報表視覺化的第一步,除了下載並安裝 Desktop之外,就是準備資料來源。以現今的技術,你已經不需求去考量資料的來源是否為關聯式資料庫、Flat file、沒有提供底層資料庫給你的 Saas服務…只需取得資料來源的存取權限。本文將會介紹視覺化三部曲中的第一部,資料連接~~
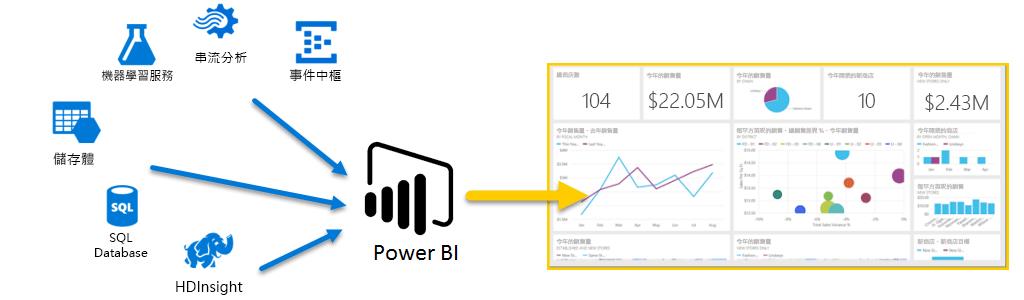
本文是基礎於前一篇Overview所繼續延伸的議題,要來各位探討如何實現報表視覺化的第一步,資料連接~
在開始之前,先要闡述一個很重要的觀念,在In-Memory的技術下,BI solution的硬體投資,已經由重兵佈署的後端伺服器,改到了前端的個人電腦(記憶體)了。所以企業在導入新一代的 BI 解決方案,首要的任務是Sizing PC/NB的 Spec,儘可能提供前端所需的記憶體給員工。
其次是資料在載入時,千萬不要照單全收,一定要篩選有使用到的欄位,欄位如果不夠,將來是都可以再額外添加的。否則將會造成 garbage in garbage out 個人電腦跑不動的慘案。
第三,在 Desktop上的所有操作都不會影響資料的源頭,它是一個允許的修改的單向複本。例如,為了方便,我可以在整合異質資料來源時,將某個 Table中的欄位做 Rename,以利系統可以偵測到相同的欄位名稱,自動幫我完成關聯。或是原始的欄位太長,為了排版我可以 Rename某個欄位,該報表更漂亮。既然系統提供了彈性,會不會衍生做報表的人偷改數據的風險?答案是不會!因為它值Value是Ready only,你只能改動它的屬性(Column name, data type...)
第四,則是資料儘可能存放在雲端,才能得到較好的更新頻率。例如,一樣是 Excel,在某個員工的電腦,跟 One drive的雲端儲存空間中,除了單點式限制存取(有鎖定行為) v.s. 分散式多人存取差別之外,雙方在 Sizing(空間擴展性)、Scaling(將來增加空間是否需要停機)、Available time(後者是不限上班時間的 7*24)、HA(後者有三份備援)。所以當你放在員工電腦內,你是需要 on demand 的手動更新它;當你選擇雲端空間,每個小時至少會自動更新一次。
第五,是了解資料來源的必要條件與 Desktop的關係,當 Desktop 在連結資料的當下,是需要打通底層的 Protocol 例如資料庫的 driver,才能實現以 table 形式的資料溝通。當你遇到初次的連線建立異常時,是可以到官網取得所需的版本資訊來處理的
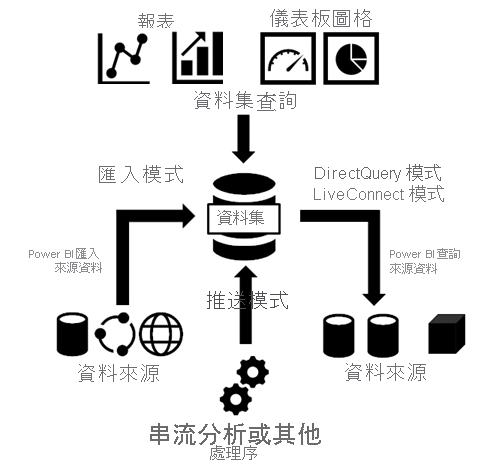
- 連接模式:在Power BI中提供了 Import與 DirectQuery 二種模式,前者是透過載入前端 PC/NB 記憶體,來設計、開發視覺化報表,當報表做好並且發佈至雲端時,系統會強迫你儲存當前的報表至 *.pbix,並將記憶體中的資料一邊壓縮,一邊打包成模型後再上傳上去。前者雖然有1GB的空間上限,但是透過 VertiPaq 技術可以達到十倍的壓縮比(細節可以參考官網),如果企業不願切分資料(依時間、部門、產品)堅持要全上,可以考慮 Power BI Premium 將壓縮後13 GB的模型上傳至雲端。
為了效能的優化,建議除了透過產品的標準的壓縮功能,還可以透過:透過M語言篩選資料來源、移除不必要的資料行(又稱為垂直篩選)/資料列、分組依據及摘要(改變資料顆粒度)、最佳化資料行資料類型、停用 Power Query 查詢載入/自動日期/時間、切換到混合模式…等手法
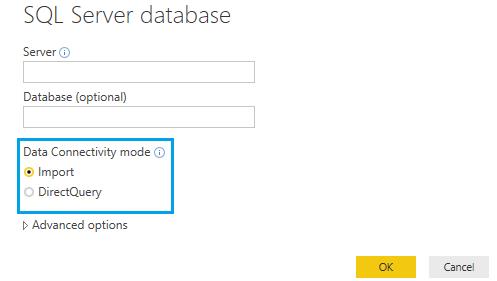 最大的好處是,不需要針對看報表的人在資料來源(例如資料庫)額外開立存取權限,因為報表是內含資料。但取而代之的是,可以在Power BI Service中設定相關的權限管理機制,這個部份將來會講到。
最大的好處是,不需要針對看報表的人在資料來源(例如資料庫)額外開立存取權限,因為報表是內含資料。但取而代之的是,可以在Power BI Service中設定相關的權限管理機制,這個部份將來會講到。
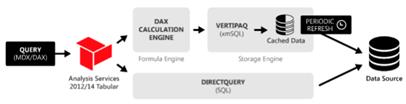
至於 DirectQuery(目前預計的上限是10個),因為只有儲存 Query 的條件,相對來說,這些 meta data佔硬碟的空間不過就是2~3位數 KB而已。但是,你必需了解的是,為何它不是預設的模式?首先是對企業中 Mission critical系統的效能衝擊,由於在這個模式下,Power BI service將不提供 Caching,所以每多一個看報表連線上來,都會對這些系統(例如 ERP, MES...)帶來額外的負擔。故,大多,都是因為單一 pbix遇到1GB的上傳上限,或是不滿意報表的更新頻率、安全性(想透過 Cube已經設計好的權限)、資料顆料度(例如遇到年度預算與月業績報表不一致)才會被採用。
 在 Tableau 一樣是有提供 Extract 與 Live模式,而且在 Extract 還有分舊版的 TDE與新版的 Hyper
在 Tableau 一樣是有提供 Extract 與 Live模式,而且在 Extract 還有分舊版的 TDE與新版的 Hyper
 點選編輯
點選編輯
 細節可以參考官網的說明
細節可以參考官網的說明
- 連接資料:在Power BI中你可以透過 Get Data來連接你的資料來源
![[常用] 功能區上的 [取得資料]](https://docs.microsoft.com/zh-tw/power-bi/connect-data/media/desktop-quickstart-connect-to-data/qs-connect-data_02.png)
接下來系統會列出不同類型的資料來源,例如檔案、資料庫、Azure、線上服務…等不同的類型
![[取得資料] 的所有來源](https://docs.microsoft.com/zh-tw/power-bi/connect-data/media/desktop-quickstart-connect-to-data/qs-connect-data_03.png)
以Excel為例
系統會偵測當前的 Excel裡面有多少 Sheet、Table…等內容
![在 [導覽器] 視窗中選取資料](https://docs.microsoft.com/zh-tw/power-bi/connect-data/media/desktop-quickstart-connect-to-data/qs-connect-data_05.png)
同理對 Tableau 來說,也是連結資料來源,從下圖中,你不難看的出來為何這二家可以在 Gartner的魔術象限的右上角稱霸那麼久!
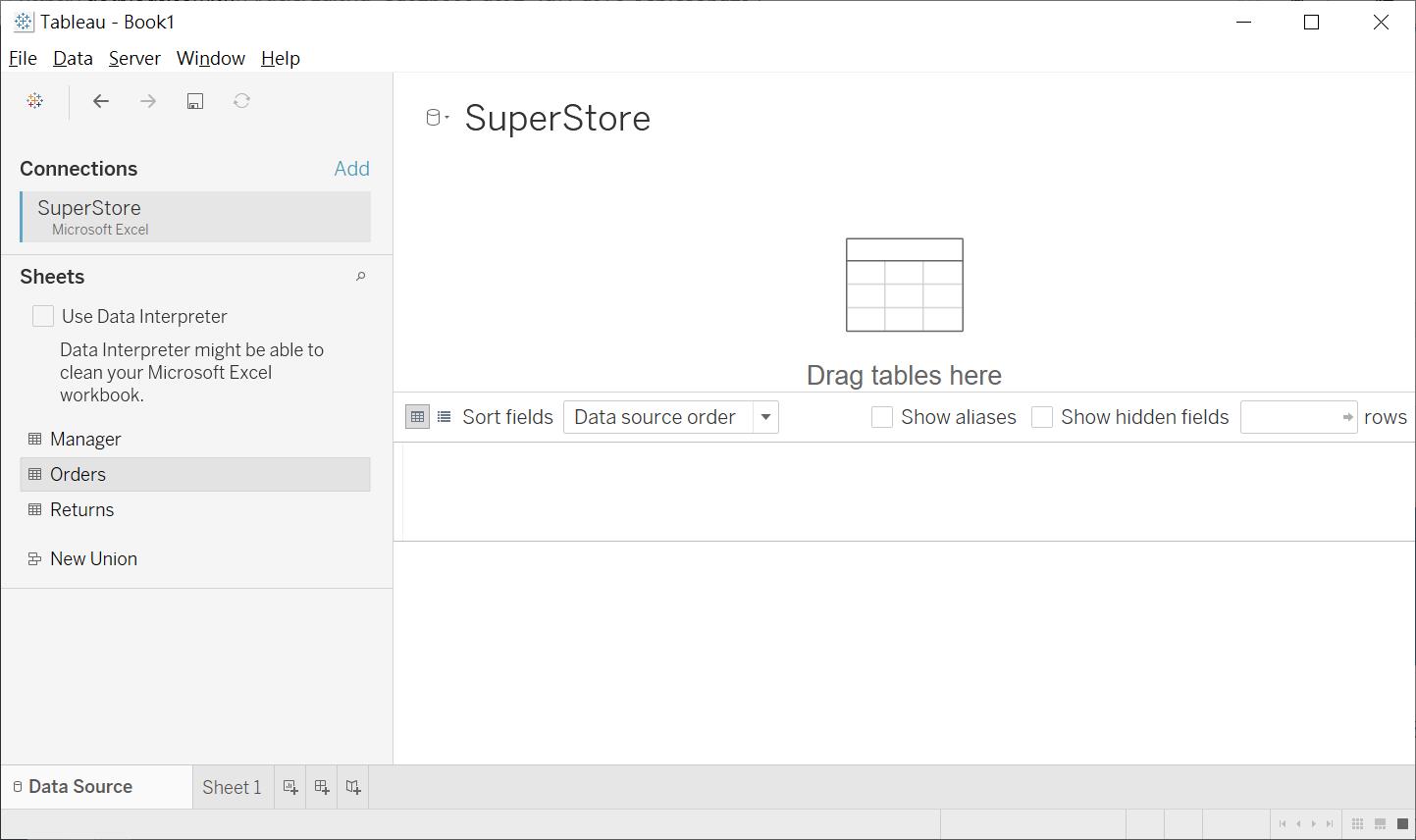
 以Excel為例,當我們選擇所需的 SuperStore檔案後,可以得到以下畫面,左下角有三個 Sheet可供分析,右上角是關聯性的設定區域,右下角是資料值/資料欄位(資料格式)的預覽/編輯區域
以Excel為例,當我們選擇所需的 SuperStore檔案後,可以得到以下畫面,左下角有三個 Sheet可供分析,右上角是關聯性的設定區域,右下角是資料值/資料欄位(資料格式)的預覽/編輯區域
- 資料前處理:你知道嗎?絕大多數的人,在上面的畫面都不假思索地按下了Load載入,成為災難的開始!鮮少有人會知道要按下Edit編輯,阻止這場可怕的災難!
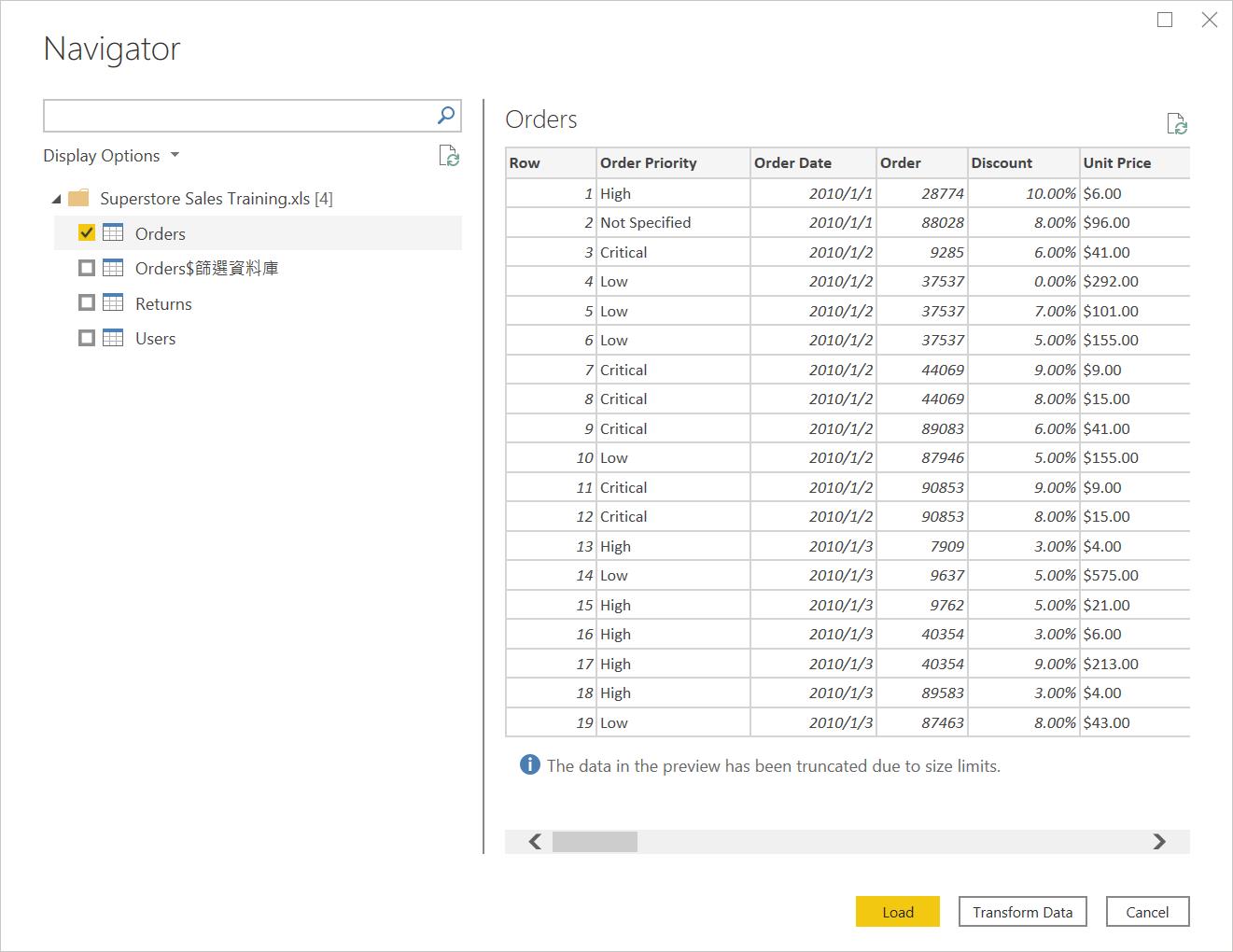 當我們按下Transform Data 或Edit(舊版)將會跳出基礎於M語言的 Query editor,可以讓我們進行資料的前處理。
當我們按下Transform Data 或Edit(舊版)將會跳出基礎於M語言的 Query editor,可以讓我們進行資料的前處理。
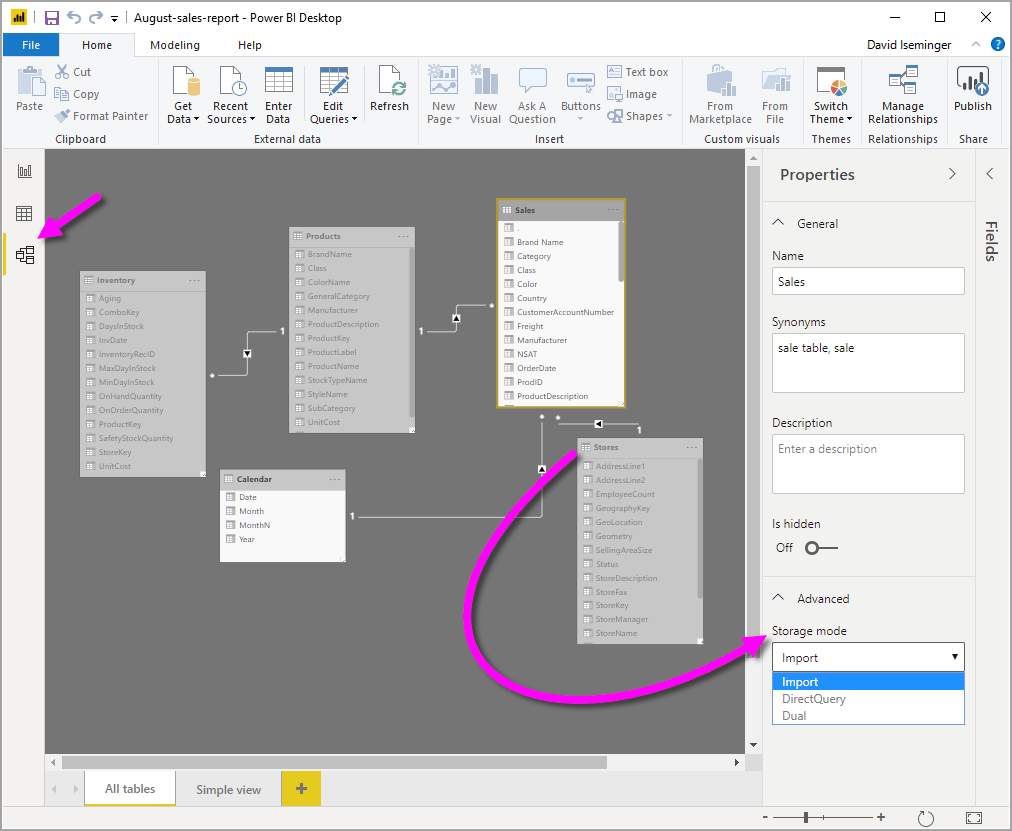
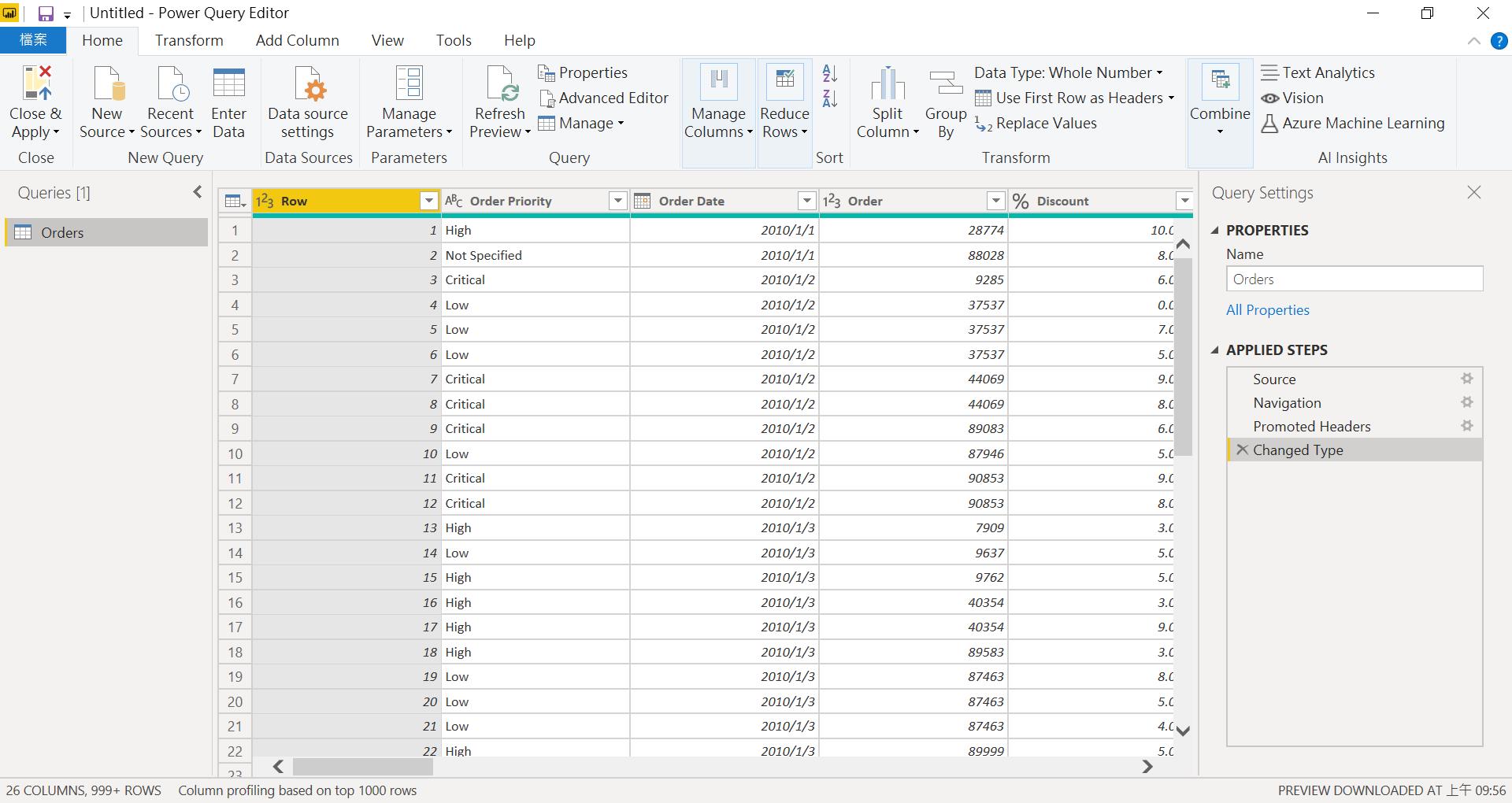 在畫面中,我們的對象(在左邊)是Queries[1]某一個資料來源(可以是 Excel sheet, DB table, Saas CRm…),裡面包含了數個欄位(在中間的區域),(在右邊)你可以找到 Properties是可以編輯這張Table的名稱,Applied steps則是會記錄你所有的操作,當你後悔某些動作,你是不需要全盤重來,是可以針對特定的動作進行刪除
在畫面中,我們的對象(在左邊)是Queries[1]某一個資料來源(可以是 Excel sheet, DB table, Saas CRm…),裡面包含了數個欄位(在中間的區域),(在右邊)你可以找到 Properties是可以編輯這張Table的名稱,Applied steps則是會記錄你所有的操作,當你後悔某些動作,你是不需要全盤重來,是可以針對特定的動作進行刪除
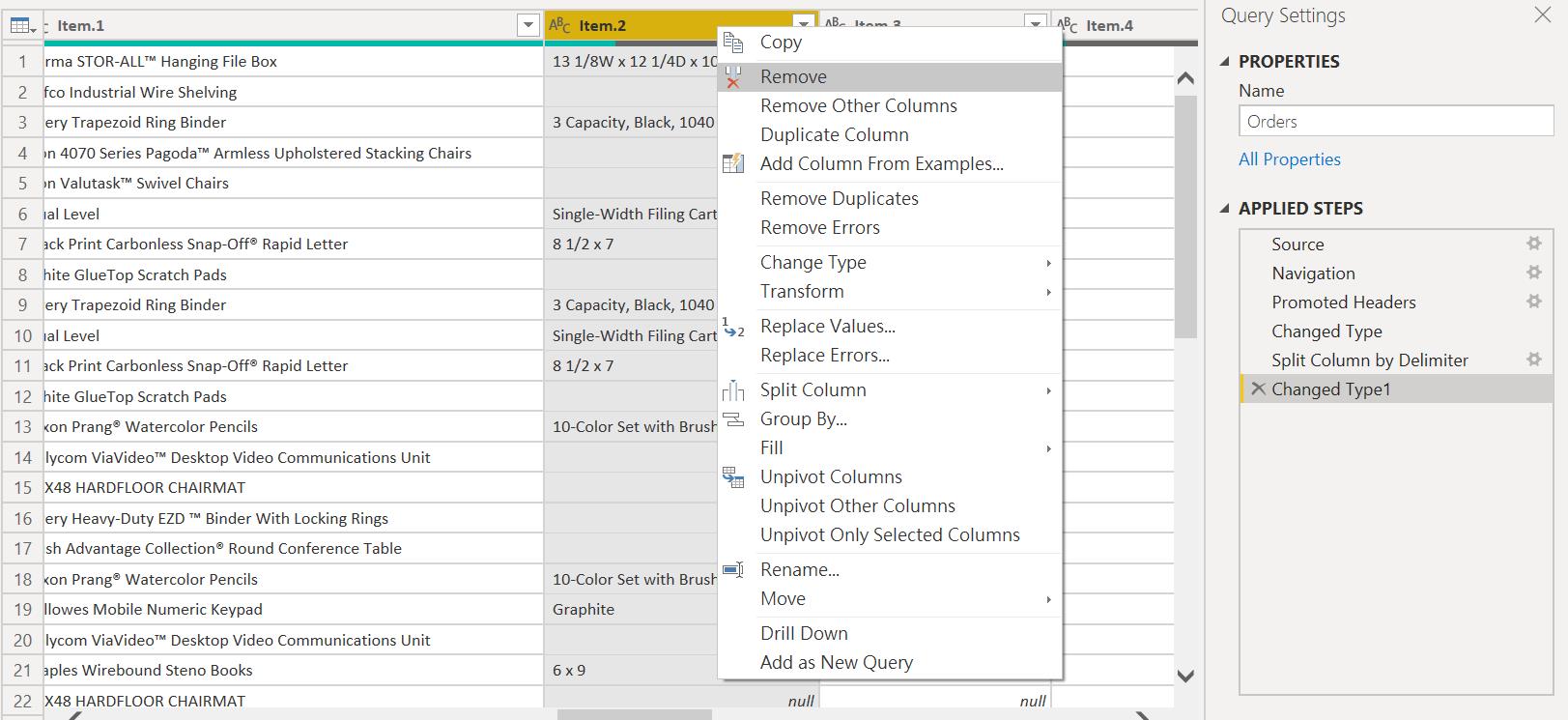
舉例來說,如果 Item 產品品項這個欄位逗點的右邊報表上是用不到的,我們應該要阻止它進入記憶體。操作時,你可以對著欄位按右鍵 Spilt Column 將它切分為 Item.1 & Item.2,然後對著 Item.2 按右鍵選擇刪除。或是由工具列中找到刪除欄位的功能
 最後,當你完成資料的前處理之後,可以在最左上角,找到Close & Apply 關閉並套用,讓系統開始載入記憶體
最後,當你完成資料的前處理之後,可以在最左上角,找到Close & Apply 關閉並套用,讓系統開始載入記憶體
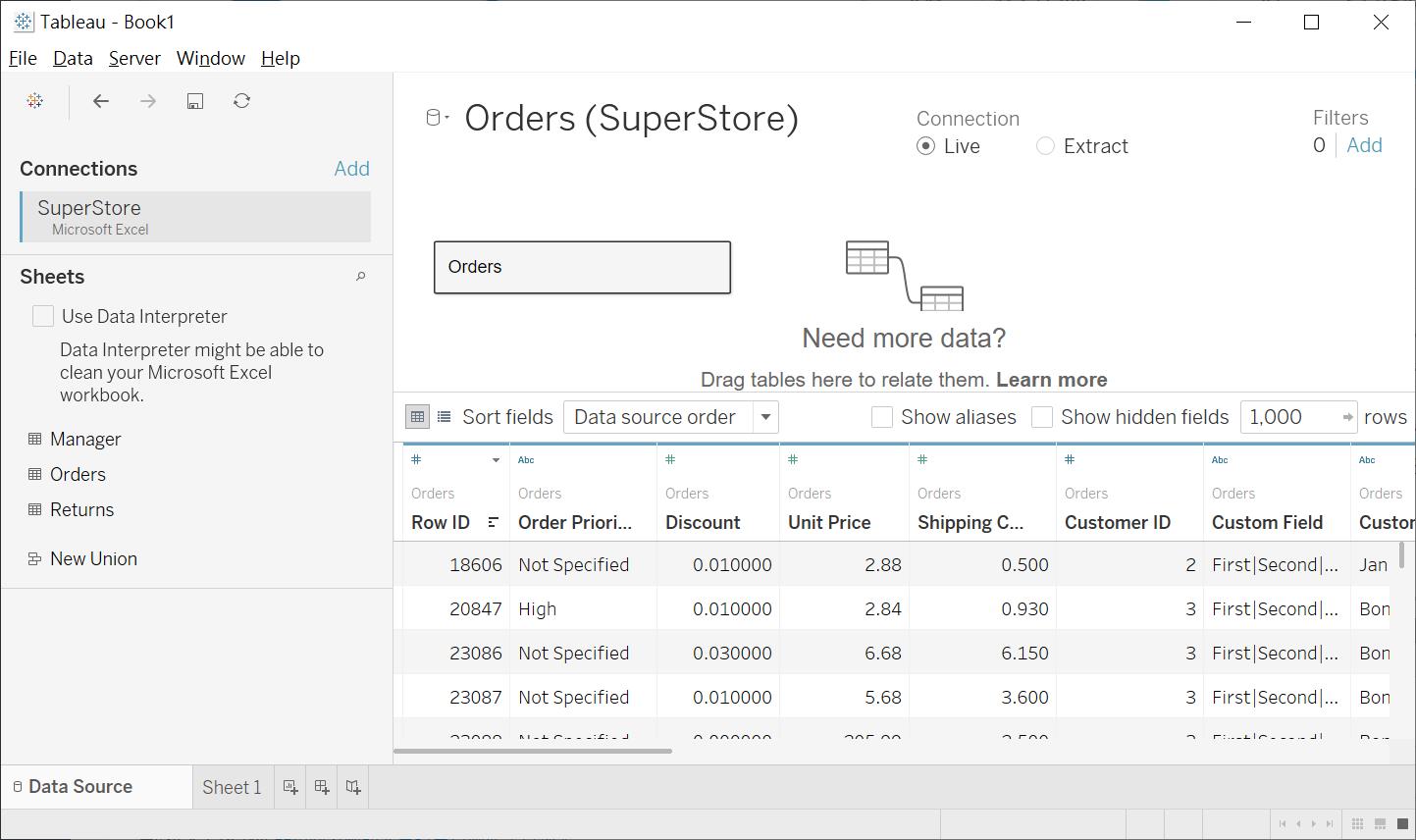
在 Tableau 其實有更強大且直覺的 Prep builder工具,可惜受限於篇幅。我在這裡僅能介紹 Desktop 的 Metadata管理功能。當我們透過 Double click或是 Drag & drop把 Table放置於右上角,右下角將會以預設的 Preview data source的模式,進行資料的預覽
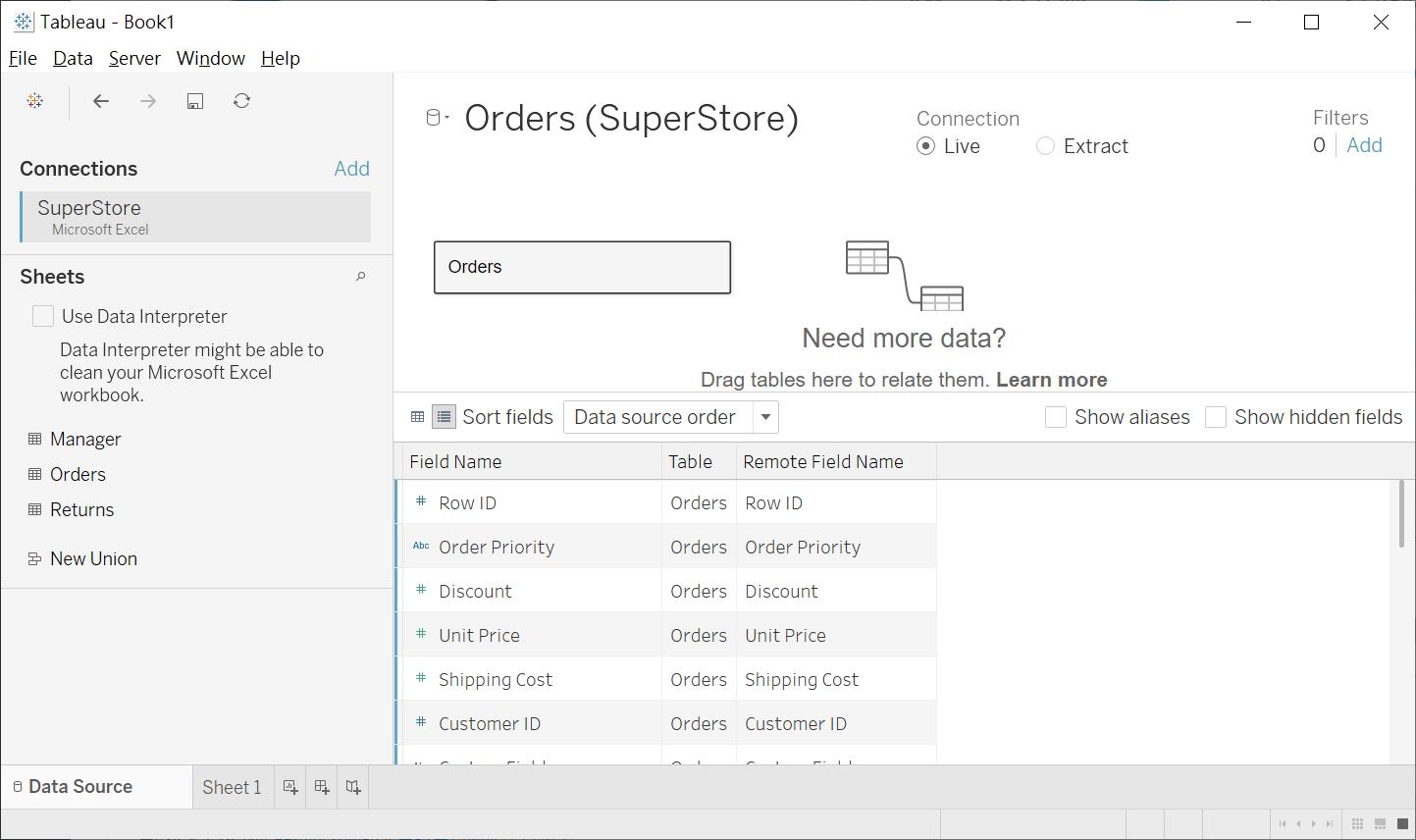
 接下來我們要從右上與右下交界處,找到有二個 Icon的區域,並且將它切換成 Manage metadata
接下來我們要從右上與右下交界處,找到有二個 Icon的區域,並且將它切換成 Manage metadata
 映入眼簾的畫面,將會改成不帶數值的資料欄位,我們可以輕易地進行Rename更名(讓系統可以自動偵測出關聯性,如果二個 Table 間的欄位名稱並不一致)、修改資料型態(例如將2002/12 辨識為Text的"年月"欄位,改成 Date)、新增別名(以利報表中排版或群組呈現的效果)…等操作
映入眼簾的畫面,將會改成不帶數值的資料欄位,我們可以輕易地進行Rename更名(讓系統可以自動偵測出關聯性,如果二個 Table 間的欄位名稱並不一致)、修改資料型態(例如將2002/12 辨識為Text的"年月"欄位,改成 Date)、新增別名(以利報表中排版或群組呈現的效果)…等操作
- 資料關聯性:當我們在Get data之後,經過篩選決定了要讓哪些 Table與Column進來後,接下來要依據一對一;一對多;多對多的關係進行Relation ship的設定。
**由於篇幅有限,本文將不介紹二大陣營都有支援的 Inner, full, left, right, Union 五種基礎的資料關聯方式。另外,也為了聚焦在資料分析二者都不支援 Cross join (這是一種列舉出 A & B Table 所有笛卡兒乘積組合的手法)
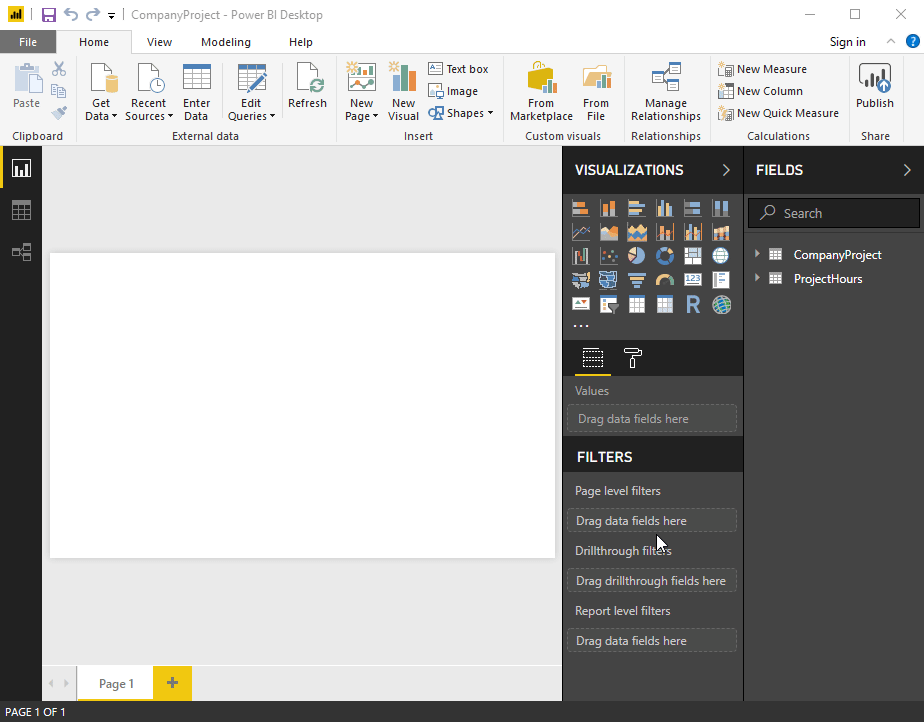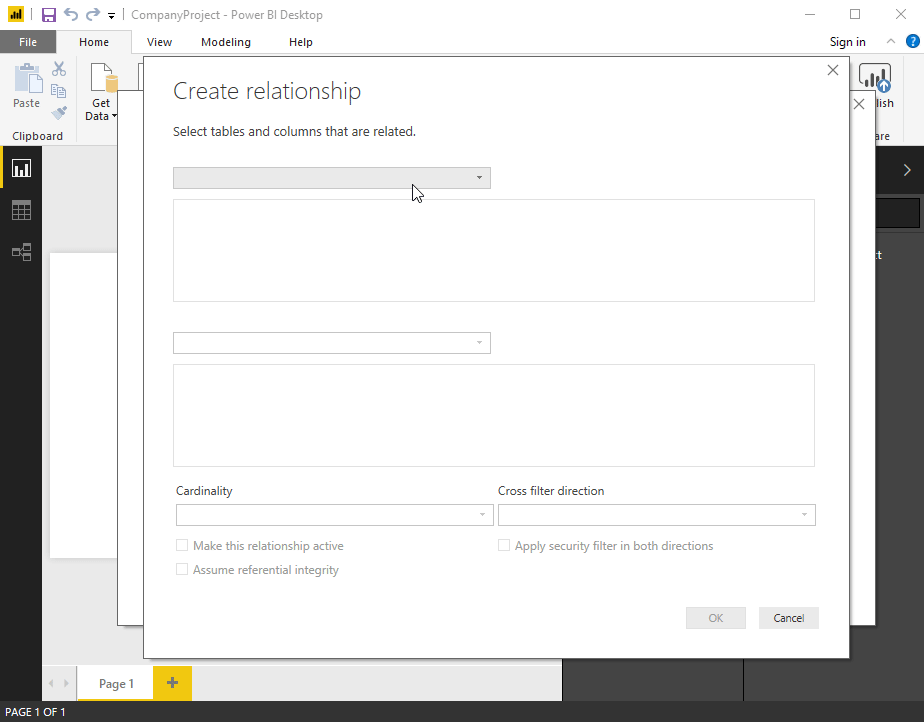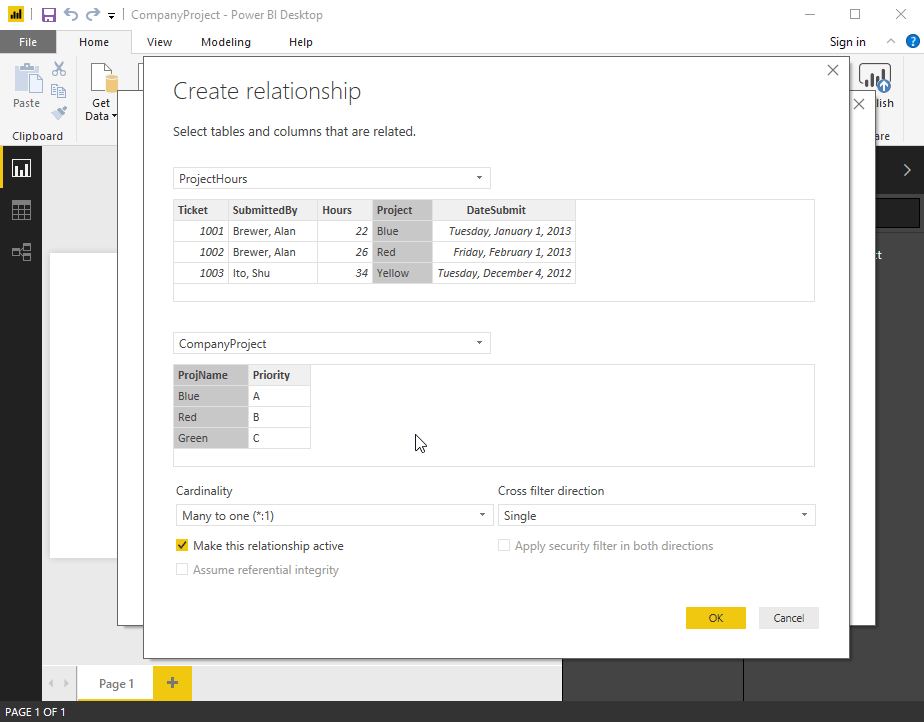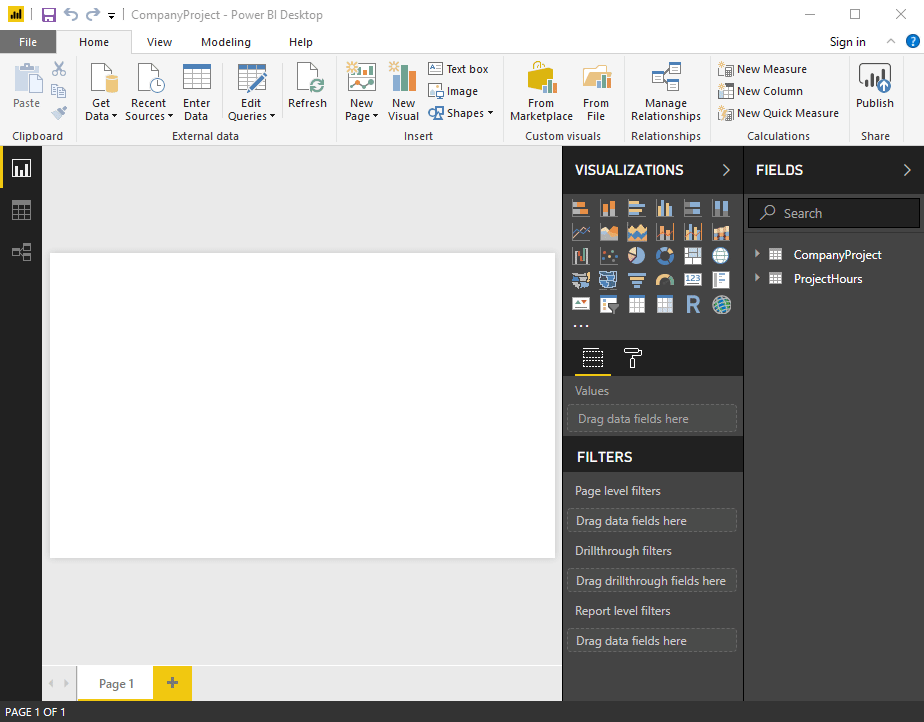
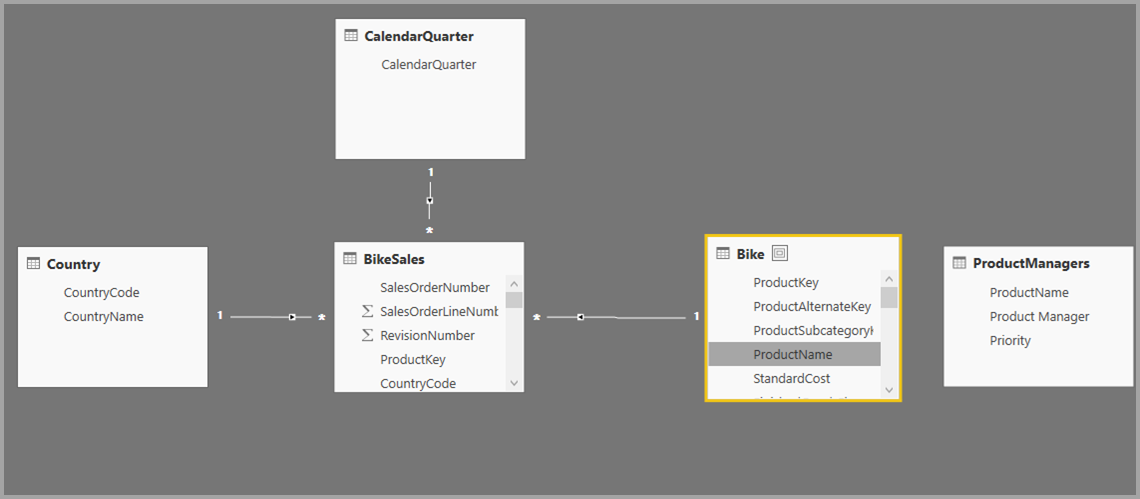
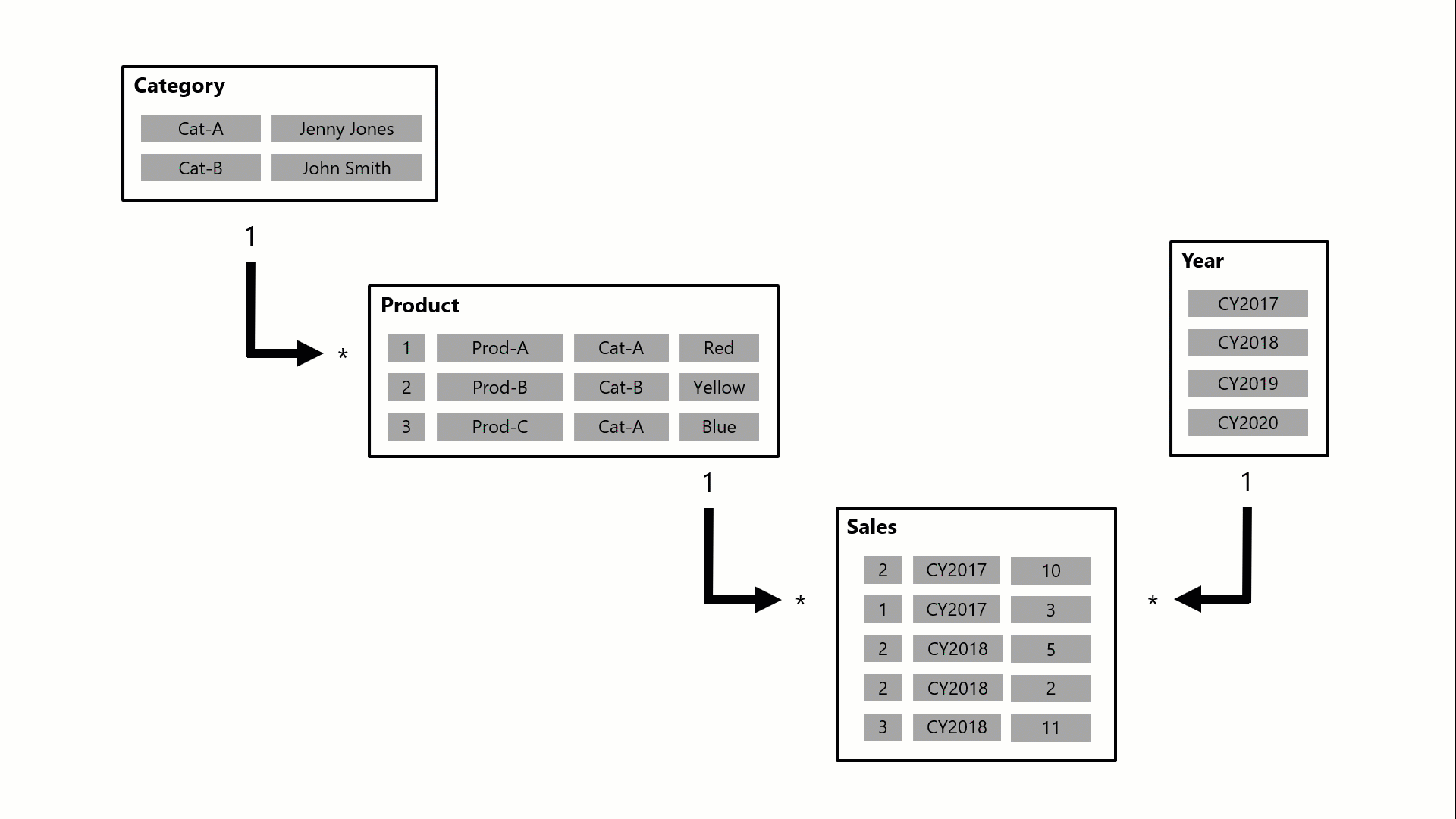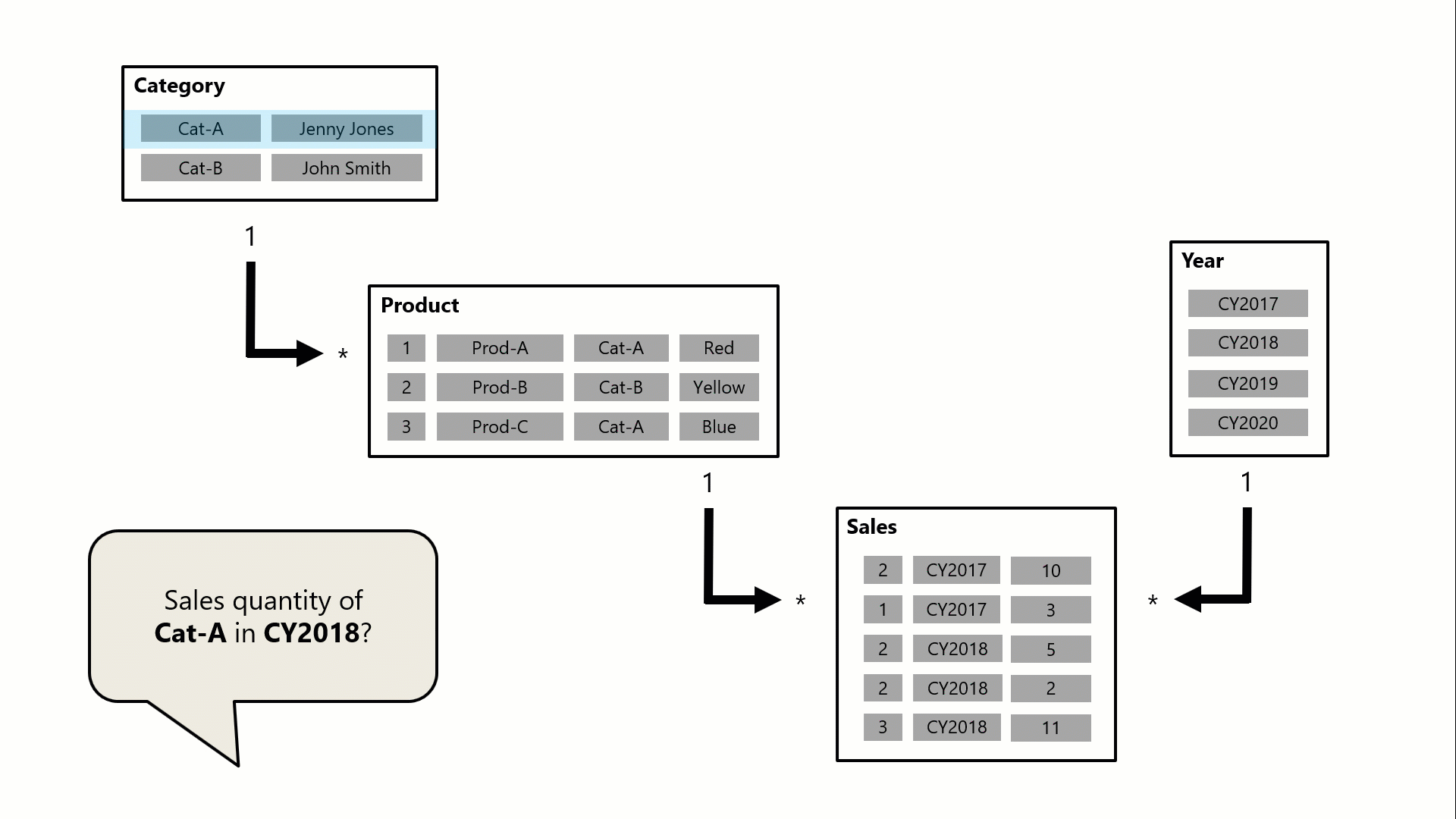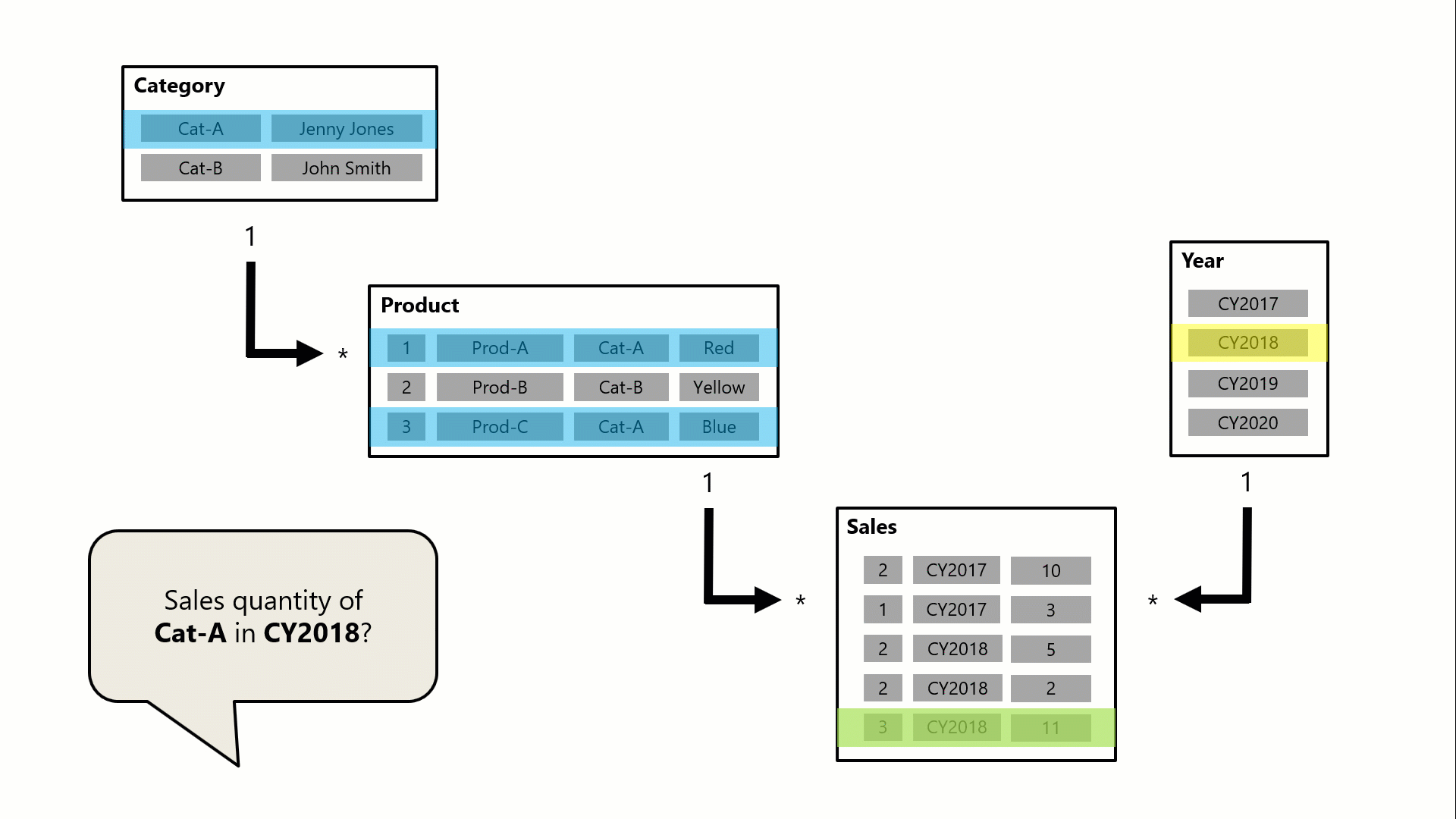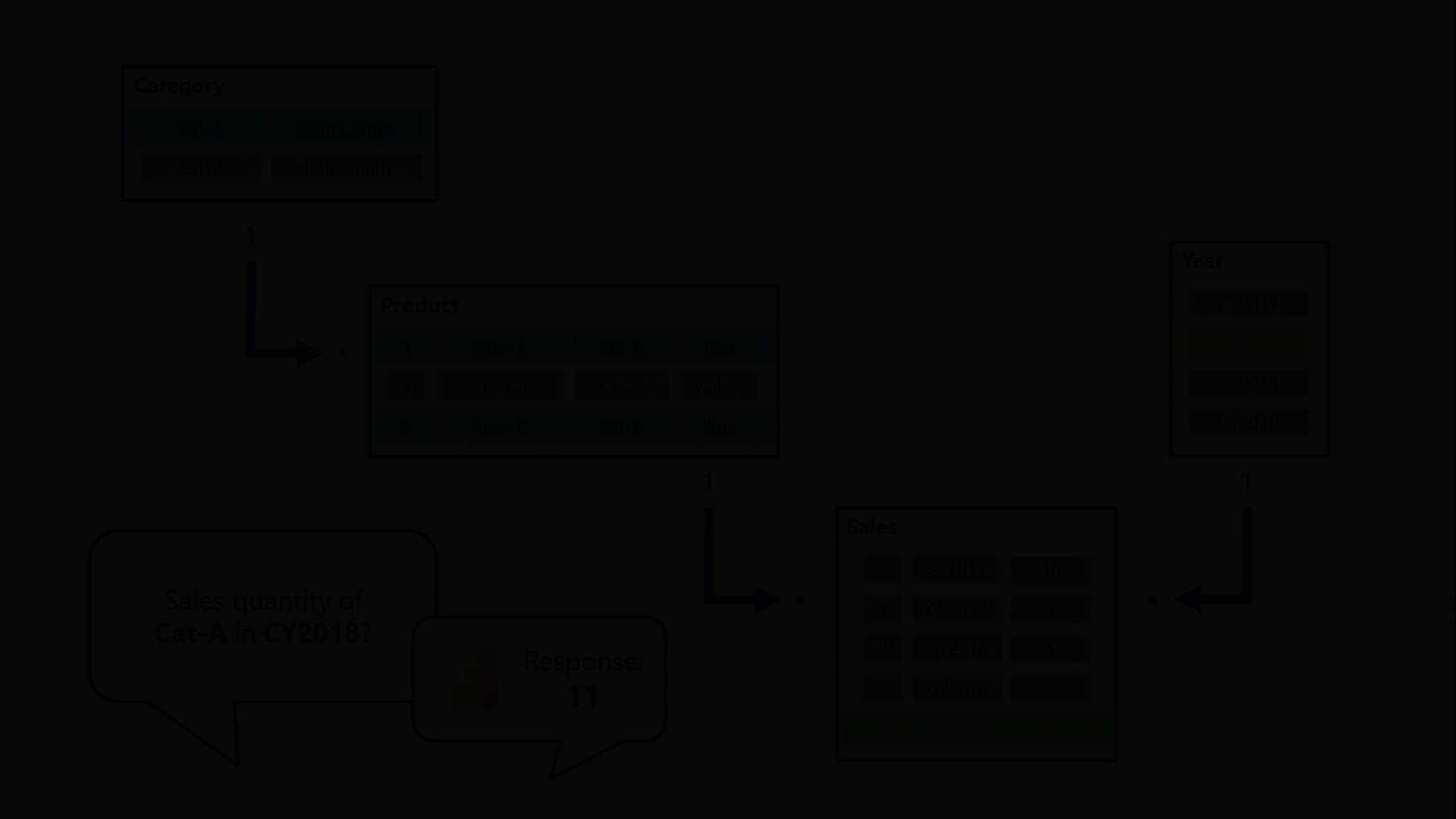 在上圖中共有 Category、Product、Year 和 Sales 四個 Table。