Flume Customized Interceptor、Flume Filter、regex_filter。
Reference:CustomInterceptor.scala
緣由
此篇其實是之前寫過的以Flume、Kafka與Spark Streaming實現串流傳輸的延伸篇。
會產生延伸篇是因為與公司對口單位介接時,資料提供的上游只能把所需要的欄位提供出來一份由各單位自行萃取。
這就會產生一個問題,每個單位對於同一份資料想要用的欄位都不一樣,上游單位只給出一份資料就會導致這份資料裡欄位過多,檔案肥大。
上一篇使用flume只是單純的希望可以對寫入中的檔案規避掉讀寫問題,完整的將檔案內容全部送上kafka在自己內部系統實作串流技術。
但面對下游各單位不斷對這份資料提出增加其他欄位的需求,將完整檔案所有欄位送上kafka勢必增加叢集儲存loading,並且拖慢串流的處理速度。
因此產生想在flume上傳時過濾所需資料的念頭…最後就找到了關鍵字Interceptor,就一併實作出來。
概述
Flume的interceptor有很多種,基本上都是可以透過設定就能完成的,可以參考這篇https://data-flair.training/blogs/flume-interceptors/
可惜的是沒一個合用,因為我是要將record內的內容做增減,挑特定欄位。
需要的是一個客製化的interceptor,由自己定義的過濾器,簡單來說就是逃不了自己寫的命運了…
因為我所在的單位大量使用的語言是scala,我就乾脆參考別人的sample用scala自己刻一個了。
架構
照上一篇的架構下調整,加上interceptor後就會長這樣:
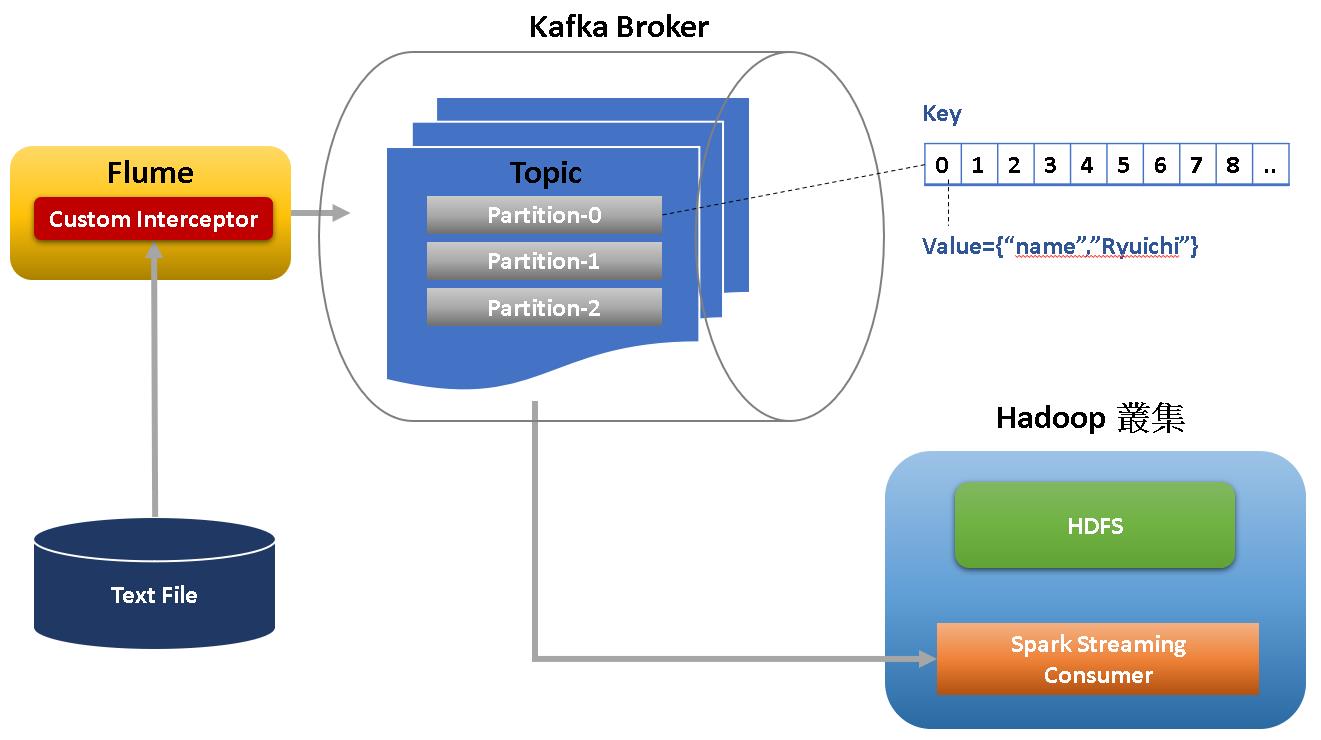
實作內容
撰寫客製化interceptor
參照Reference:CustomInterceptor.scala中的sample,開一個scala project,將程式碼貼上後,於專案檔內引入https://dlcdn.apache.org/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz內lib資料夾底下的所有jar file,這樣就不會有compile錯誤。
接著開始修改程式碼,我們的目的是要從record中取出前兩個欄位作為上傳到kafka的資料。
先用","做切分後只取array內的前兩個值合併轉為byte再做上傳。
Flume是批次作業的,一個批次會有很多個record,程式中的events參數指的就是一個批次下的多個record。
我們會在override def intercept(event: org.apache.flume.Event): org.apache.flume.Event這個function中by record取出做切分並挑選欄位的動作。
程式碼修改如下:
package com.tku.edu
import scala.collection.JavaConversions.collectionAsScalaIterable
class MyCustomInterceptor(var ctx: org.apache.flume.Context) extends org.apache.flume.interceptor.Interceptor {
