RDD Union、SubstractByKey。
承接 https://dotblogs.com.tw/Ryuichi/2020/04/26/154505,本篇將簡介如何合併 RDD 的資料與 RDD 之間做差集。
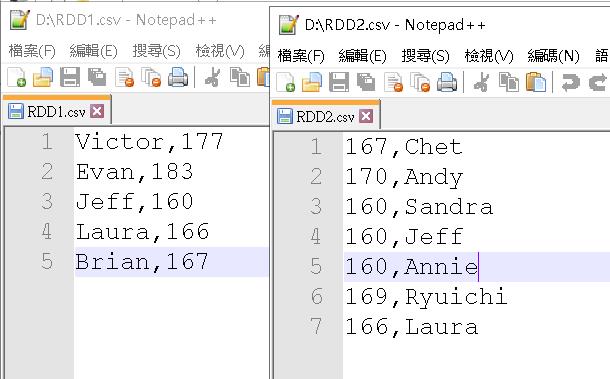
首先我們先準備兩個文字檔紀錄用戶的名字與身高,第二個檔案故意把身高與名字的順序寫反(後面會說明為什麼),長相如下:
1.UNION
將檔案讀取進來,並且用逗號做切分,個別產生兩個 tuple。

之後利用 RDD 的 Union 方法即可將兩個 RDD 的內容併在一起。

2.SubstractByKey
如果我們要找出 RDD1.csv 裡有哪些資料是 RDD2.csv 沒有的,就需要用到 RDD 的 SubstractByKey 的方法。
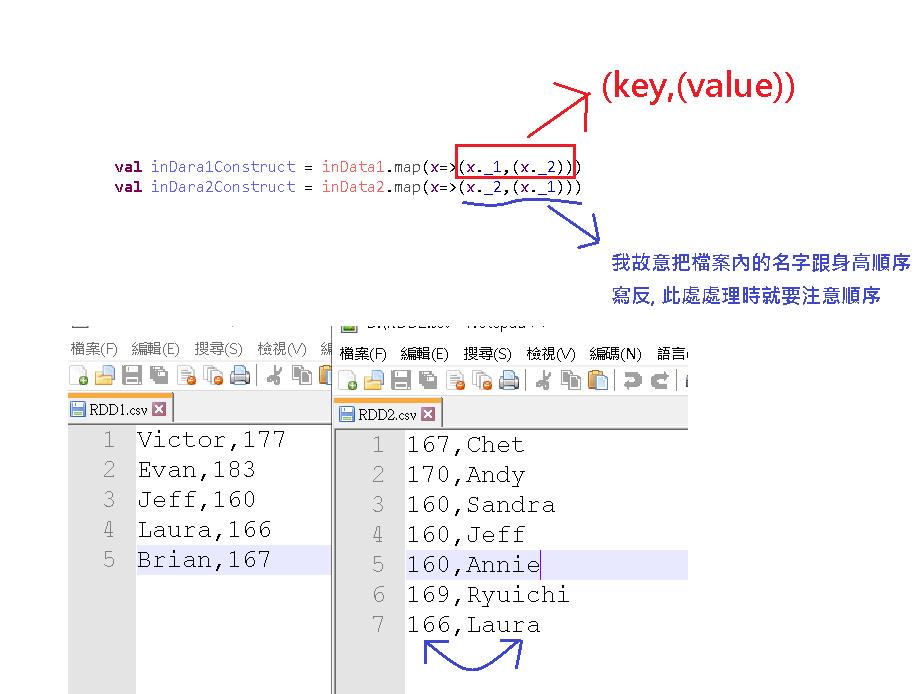
依照字面上的意思,by key,意即是利用 (key,(內容)) 這樣的格式下,進行差集,因此我們必須把資料做一些處理後才能使用(這裡我們使用名字當作 key 做示範)。
我前面故意把第二個檔案的順序寫反,目的有兩個,一是 Union 時可以看出效果。
二來做差集時,因為是要 by key 做差集,如果有看懂的客官就會知道必須要把用逗號 split 的結果放的順序改變,RDD2.csv 才會用名字當作 key。
接著我們使用 RDD1.csv 的內容差集 RDD2.csv。

結果如下,因為 RDD2.csv 裡面的用戶 Laura 與 Jeff 在 RDD1.csv 裡有出現,做差集後會被扣掉,只會剩下3位用戶的資料。