其中,Category 類別與 Product 產品有一對多的相關,而 Product 產品與 Sales 銷售有一對多的相關。Year 財年與 Sales 銷售有一對多的相關。本範例是想透過 Power BI Card卡片,來顯示 Cat-A 單一類別在 CY2018 那一年的總銷售數量,經過多對多的關係設定,我們不用額外新增一個 Table,維持所有 Table間都是一對多的關係。算是一個快速的捷徑,這個多對多在 Power BI與 Tableau都有支援,真的很方便!
在上圖中共有 Category、Product、Year 和 Sales 四個 Table。其中,Category 類別與 Product 產品有一對多的相關,而 Product 產品與 Sales 銷售有一對多的相關。Year 財年與 Sales 銷售有一對多的相關。本範例是想透過 Power BI Card卡片,來顯示 Cat-A 單一類別在 CY2018 那一年的總銷售數量,經過多對多的關係設定,我們不用額外新增一個 Table,維持所有 Table間都是一對多的關係。算是一個快速的捷徑,這個多對多在 Power BI與 Tableau都有支援,真的很方便!
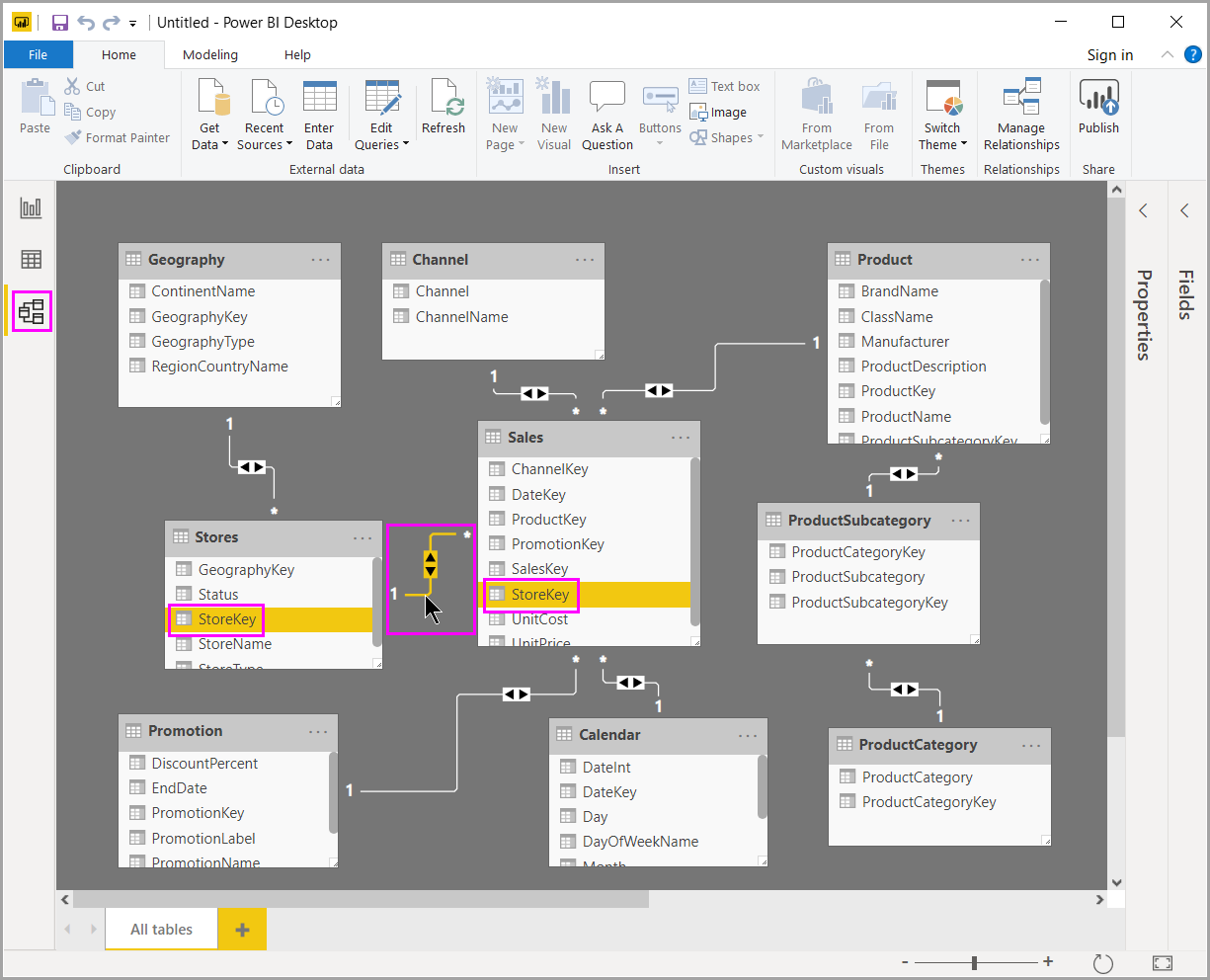
另外在 Power BI中是有自動偵測/手動維護關聯性的作法的,操作方法如下:
手動
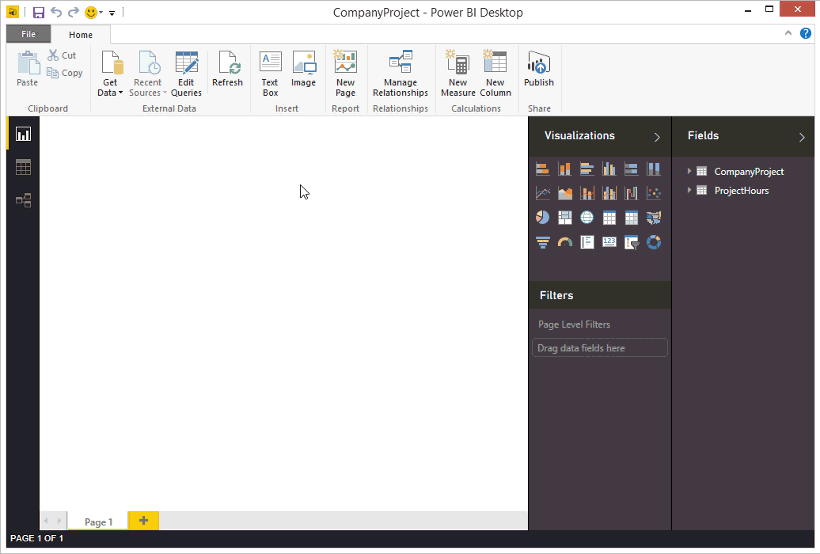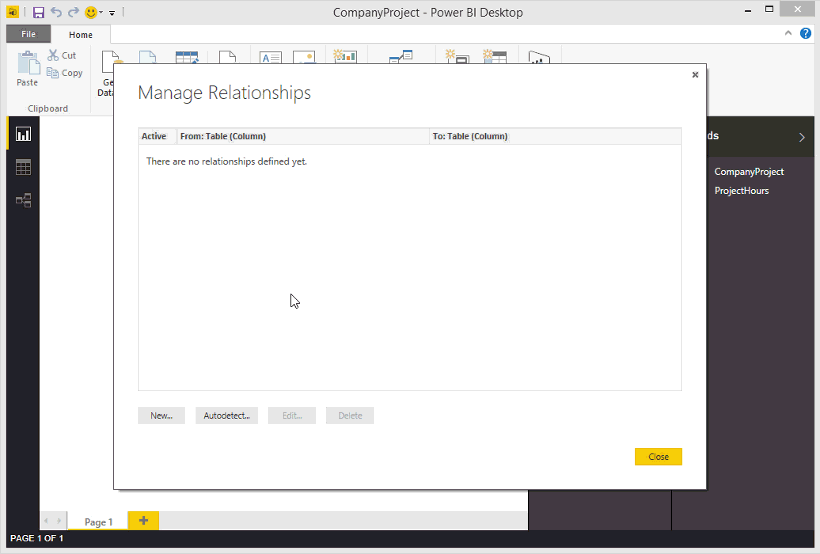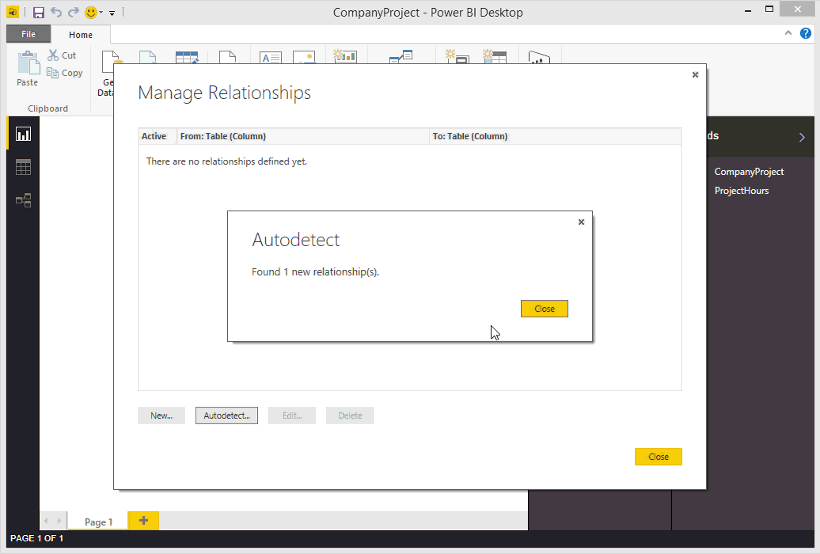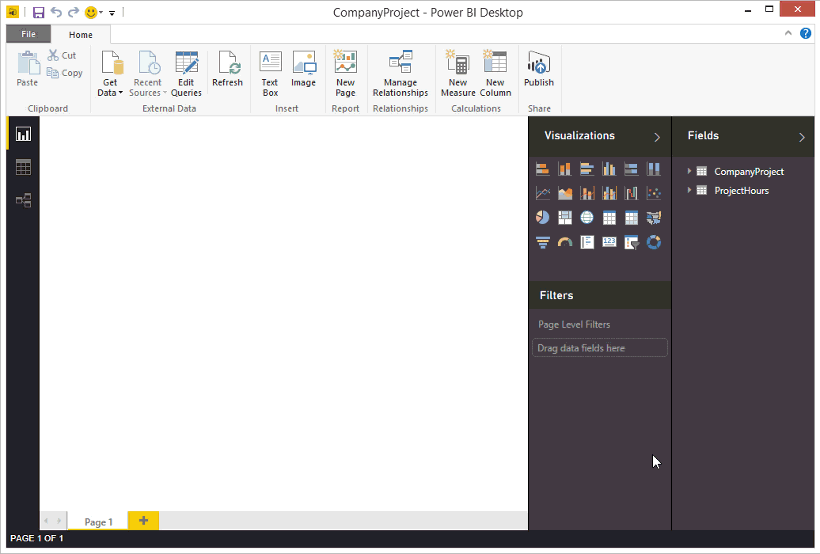
 回顧一下上述的多對多範例,我猜很多人都是第一次聽到這個名詞,到底這個關聯性要怎麼實現呢?首先,你需要切到Relationship關係的頁籤
回顧一下上述的多對多範例,我猜很多人都是第一次聽到這個名詞,到底這個關聯性要怎麼實現呢?首先,你需要切到Relationship關係的頁籤
![Power BI Desktop 中的 [模型檢視] 圖示](https://docs.microsoft.com/zh-tw/power-bi/transform-model/media/desktop-modeling-view/modeling-view_02.png)
由於大多都是存在著一對多的關係,系統是可以依據欄位名稱/PK/FK 自動套用預設的關係,並且自動偵測哪邊是一?哪邊是多?以下就是自動帶出來的結果
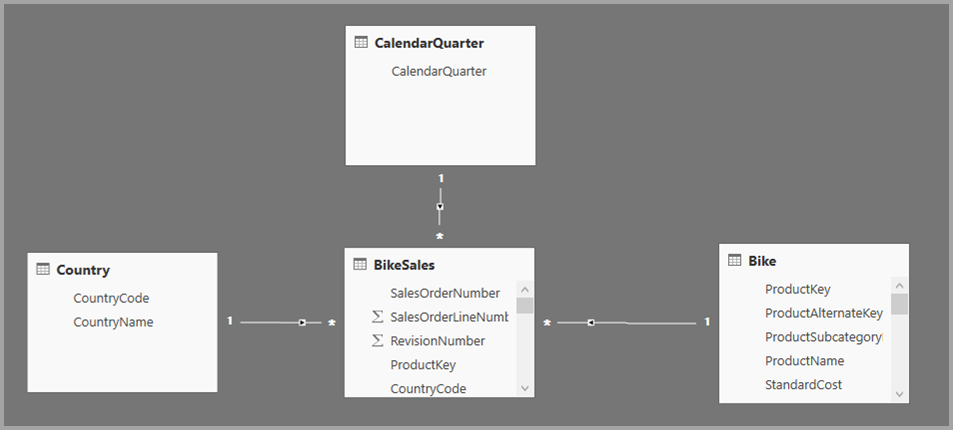
然後就可以切到報表設計的頁籤開始做報表,請注意,萬一表格中,所有的數值的資料都是重覆同一筆,就是關聯性有問題,你可以隨時切回來做修改
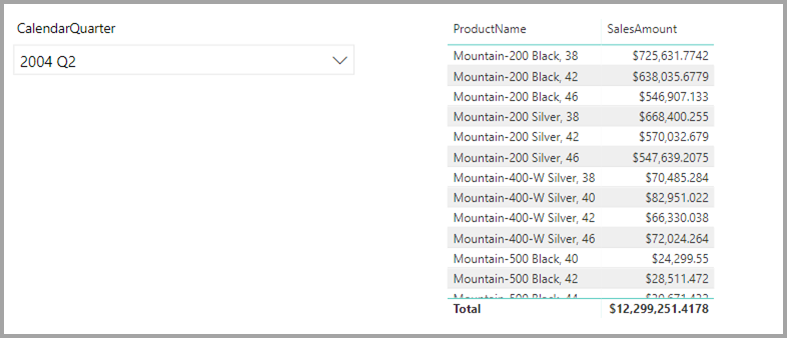
自動偵測真的很方便,但如果你是混合異質資料來源,系統偵測不出來,例如Google Analytics 與 Excel時就會需要用滑鼠自行拖拉。以下的範例,就是基礎於上述的資料來源,再加入另一個產品主管的資料來源,並透過 ProductName來關聯,進而滿足使用者對於報表內容的需求。
![[導覽器] 視窗](https://docs.microsoft.com/zh-tw/power-bi/transform-model/media/desktop-composite-models/composite-models_06.png)
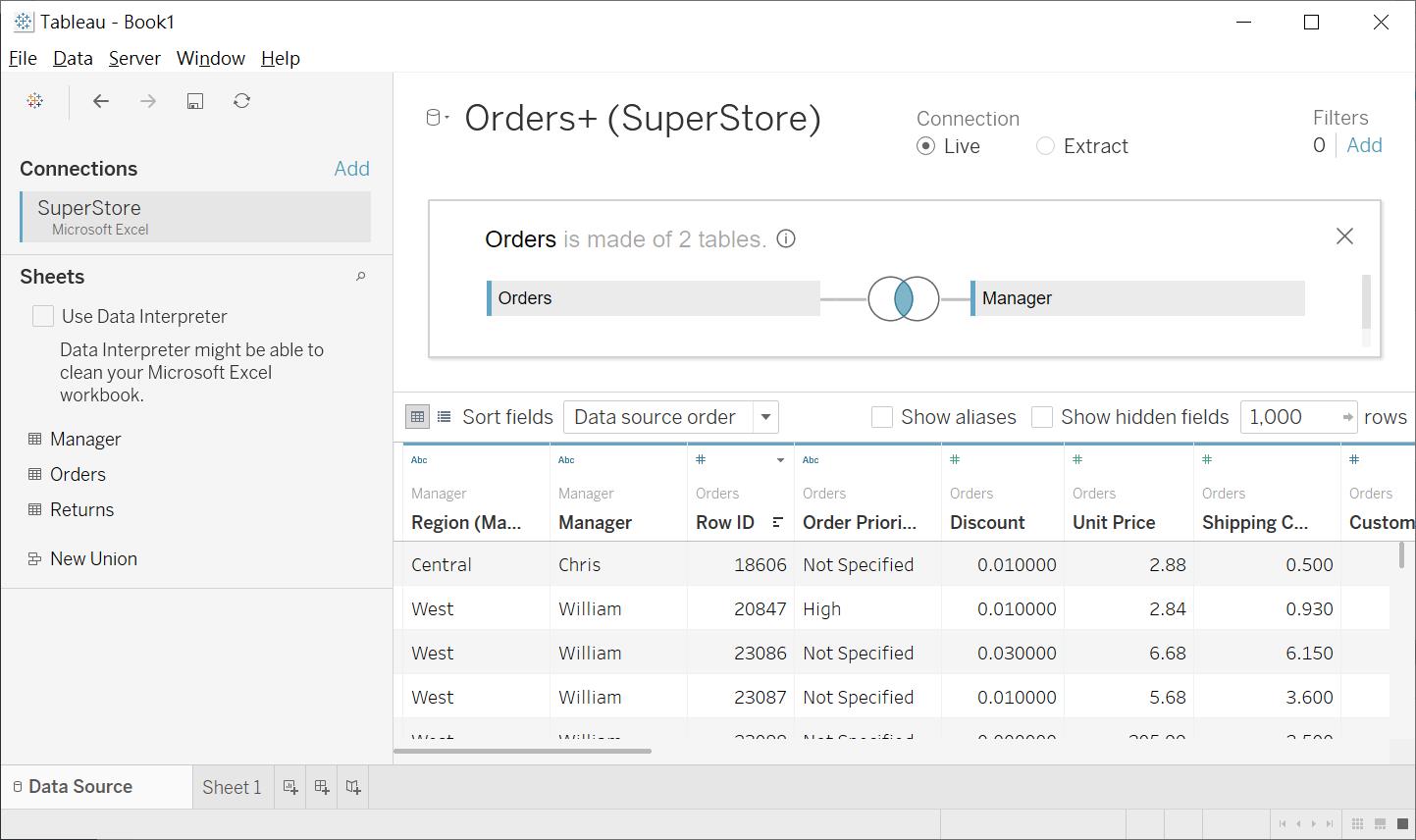
當我們檢視完資料,就可以按下Load載入這件 Excel。載入後,可以由右邊的欄位Fields中,看到有新的 Table被加進來
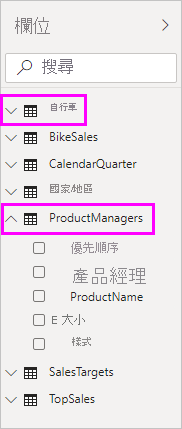
所以我們可以切回關聯性頁籤來檢視
雖然二邊的 Table都有 ProductName,但由於他們不是一對多的關係,系統並沒有直接關聯他們,所以我們需要人工拖拉並維護其關聯性
![[建立關聯性] 視窗](https://docs.microsoft.com/zh-tw/power-bi/transform-model/media/desktop-composite-models/composite-models_09.png)
在畫面中的下方出現一個警告,他們有多對多的關係,我們可以大膽地按下OK
![新的 [關聯性] 檢視](https://docs.microsoft.com/zh-tw/power-bi/transform-model/media/desktop-composite-models/composite-models_10.png)
所以他們的關係就正常了,可以自由地設計報表了
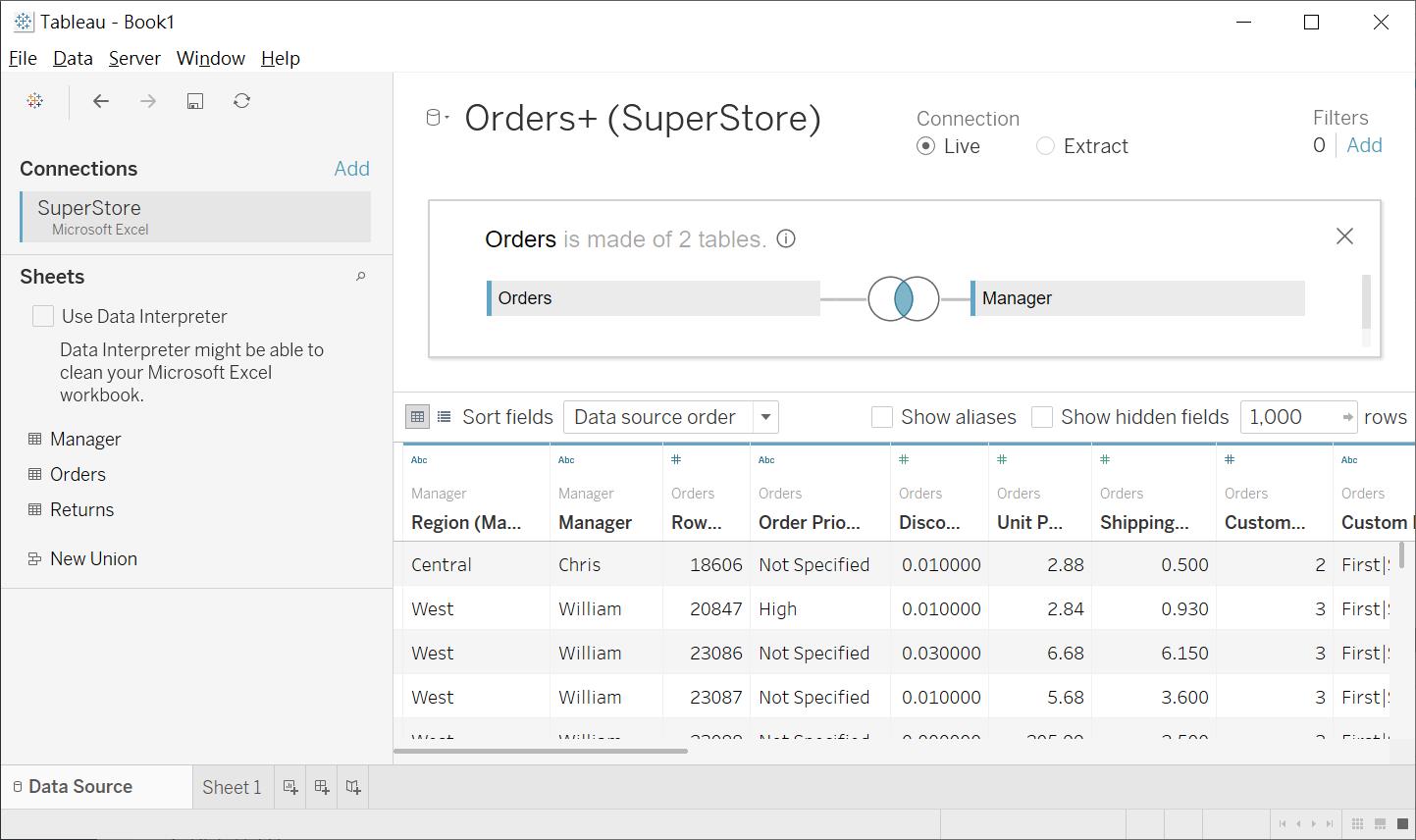
在 2020.2版本的Tableau中,提供了全新的 Relation ship的模式。為了怕混淆各位,我還是先介紹傳統的模式。所以我就不直接將另一個 Table直接拖進右上角,取而代之的是,對 Orders 這個 Table 進行 Double click
