Coding Spark Program Using Scala Eclipse IDE。
Eclipse 是許多工程師愛用的IDE,但用 Eclipse 寫 Scala 開發 Spark 程式卻容易在一開始環境設定上遇到一些坑。
本人處於軟體工程師轉職為資料工程師的過程,決定將這些細節全部記下來,一方面做紀錄,一方面也讓想學用 Scala 開發 Spark 程式的人不必再踏入同樣的坑內,浪費太多時間。
1.環境準備與設定
請下載以下相關程式與Jar檔( Url 都幫你準備好了~),我們預計會用 Spark 1.6 + Scala Eclipse IDE 4.7 + OpenJDK 1.8 實作。
Jar File:http://archive.apache.org/dist/spark/spark-1.6.1/spark-1.6.1-bin-hadoop2.6.tgz
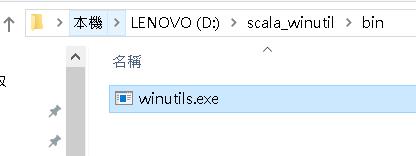
winutils.exe:https://github.com/steveloughran/winutils/blob/master/hadoop-2.6.0/bin/winutils.exe
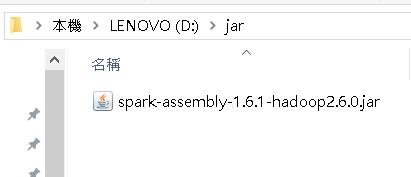
Jar File下載解壓縮後,請找尋lib資料夾內的 spark-assembly-1.6.1-hadoop2.6.0.jar ,取出後備用。
winutils.exe 為於 Eclipse 本機跑 Spark 程式所需之應用程式。
下載完成後,安裝 Open JDK、安裝 Eclipse,並執行以下步驟:
a. 將 spark-assembly-1.6.1-hadoop2.6.0.jar 放在 D:\\ jar 內
b. 將 winutills.exe 放在 D:\\ scala_winutil \ bin 內
c. 起一個 Scala 專案檔命名 ScalaProgramTest,並於Build Path 引入 spark-assembly-1.6.1-hadoop2.6.0.jar。
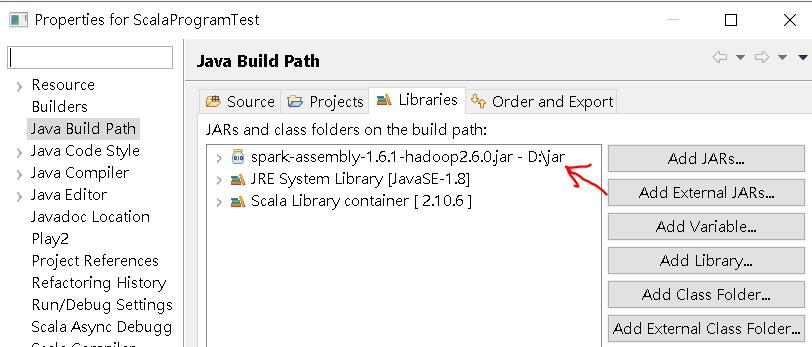
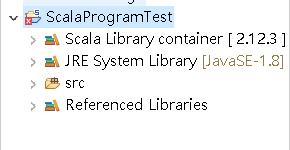
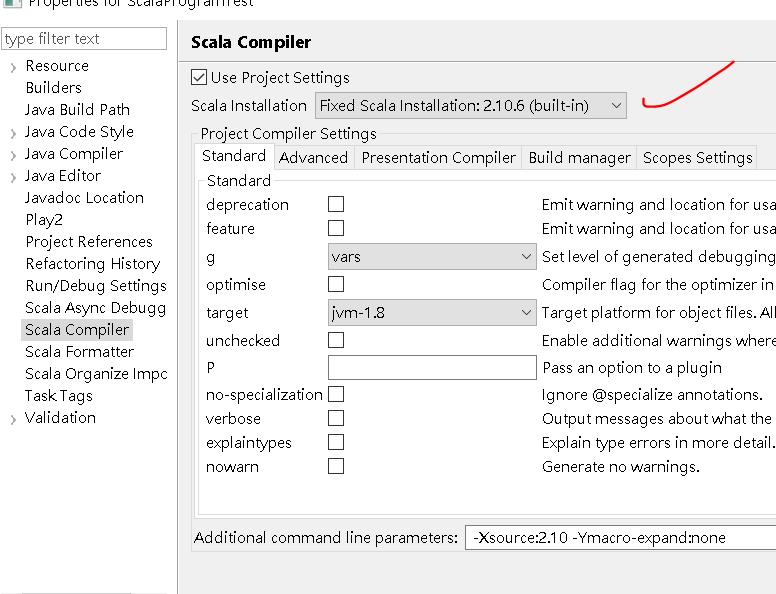
做完這些動作,你應該就會發現,你的專案檔上面出現了奇怪的叉叉,這是因為 Scala 對於 JVM 版本的支援度問題(請參考下面第2張圖)。
我們用的是 Java 1.8,請將專案檔內的 Scala Compiler 內的 Scala Installation 調整為 2.10.6(built-in) 後,aplly 設定,叉叉就會消失。

2.撰寫測試程式
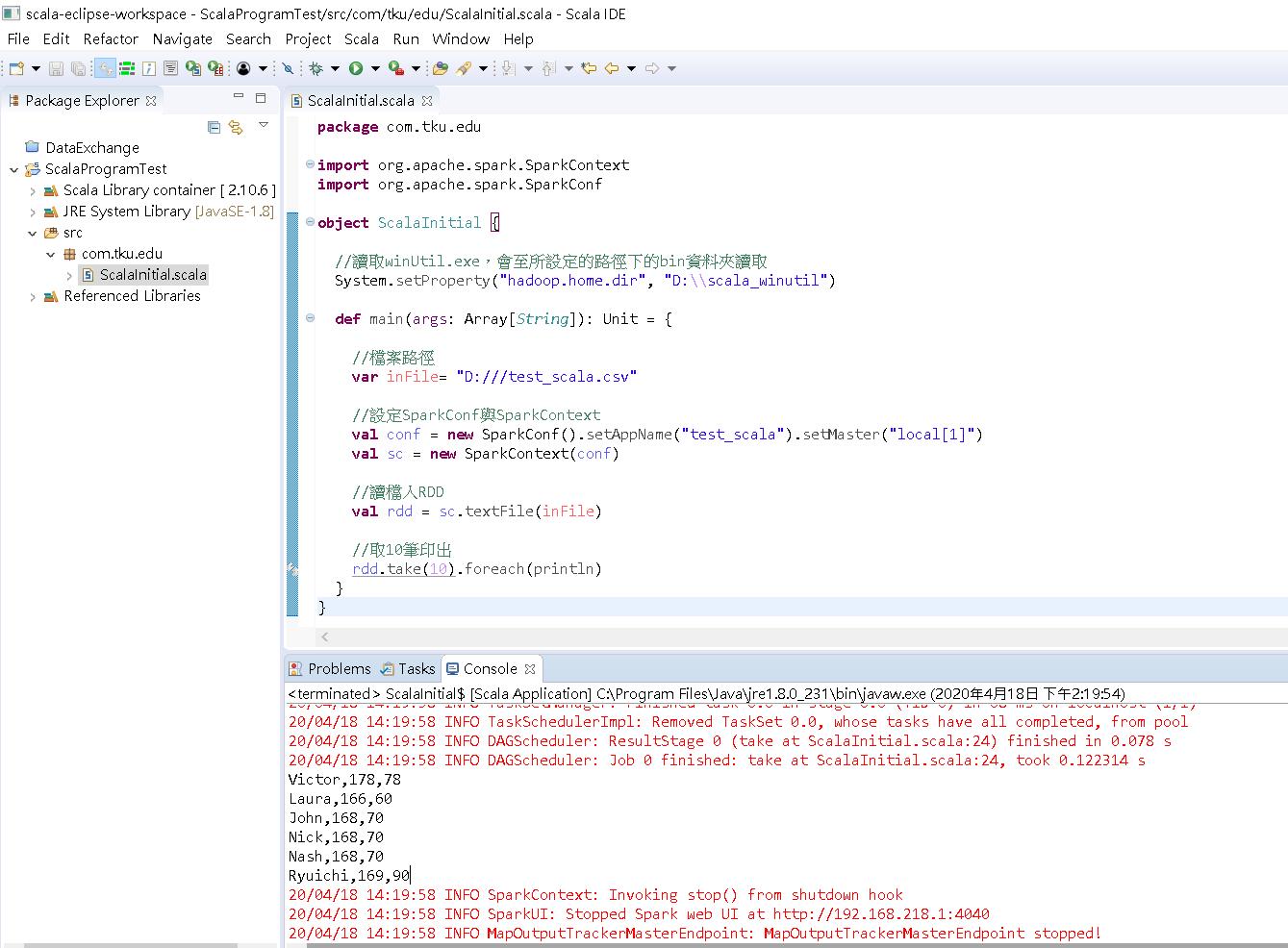
接著我們寫一段程式,讀取一個csv檔,並將內容印出。
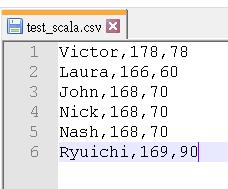
a. 新增一個文字檔 test_scala.csv 內容如下,放在 D:\\ 下。
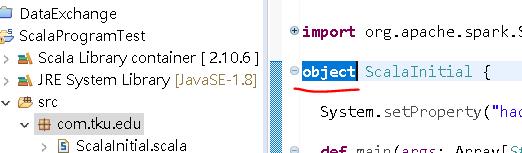
b. 新增一個 Scala 檔,命名為 ScalaInitial.scala,並把檔案內部的 class 字眼調整為 object。
接著輸入完整程式碼。
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object ScalaInitial {
//讀取winUtil.exe,會至所設定的路徑下的bin資料夾讀取
System.setProperty("hadoop.home.dir", "D:\\scala_winutil")
def main(args: Array[String]): Unit = {
//檔案路徑
var inFile= "D:///test_scala.csv"
//設定SparkConf與SparkContext
val conf = new SparkConf().setAppName("test_scala").setMaster("local[1]")
val sc = new SparkContext(conf)
//讀檔入RDD
val rdd = sc.textFile(inFile)
//取10筆印出
rdd.take(10).foreach(println)
}
}執行結果如下: