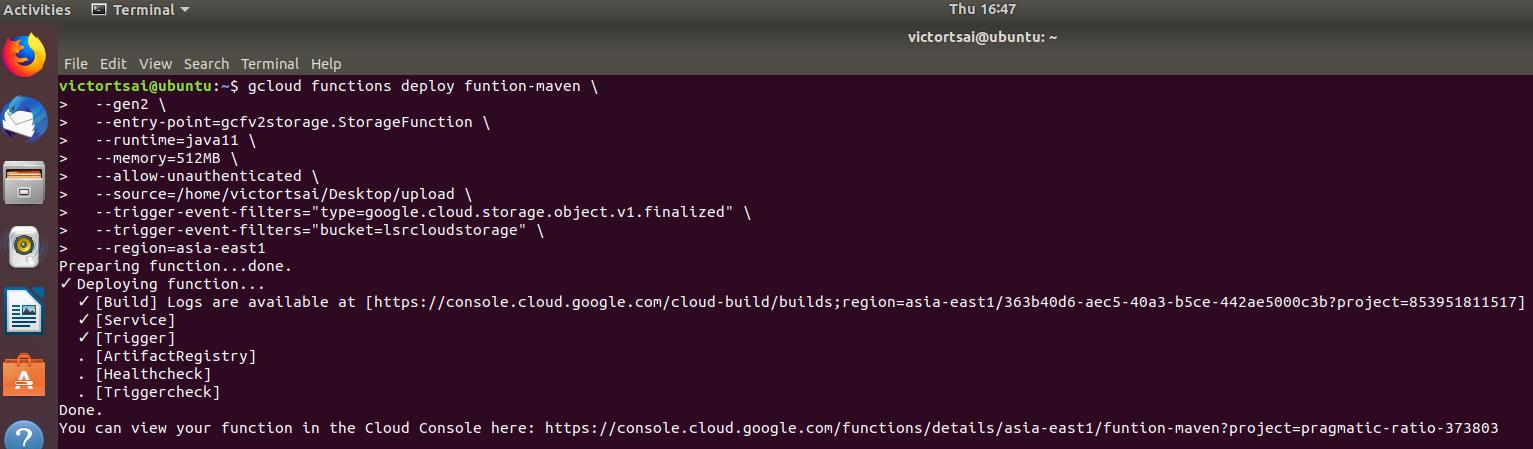
victortsai@ubuntu:~$ gcloud functions deploy funtion-maven \
> --gen2 \
> --entry-point=gcfv2storage.StorageFunction \
> --runtime=java11 \
> --memory=512MB \
> --allow-unauthenticated \
> --source=/home/victortsai/Desktop/upload \
> --trigger-event-filters="type=google.cloud.storage.object.v1.finalized" \
> --trigger-event-filters="bucket=lsrcloudstorage" \
> --region=asia-east1
Preparing function...done.
✓ Deploying function...
✓ [Build] Logs are available at [https://console.cloud.google.com/cloud-build/builds;region=asia-east1/363b40d6-aec5-40a3-b5ce-442ae5000c3b?project=853951811517]
✓ [Service]
✓ [Trigger]
. [ArtifactRegistry]
. [Healthcheck]
. [Triggercheck]
Done.
You can view your function in the Cloud Console here: https://console.cloud.google.com/functions/details/asia-east1/funtion-maven?project=pragmatic-ratio-373803
buildConfig:
build: projects/853951811517/locations/asia-east1/builds/363b40d6-aec5-40a3-b5ce-442ae5000c3b
entryPoint: gcfv2storage.StorageFunction
runtime: java11
source:
storageSource:
bucket: gcf-v2-sources-853951811517-asia-east1
object: funtion-maven/function-source.zip
sourceProvenance:
resolvedStorageSource:
bucket: gcf-v2-sources-853951811517-asia-east1
generation: '1674780039044253'
object: funtion-maven/function-source.zip
environment: GEN_2
eventTrigger:
eventFilters:
- attribute: bucket
value: lsrcloudstorage
eventType: google.cloud.storage.object.v1.finalized
pubsubTopic: projects/pragmatic-ratio-373803/topics/eventarc-asia-east1-funtion-maven-028637-368
retryPolicy: RETRY_POLICY_DO_NOT_RETRY
serviceAccountEmail: 853951811517-compute@developer.gserviceaccount.com
trigger: projects/pragmatic-ratio-373803/locations/asia-east1/triggers/funtion-maven-028637
triggerRegion: asia-east1
labels:
deployment-tool: cli-gcloud
name: projects/pragmatic-ratio-373803/locations/asia-east1/functions/funtion-maven
serviceConfig:
allTrafficOnLatestRevision: true
availableCpu: '0.3333'
availableMemory: 512M
ingressSettings: ALLOW_ALL
maxInstanceCount: 100
maxInstanceRequestConcurrency: 1
revision: funtion-maven-00001-mig
service: projects/pragmatic-ratio-373803/locations/asia-east1/services/funtion-maven
serviceAccountEmail: 853951811517-compute@developer.gserviceaccount.com
timeoutSeconds: 60
uri: https://funtion-maven-3idec7eizq-de.a.run.app
state: ACTIVE
updateTime: '2023-01-27T00:42:44.902462027Z'
Updates are available for some Google Cloud CLI components. To install them,
please run:
$ gcloud components update
To take a quick anonymous survey, run:
$ gcloud survey
victortsai@ubuntu:~$
執行完後,我們可以在GCP的UI上看到部屬完成

上傳parquet檔案觸發event寫入BigQuery
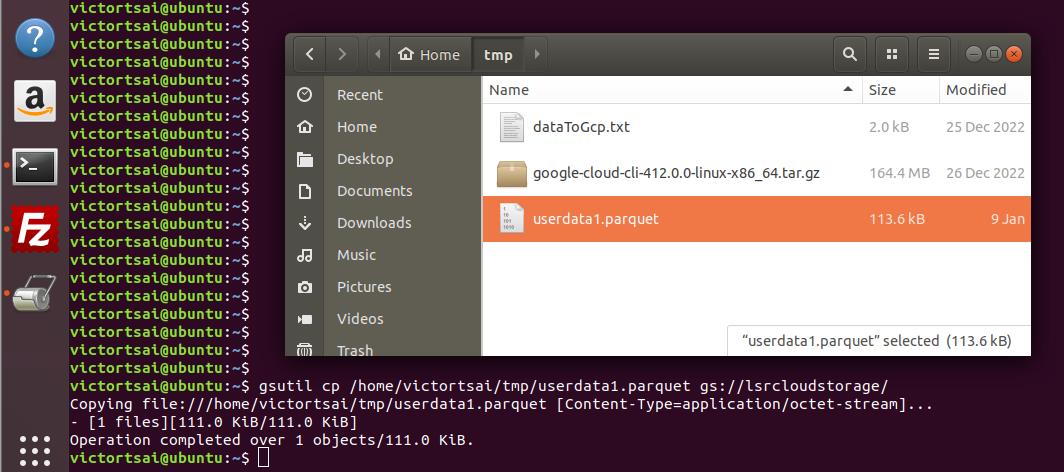
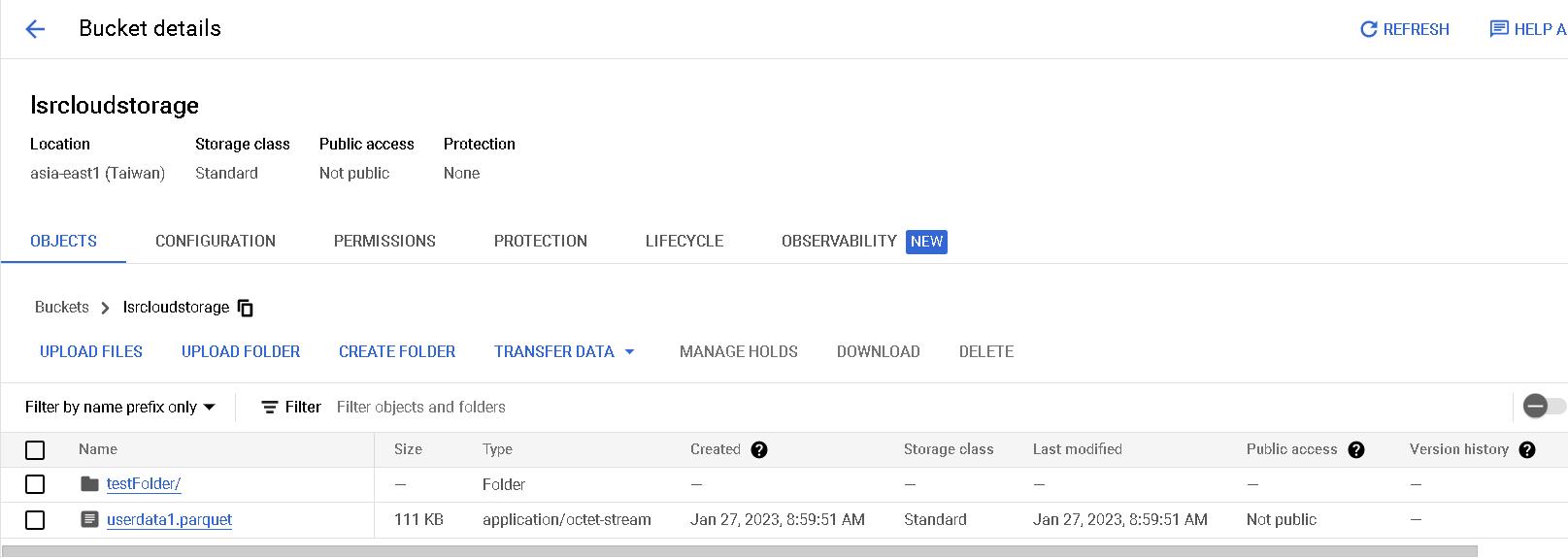
最後我們一樣用Gsutil上傳parquet檔案觸發event,再點進去GCP UI可以看到檔案已上傳。
這裡有個小tip,如果你希望上傳時同時新增子資料夾,只要把上傳路徑加上子資料夾的名稱即可,例如gsutil cp /home/victortsai/tmp/userdata1.parquet gs://lsrcloudstorage/子資料夾名稱/。
接著我們檢查Cloud Function的log,發現log都有正確執行,連我們引入的私有jar(Geohash: wsnqqz7zzzzz)也正確運作:
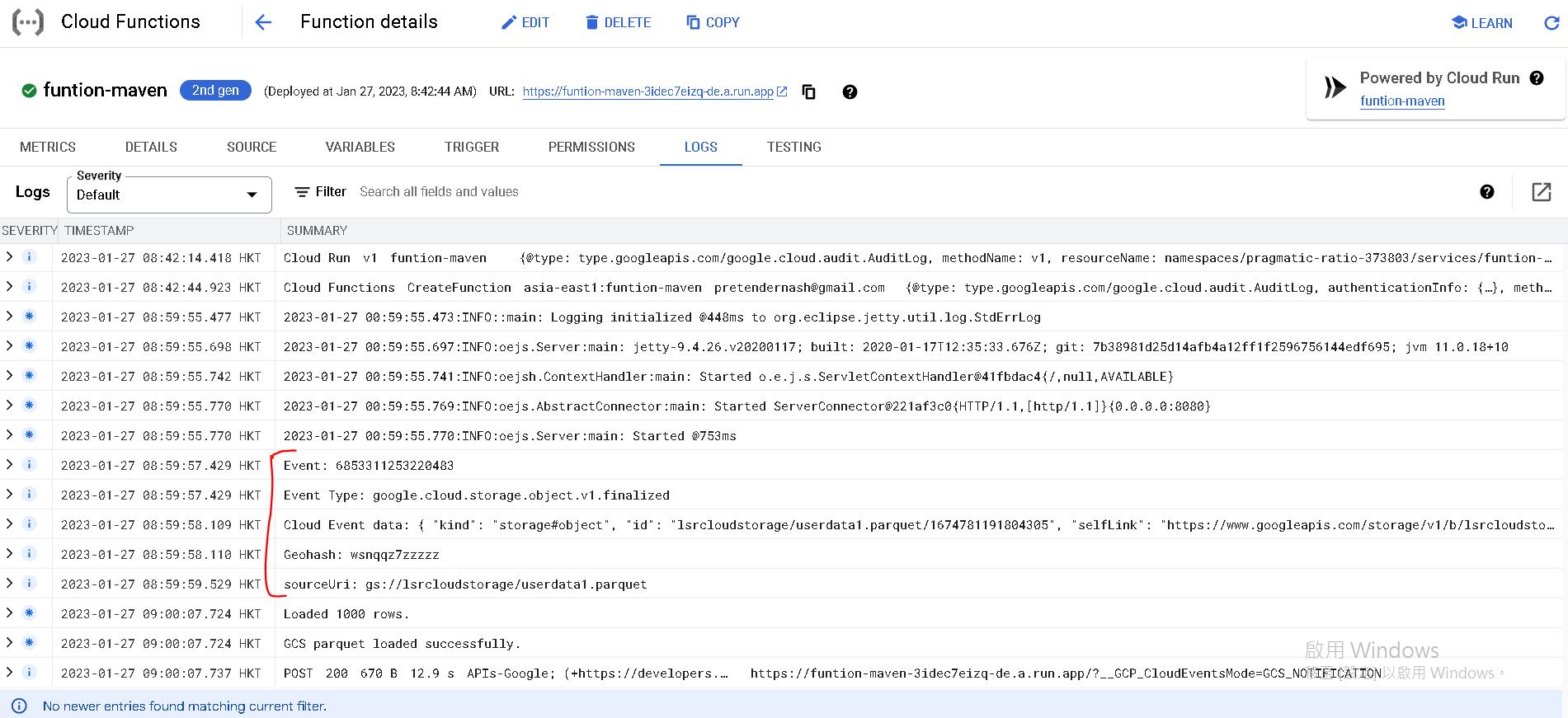
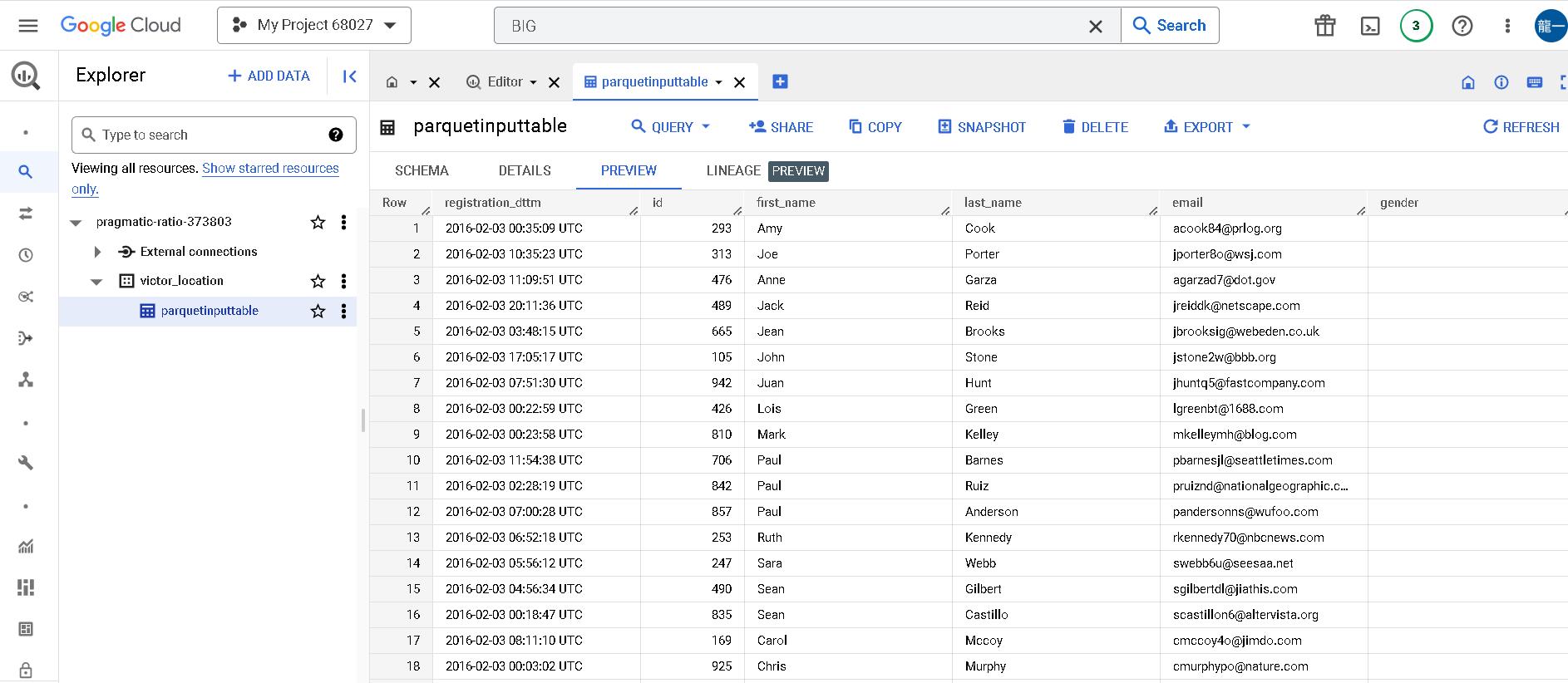
最後我們檢查BigQuery的table,可以發現資料正確被引入了^ ^。
補充資訊
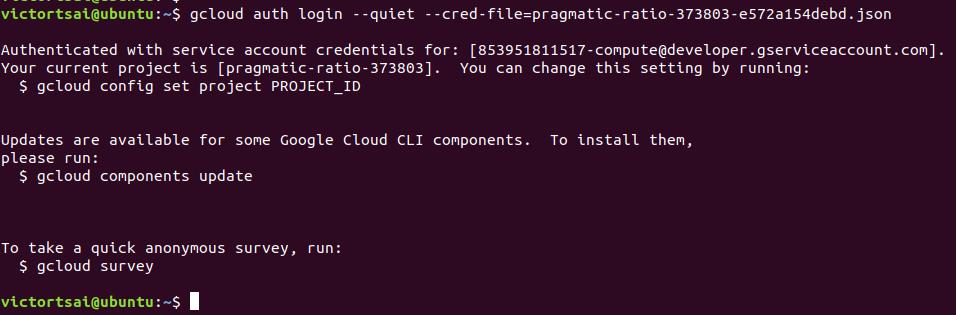
紀錄一下如何使用指令在地端console快速登入你的GCP專案。
首先你必須到GCP介面上產生一個json檔,內容包含你的登入Key與專案資訊。
點選IAM底下的Service Accounts,選擇compute@developer.gserviceaccount.com的action,按下Manage Keys。
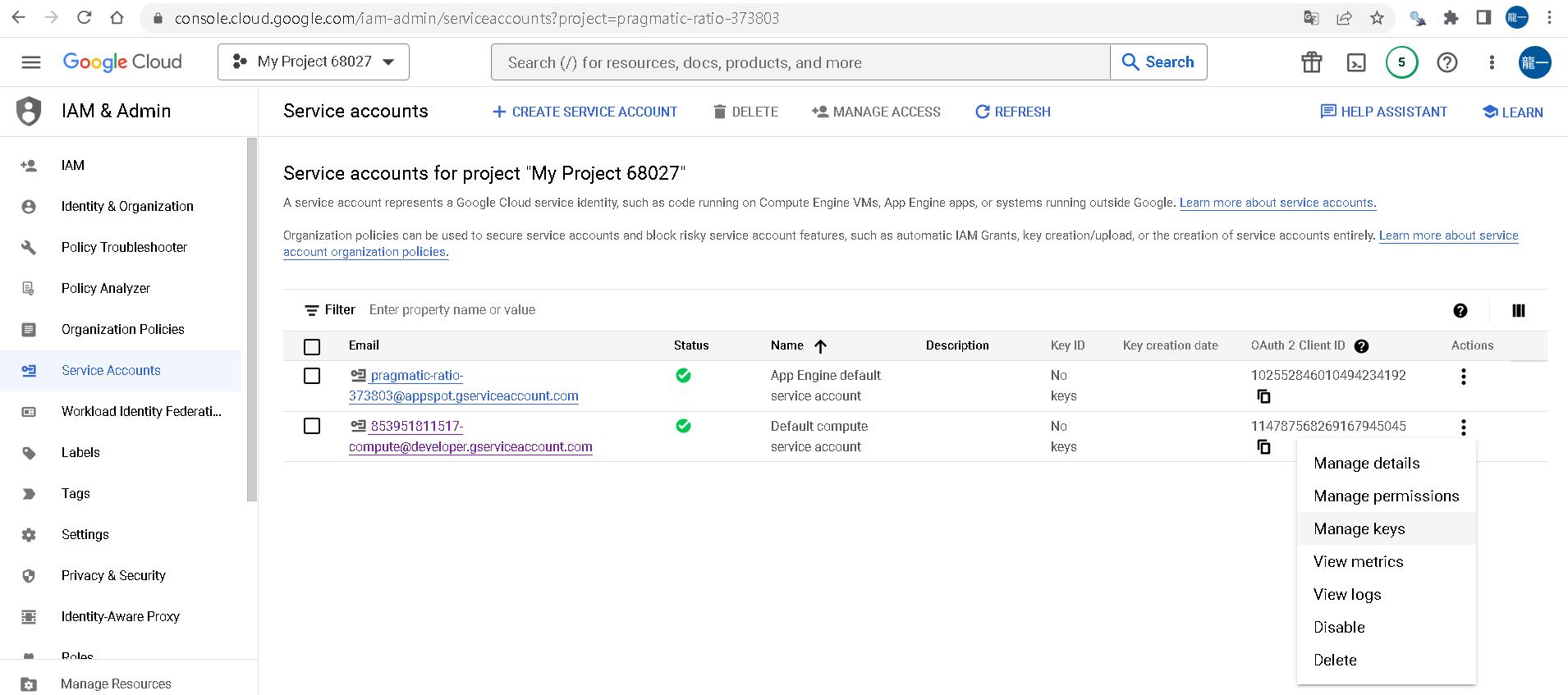
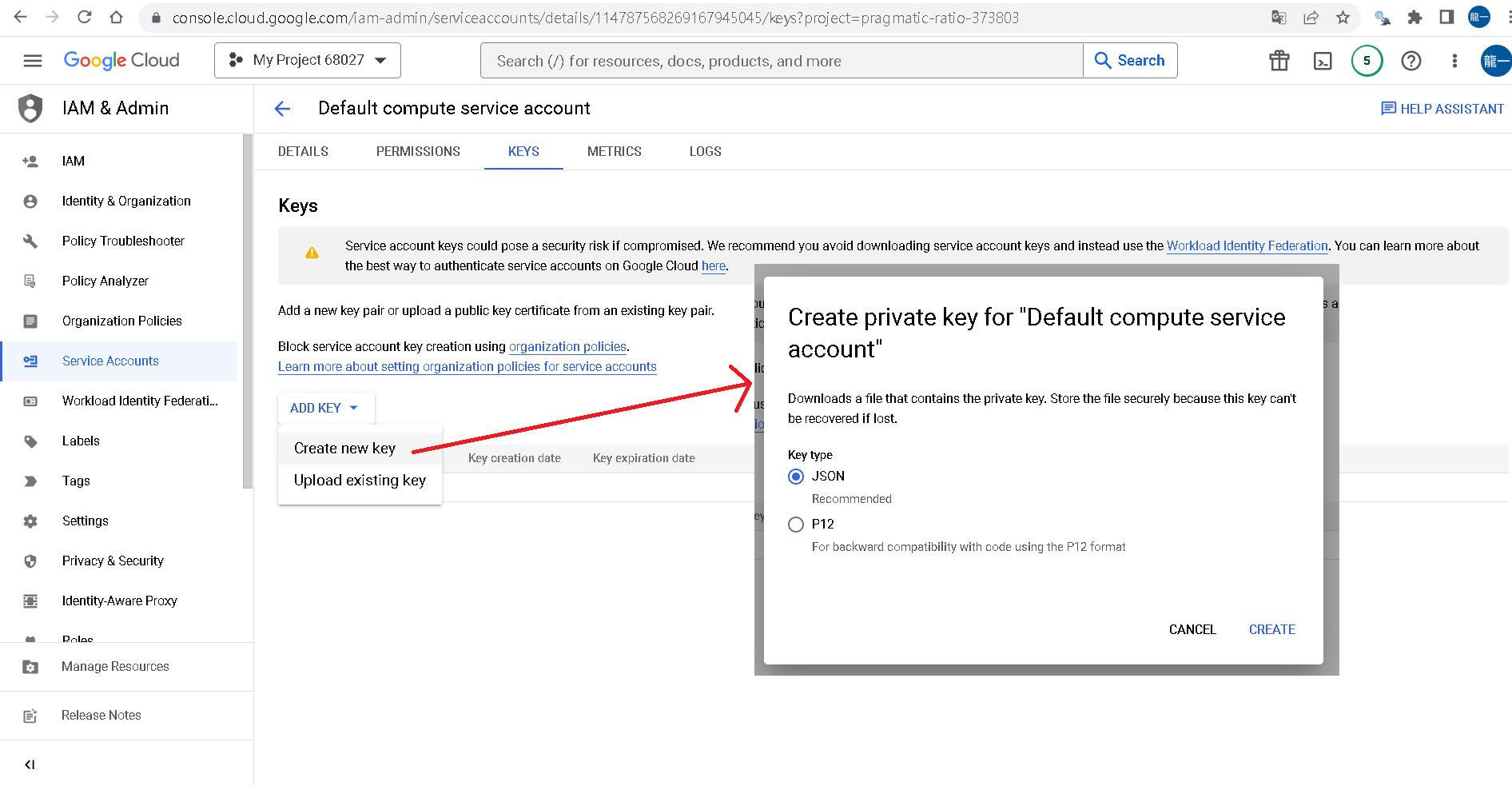
接著點選ADD KEYS的Create new key,匯出JSON檔(請小心保存)。
接著將JSON複製到你要登入的機器,輸入指令gcloud auth login --quiet --cred-file=pragmatic-ratio-373803-e572a154debd.json,登入後即可操作gsutil了。