在現在大數據的時代裡,數據是非常重要的,拿到相關數據可以做一些演算、分析,因此使用"網路爬蟲"爬取一些規則性的數據。。。
網路爬蟲究竟這名詞是甚麼呢?
從網路上搜尋"'網路爬蟲",會搜到很多相關資訊
由"MBA智庫百科"簡單說: 網路爬蟲又名“網路蜘蛛”,是通過網頁的鏈接地址來尋找網頁,從網站某一個頁面開始,讀取網頁的內容,找到在網頁中的其它鏈接地址,然後通過這些鏈接地址尋找下一個網頁,這樣一直迴圈下去,知道按照某種策略把互聯網上所有的網頁都抓取完為止的技術。
因此會透過任何網路溝通的方式進行溝通資料。
如API,或是直接從網頁上獲取。
1.網路爬蟲的規劃:
你需要獲取哪些資料呢?
舉例學聯網來說規劃:

看到上圖有一些相關課程
有一些相關資料:由左到右,有課程的照片、課程名稱、課程相關內容、師資、師資照片等等
(以及網頁上有相關的按鈕需要點取、或是找到一些規則後透過修改網址(URL)的方式修改網頁資料、以及現在多數網頁都有JavaScript作為互動,那麼網路爬蟲要如何去與網頁互動呢?)
那那些資料是我的需求呢?
以及哪些資料可以用最省的方式(省資源、省網路、省時間等等)去獲取呢?這樣不只你速度快、對方與自己的網路比較節省(其實網路爬蟲沒那麼合法,後面補充)
簡單的說就是能越少換網頁去獲取資料,就會是比較好的規劃。
規劃好後進到主題要如何開始爬蟲呢?
2.好的工具: 好到可以讓你升天
說到這篇是Python,那當然一定要有Python,我當下是使用MAC當作爬爬的工具,做好要讓它穩定的在其他設備(桌機)跑跑跑--->那就是選用Linux系統--->Ubuntu
有了電腦工具(廢話)
也要安裝相關套件:
如:最需要的使用工具就是Selenium套件(交給他說:簡單說他就是Web自動化測試工具集)、資料庫存取連線的套件 以及你要使用的 等等
3.一些用法:code
爬蟲爬到現在常用的套件應該就這些(這些應該會夠用XXD)
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
from selenium.common.exceptions import NoSuchElementException
from selenium.common.exceptions import NoAlertPresentException
import unittest
