Coding Spark 2.4 Program Using Scala Eclipse IDE。
之前寫過用 spark 1.6 來進行開發的說明,包含一些最 detail 的環境設定(例如 winutil、scala 與 java 的版本對應),本篇就不贅述,需要的朋友請參考下面 URL。
https://dotblogs.com.tw/Ryuichi/2020/04/18/140144
本篇只對 spark 2.4 開發環境的 jar 檔引入與 scala compiler 設定做圖解說明,並於最後使用 spark 2.0 以上才有的物件撰寫一段小程式驗證。
1.環境準備與設定
請至下列網址下載 hadoop 與 spark 2.4 的 jar 包。
https://archive.apache.org/dist/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.6.tgz
下載完後解壓縮,於 Eclispe 將 jars 資料夾內的所有 jar 檔引入,並將 scala 的 compiler 改為 2.11 (spark 2.4 需使用 scala 2.11 compile 才會過)。

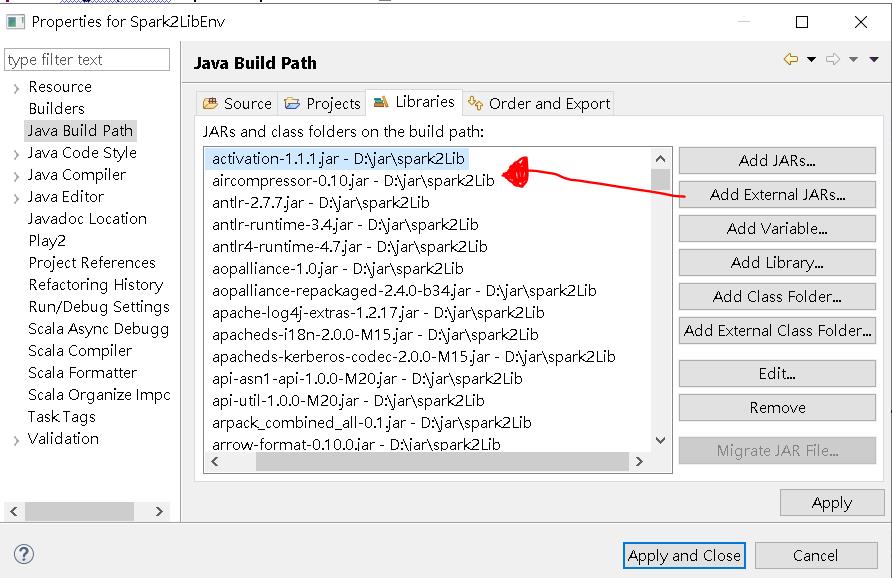
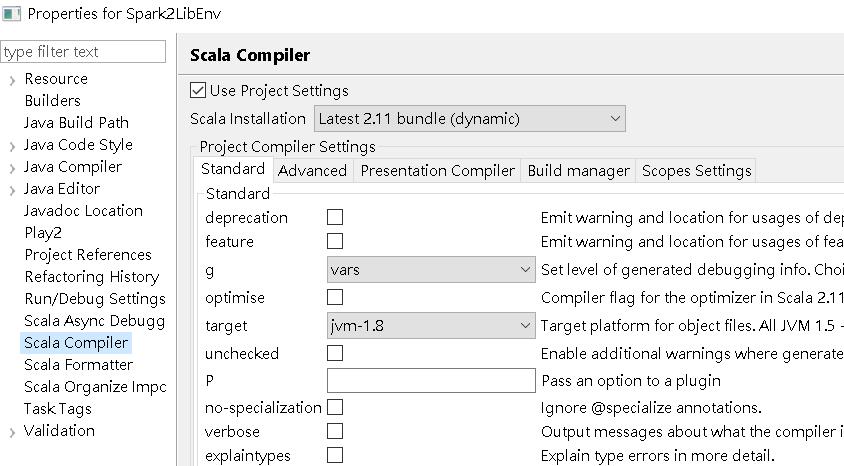
調整scala compiler的步驟很重要,每個spark版本有對應的scala版號,一旦選錯,你的專案夾上面會有紅叉叉,程式可以執行也可以export,但實務上我有遇到jar檔執行時code不照程式邏輯跑的狀況,會debug到天荒地老,你各位還是不要自己弄自己,乖乖地選對scala版本。
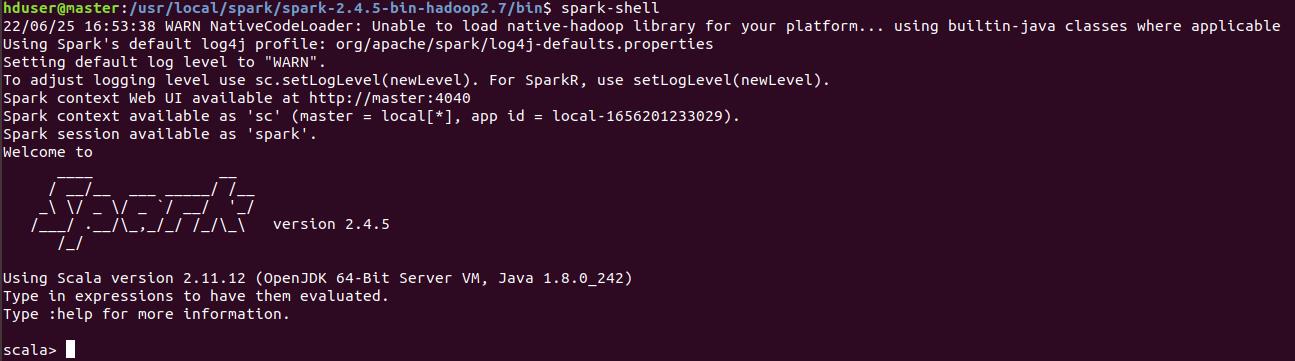
你也可以從hadoop叢集直接下spark-shell,系統便會將使用的spark與scala版本吐出來,就可以知道版本的對應,你再去設定IDE專案的compiler就好。
2.撰寫測試程式
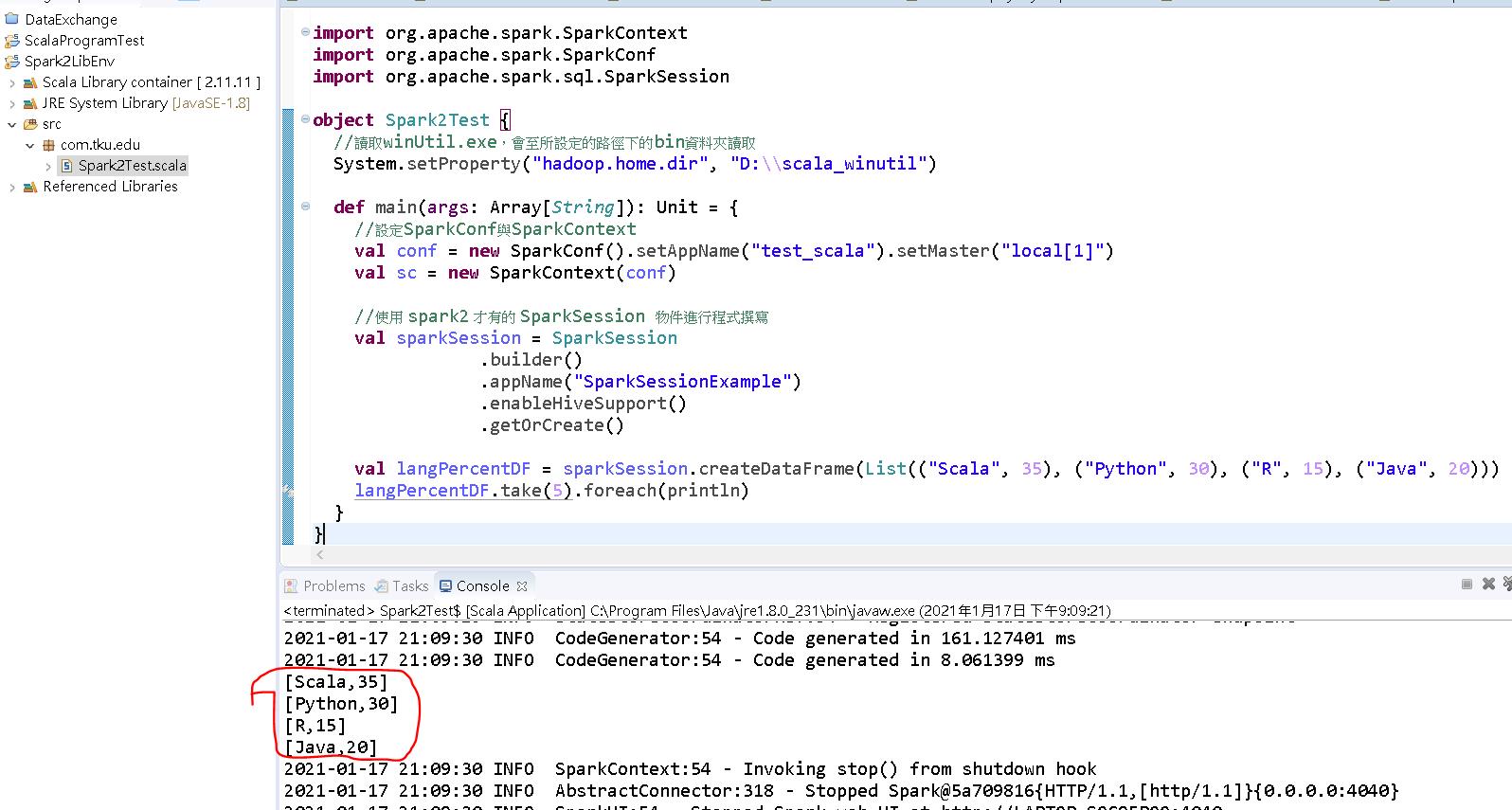
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object Spark2Test {
//讀取winUtil.exe,會至所設定的路徑下的bin資料夾讀取
System.setProperty("hadoop.home.dir", "D:\\scala_winutil")
def main(args: Array[String]): Unit = {
//設定SparkConf與SparkContext
val conf = new SparkConf().setAppName("test_scala").setMaster("local[1]")
val sc = new SparkContext(conf)
//使用 spark2 才有的 SparkSession 物件進行程式撰寫
val sparkSession = SparkSession
.builder()
.appName("SparkSessionExample")
.enableHiveSupport()
.getOrCreate()
val langPercentDF = sparkSession.createDataFrame(List(("Scala", 35), ("Python", 30), ("R", 15), ("Java", 20)))
langPercentDF.take(5).foreach(println)
}
}執行結果如下: