groupByKey、mapValues、flatMap、sortBy。
各位想了解此篇之前請先裝好本機端的 Scala Eclipse。
Scala Eclipse 安裝與設定詳細實作方式可參考我之前寫的文章 https://dotblogs.com.tw/Ryuichi/2020/04/18/140144
Spark 的程式主要是處理大數據時使用的。
最基本的應用就是將海量的資料 by 行的方式,分散式送到各個機器上平行做處理,藉此發揮整個叢集的運算能力。
也因為這樣的模式,和以往寫 AP 程式直線性的程式流程不太一樣,
這系列我將簡介我在學 scala 開發 spark 程式中,我認為幾個挺有用的寫法,以圖文說明的方式盡量讓各位看得懂。
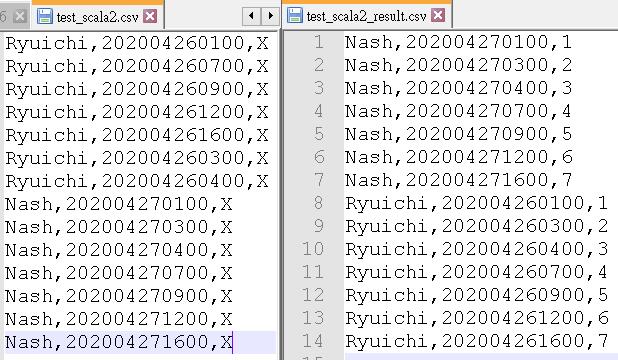
這篇將說明如何將某個檔案內容經過排序與處理後存檔,請參考下圖,左邊是原始圖檔內容,右圖是處理後的內容。
左邊的原始檔內容,第一欄是人名,第二欄是時間(yyyymmddhhmm),第三欄是文字 X。
我們的目的,是要依據每個人名出現的時間,將文字 X 取代成其出現的順序,並且在存檔的時候,使其依人名、時間排序寫入檔案。
本篇主要會用到 groupByKey (用人名 group 後處理資料)、mapValues(處理 group 後的資料)、flatMap(將 group 後處理完的資料展開) 和 sortBy(存檔依據人名、時間排序) 技巧。
1. 讀檔與格式組成
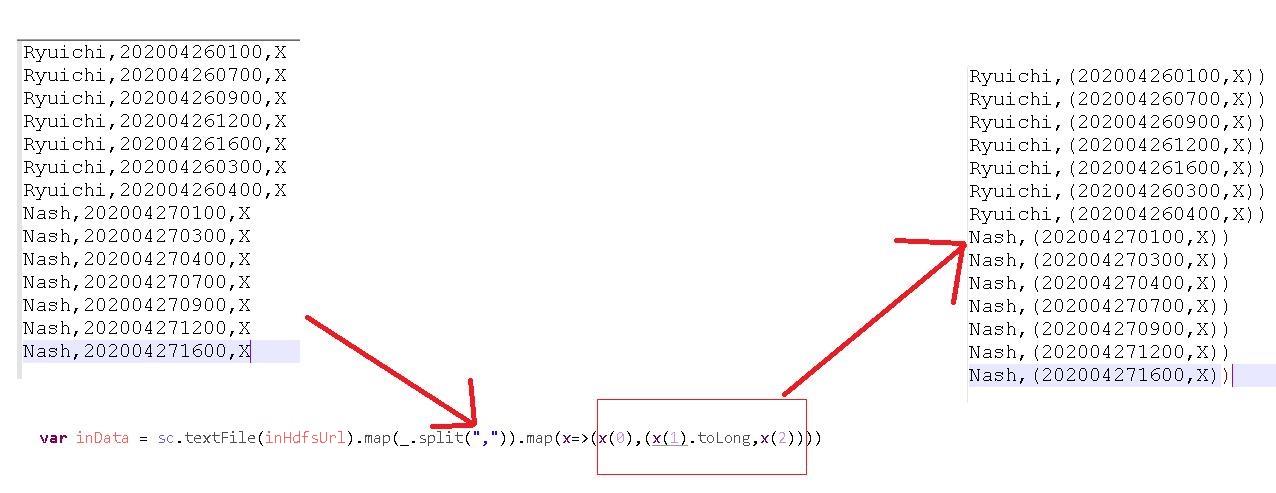
首先讀檔,並將檔案組織成這樣的格式(key,(內容)),如下圖。
因為我們要 by 人名處理,key 自然就是我們第一欄的人名,其所帶的資料為時間和X。
先以逗號切分每行資料後,才可以分得出第幾欄是什麼資料,x(0)是名字,x(1)是時間,x(2)是X。
在這邊我們先將時間轉換成 Long 格式,方便等一下處理資料時使用。
2.GroupbyKey and MapValues
格式組完成之後,利用剛剛的 key 下 groupByKey,並使用 mapValues 做資料操作。
此時程式背後的運算,會將 Ryuichi 和 Nash 兩個人名的資料分別收攏起來進 mapValues 程式區段處理。
我們將各自 groupby 後的資料轉成 list 後依時間排序(這就是為什麼前面要先將時間轉 Long 格式)。
接著利用迴圈把順序數字加入,並用一個 String ListBuffer 將資料回傳出去。

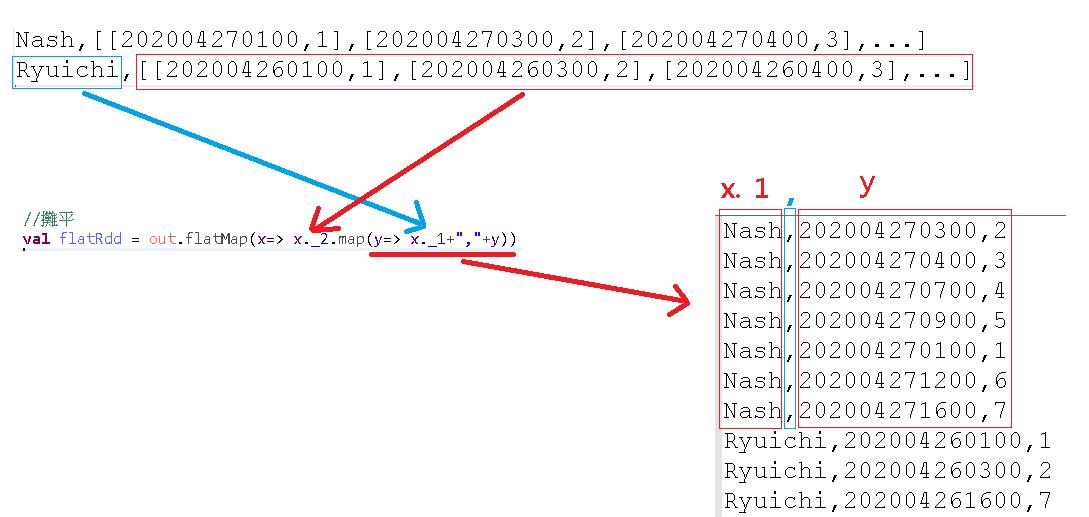
此時的 out 變數,型態會是 RDD[(String, ListBuffer[String])],你可以想像裡面的內容如下圖。
每一列的資料變成一個人名 String 後面帶一個時間與順序組成的 ListBuffer,以我們的範例來說,總資料就是兩列。

3.FlatMap 攤平資料
前面為了將同一個人底下的時間資料收攏進行排序處理,我們用了 groupByKey 的方式將資料集中處理成一個 ListBuffer。
接著我們用 flatMap 這個函式,將資料從一列攤成多列,並且將人名與 ListBuffer 的內容用逗號相加變成一個 String。
4.SortBy 後存檔
其實不用排序直接存檔也是可以,但這樣做在人工看資料的時候會比較麻煩(因為沒有排序)。
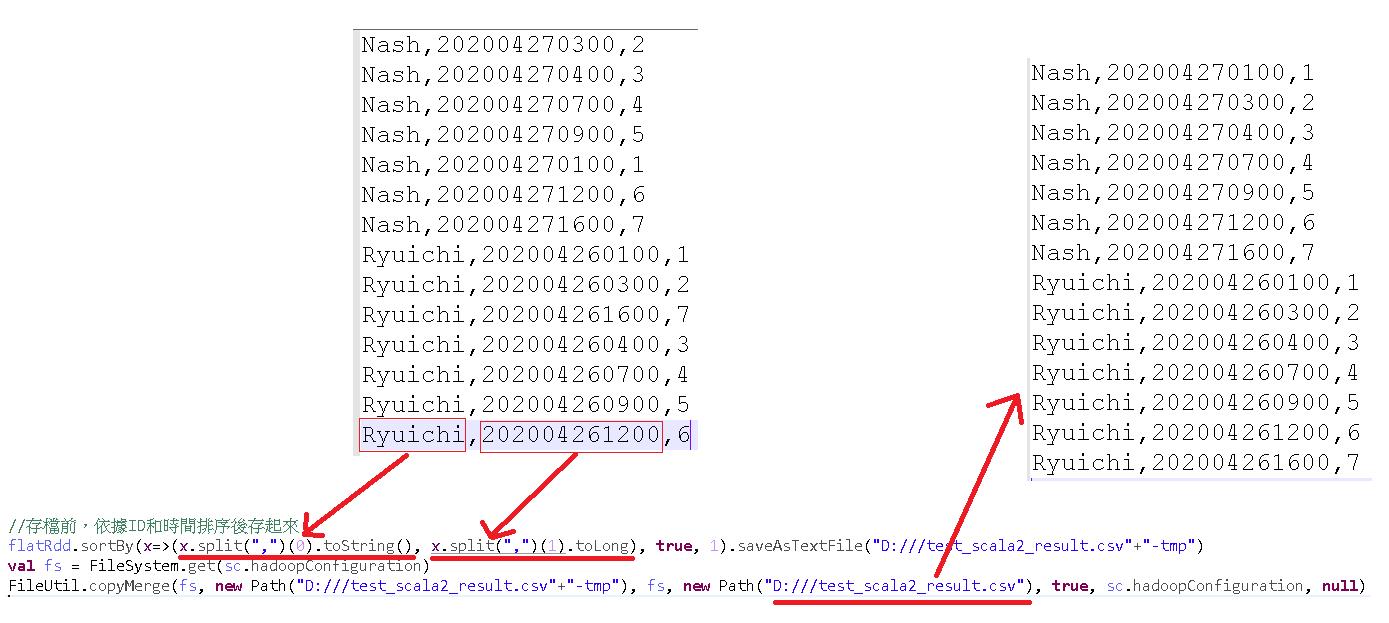
但這是大數據的分散式程式,Sort 的方法當然也要特別處理,經過自己掉了好幾次坑後的歸納,排序和存檔這兩個動作必須寫在同一行,分開寫會沒有效果。
變數 flatRdd經過前面處理已經變成一行一行的 String,在存檔前,我們利用逗號切分出來的名字與時間做排序後,直接存檔,就可以得到我們想要的排序結果。
完整的實作程式如下。
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import scala.collection.mutable.ListBuffer
import org.apache.hadoop.fs.FileSystem
import org.apache.hadoop.fs.FileUtil
import org.apache.hadoop.fs.Path
object ScalaGroupByKeyMapValues {
//讀取winUtil.exe,會至所設定的路徑下的bin資料夾讀取
System.setProperty("hadoop.home.dir", "D:\\scala_winutil")
def main(args: Array[String]): Unit = {
//設定SparkConf與SparkContext
val conf = new SparkConf().setAppName("scalaTest1").setMaster("local[1]")
val sc = new SparkContext(conf)
var inHdfsUrl = "D:///test_scala2.csv"
var inData = sc.textFile(inHdfsUrl).map(_.split(",")).map(x=>(x(0),(x(1).toLong,x(2))))
var out = inData.groupByKey().mapValues {
x=>
//利用時間排序
var list = x.toList.sortBy(_._1)
//建立一個回傳的Array
var result = new ListBuffer[String]()
for(i <- 0 to list.size - 1 ) {
result += list(i)._1+","+(i+1).toString()
}
result
}
//攤平
val flatRdd = out.flatMap(x=> x._2.map(y=> x._1+","+y))
//存檔前,依據ID和時間排序後存起來
flatRdd.sortBy(x=>(x.split(",")(0).toString(), x.split(",")(1).toLong), true, 1).saveAsTextFile("D:///test_scala2_result.csv"+"-tmp")
val fs = FileSystem.get(sc.hadoopConfiguration)
FileUtil.copyMerge(fs, new Path("D:///test_scala2_result.csv"+"-tmp"), fs, new Path("D:///test_scala2_result.csv"), true, sc.hadoopConfiguration, null)
}
}