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time, re ,sys,os
from BeautifulSoup import BeautifulSoup
import urllib2
import datetime
import mysql.connector
import chardet
import sys
reload(sys)
sys.setdefaultencoding('utf8')
簡單介紹一下上面最常用幾個
from BeautifulSoup import BeautifulSoup
Beautiful Soup 是 python 的一個套件,最主要的功能是從網頁抓取資料。
2.MySQL 連線:
import mysql.connector
當然資動化的資料大部分都會存入資料庫,因此存取完後再去看資料就行了。
3.Selenium滑鼠、鍵盤等等可以透過它控制,以及一些網頁元素定位:
from selenium import webdriver
我使用後順暢的版本2.25
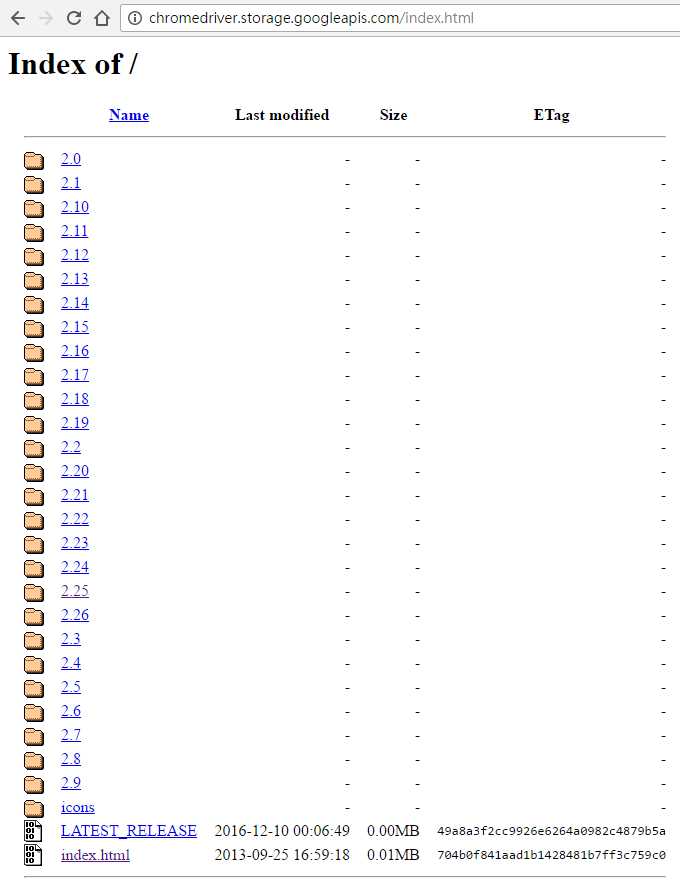
(#字號在python裡面是註解,要測試使用的化將"#"拿掉)
1.將上面下載下來的檔案放到相對的路徑,並且在程式裡面設定路徑
範例:
#chromedriver = "/Users/user/Desktop/chromedriver"
2.將Browser開啟
#driver = webdriver.Chrome(chromedriver)
3.餵網址給Browser網址並開啟網頁
以學聯網當作網頁URL範例
sourceurl = 'http://www.sharecourse.net/sharecourse/course'
driver.get(sourceurl)
1.操作需求:可能需要按按鈕Btn、選擇TextBox、登錄網頁(帳號密碼)、輸入資料、觸發JavaScript、控制鍵盤、控制滑鼠等等等,只要人做得到的都可以做相對應的控制
並且開啟萬能的檢查 快速鍵(Ctrl+Shift+I)或是F12
右側點選打勾紅色去選擇你想要知道的元素名稱(DIV的 ID、或是Class、或是Style)
後續會介紹那些 div的 ID、或是Class、或是Style ====>>就是靠這些作為定位的方式獲取相關資訊

2.開啟網頁後(開到你需要的網頁頁面)
透過BeautifulSoup將HTML相關資訊Load出來
soap = driver.page_source
soap = BeautifulSoup(soap,fromEncoding="UTF-8")
爬到現在,上面很重要的是"fromEncoding="UTF-8",加入這個UTF-8編碼一樣的好的可以讓你升天,透過他編碼,可以讓有些網頁數據編碼問題,讓編碼順利,因此才不會亂碼。
3.開始定位HEML資訊讓你取得你要的相關資訊
如: 定位(如上面所敘"網路爬蟲的規劃"規劃對的規則出來)
mydivs = soap.findAll("div", { "style" : "width:950px ; height:150px"})
抓取到的規則
因此mydivs的規則皆為每個列的資訊規則
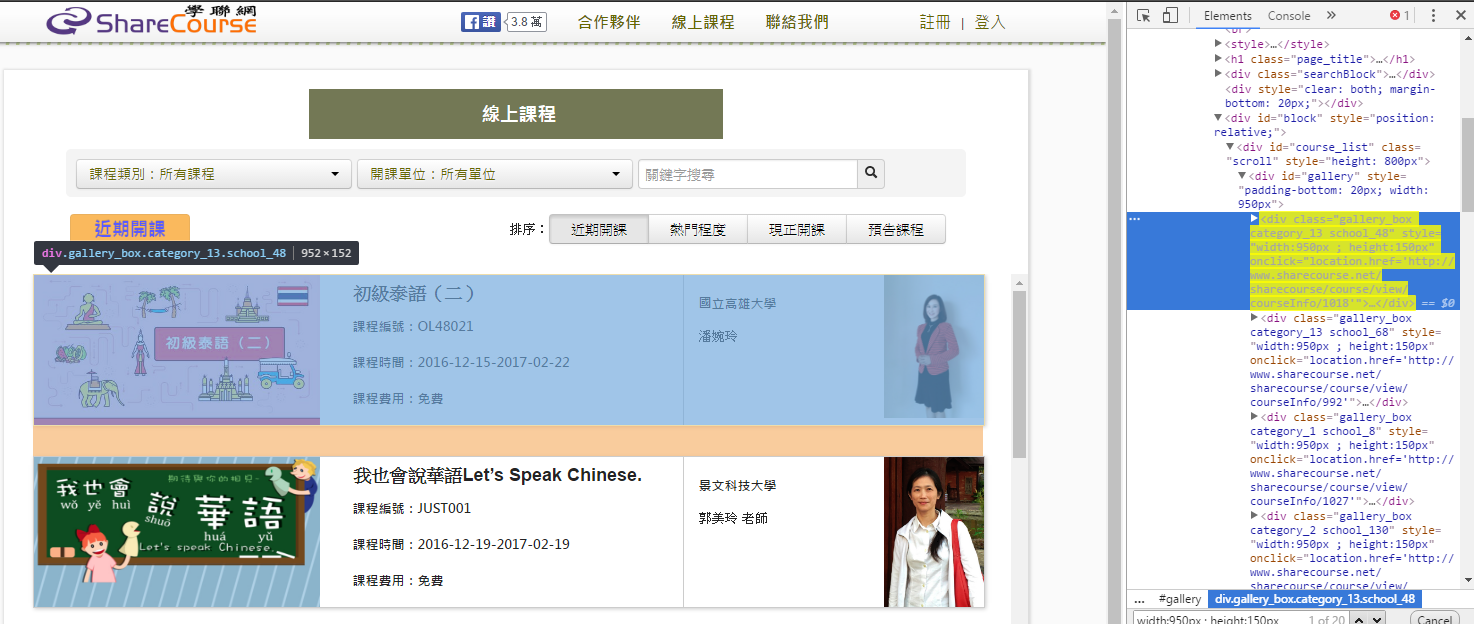
抓取到每一格行列的內容,透過For圈的方式去獲取相關資訊
for x in mydivs:
#課程名稱
course = x.findAll("h4",{"id":"courseName"})
#取得"課程名稱後"透過text取得裡面的字
courseName = course[0].text
#網址URL的部分
url = x.get('onclick')
url = url.replace('location.href=\'','')
parserUrl = url.replace('\'','')
因此這一頁(URL)頁面的相關資訊都可以使用這些方式取得
取得到課程的名稱、課程的URL等等。。
4.做一些相關滑鼠動作:
driver.find_element_by_id("category").click()
由下圖可得知,課程類別的ID為"category",透過"driver.find_element_by_id"的方式取得後,在做Click()即可達到滑鼠點選Box的功能

driver.find_element_by_link_text(lists[i]).click()
因為事先有先預設一些List在程式裡面,做text點選用
例如:
lists = [u"資訊工程:系統、資訊安全、網路",u"資訊工程:程式設計、軟體工程",u"資訊工程:理論",u"經營管理:經營策略",u"智慧媒體:行動、網站開發", ..........................,u"通識教育:環保永續",u"通識教育:科學教育、生活醫藥",u"科技社會:設計"]
再透過for迴圈的方式更換list[i]的內容,再進行click()點選
有很多可以選擇的,如上面使用的ID、TEXT等等之後再一起做至整理給大家XXD
4.網路數據採集的法律與道德約束
如: Python網絡數據采集 一書(好書)即有談到

附錄C page188 則提到過去網路爬蟲相關採集法律與道德

事後補充更詳細的爬蟲方式,如:爬蟲遇到的困難重重如何解決,如何架設設備做分量分批等等。。。
如有任何問題都可以留下XD