/**
* 字串中用,分隔欄位,取前preserveCommaCount個欄位
* 用數,的位置做substring取代用split,避免效能issue
*/
def substringByCountSplitterPosition(line: String, preserveCommaCount: Integer): String = {
var endIndex = 0
var count = 0
var filteredLine = line//萬一有莫名其妙的狀況出現exception時回傳原本字串
try {
val len = line.length()
for(i <- 0 to len-1 if count<preserveCommaCount) {//數2個,位置
if(line.charAt(i) == ',') {
count = count + 1
endIndex = i
}
}
if(count == preserveCommaCount) {
filteredLine = line.substring(0, endIndex)//有數到逗點時
}
} catch {
case ex: Exception => {
print(ex.getMessage)
}
}
filteredLine
}
override def initialize() = {
println("************MyCustomInterceptor initializing**************")
println()
}
override def intercept(event: org.apache.flume.Event): org.apache.flume.Event = {
val input = new String(event getBody) //轉換內容成為String做處理
//val inputStringArr = input.split(",") //以逗號切分
//val filteredString = inputStringArr(0)+","+inputStringArr(1) //只取前兩個欄位
val filteredString = substringByCountSplitterPosition(input, 2) //使用數逗點位置的方式做substring可大幅增加效能
val output = (filteredString).getBytes //轉為byte
event setBody output
event
}
override def intercept(events: java.util.List[org.apache.flume.Event]): java.util.List[org.apache.flume.Event] = {
events foreach intercept //flume處理一個批次會有多個event(record)
events
}
override def close() = {
println("************MyCustomInterceptor closing**************")
println()
}
}
object FlumeCustomInterceptor {
class Builder extends org.apache.flume.interceptor.Interceptor.Builder {
var ctx: org.apache.flume.Context = _
override def configure(context: org.apache.flume.Context) = {
this ctx = context
}
override def build(): org.apache.flume.interceptor.Interceptor = {
new MyCustomInterceptor(ctx)
}
}
}程式撰寫好後,export為jar file,將其放到你要執行的flume資料夾裡的lib資料夾下,以上一篇的例子就是放在/media/hduser/Backup/apache-flume-1.9.0-bin/lib/。

修改/media/hduser/Backup/apache-flume-1.9.0-bin/conf/flume.conf
於flume設定檔增加interceptor設定:
#custome interceptor
a1.sources.s1.interceptors = i1
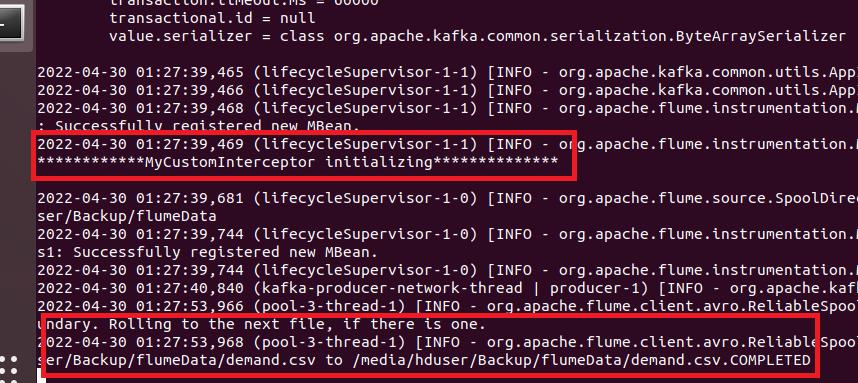
a1.sources.s1.interceptors.i1.type = com.tku.edu.FlumeCustomInterceptor$Builder修改設置完成,啟動flume,觀察是否正常掛載interceptor。
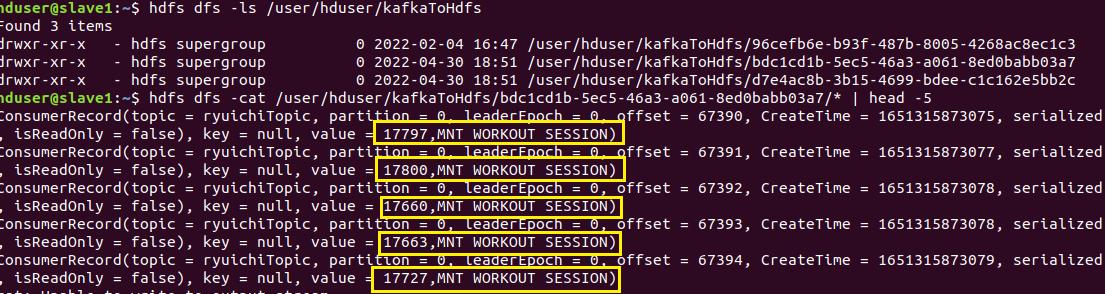
上傳kafka完成後,啟動spark-streaming,確認將串流消費至hdfs,將檔案cat出來,只會有檔案的前兩個欄位(可以跟上一篇最後一張圖比對~)。
FIlter補充
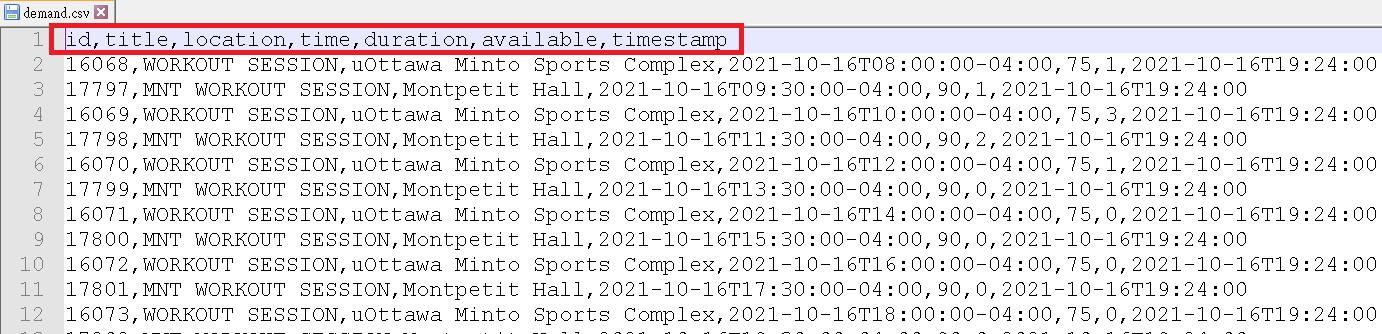
本篇實作的是一般比較少見的挑選文字檔欄位,一般來說都是過濾文字檔的raw data為主,移除不需要的資料列,在這裡也一併將flume設定附上。
假如你是想濾除文字檔中的header,可以用regex_filter撰寫regular expression在flume的設定檔裡,設定如下(我們這邊設定為id,title開頭的字串):
※header內容如果需要用regex表示空白可用\\s
#regex filter
a1.sources.s1.interceptors=header_filter
a1.sources.s1.interceptors.header_filter.type=regex_filter
a1.sources.s1.interceptors.header_filter.regex=^id,title
a1.sources.s1.interceptors.header_filter.excludeEvents=true