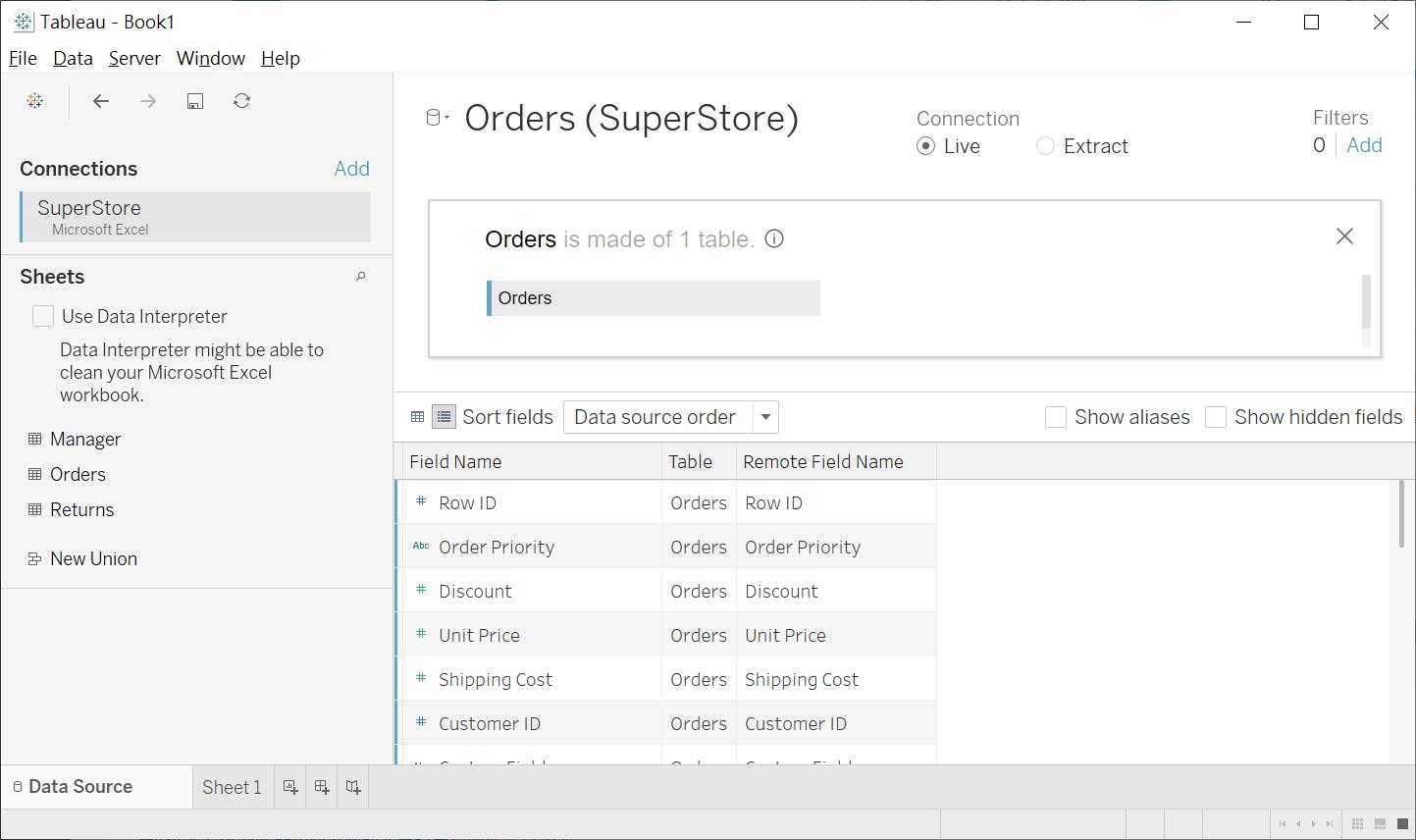 當它進入了傳統的關聯性編輯模式,我們就能將 Manager table 拖到右上角。它的情境是,使用者除了從 Orders中取得產品的銷售、毛利資訊之外,還想要知道,主管對於銷售方面的貢獻度。
當它進入了傳統的關聯性編輯模式,我們就能將 Manager table 拖到右上角。它的情境是,使用者除了從 Orders中取得產品的銷售、毛利資訊之外,還想要知道,主管對於銷售方面的貢獻度。
當二個以上的 Table在右上角中出現,預設會以 inner join的方式進行關聯,假設你有Left join的需求,是可以點擊藍色有交集圖示的地方,進入編輯界面。此時你就可以修改關聯方式與增減 mapping 的欄位,甚至是寫函式來關聯(例如,某一個 Table 儲存著E/W/S/N/C分別是東/西/南/北/中的縮寫字母,它和另一個存放完整字元的 Table就沒辦法順利的關聯,你會需要用 Left 函式來取得欄位中左邊的第一個字母)
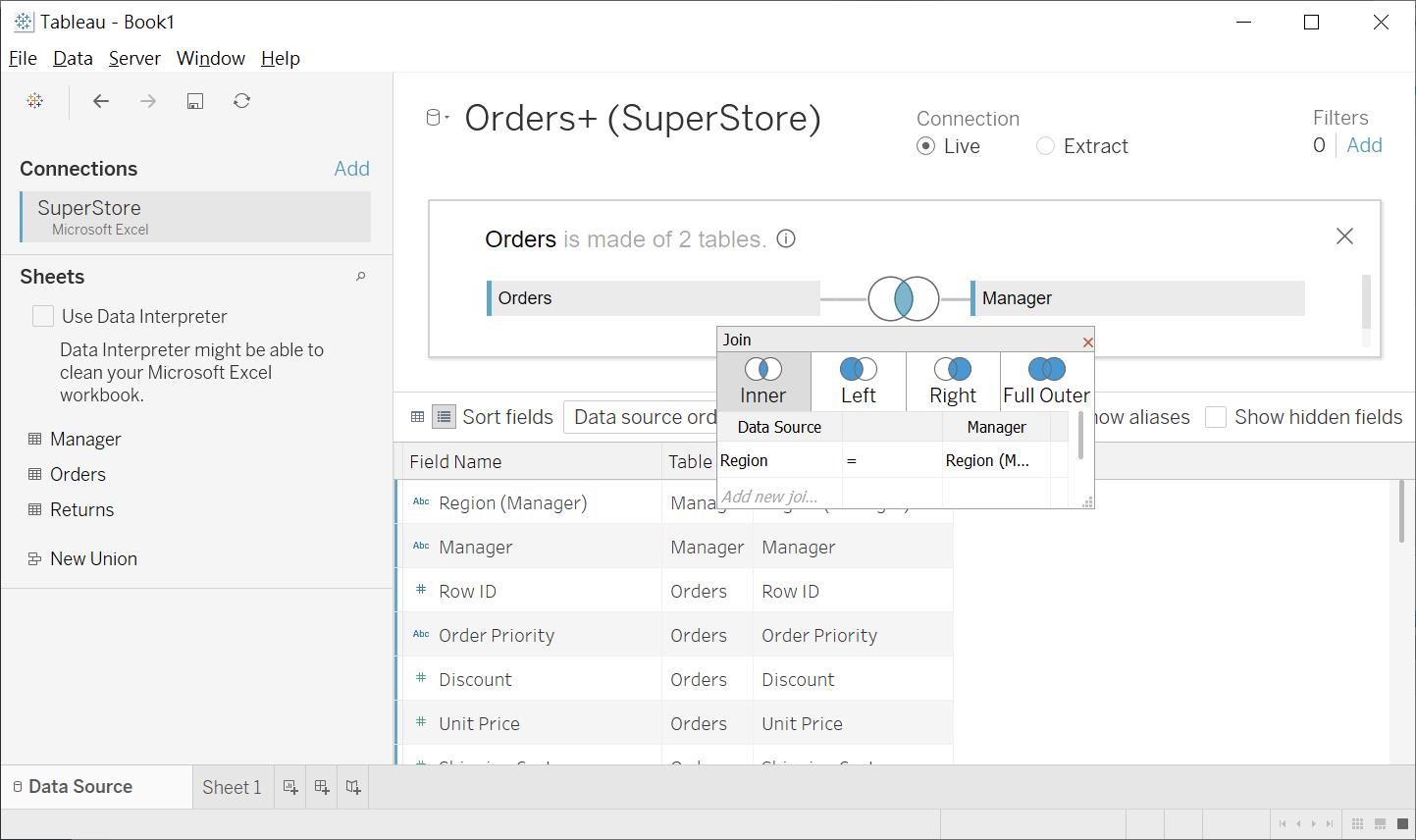 當我們調整完關聯,我們將右下角切換成資料預覽,來確認 Manager與 Region的欄位與數值有正確地呈現出來
當我們調整完關聯,我們將右下角切換成資料預覽,來確認 Manager與 Region的欄位與數值有正確地呈現出來
- 資料檢視:在開始設計報表之前,你可以先以資料面/關聯性的角度檢視材料(就像煮菜之前要先準備食材,做一些剝皮、切丁之類的前處理),所以你需要記住左邊有三個頁籤,是可以讓你隨時切換視角的
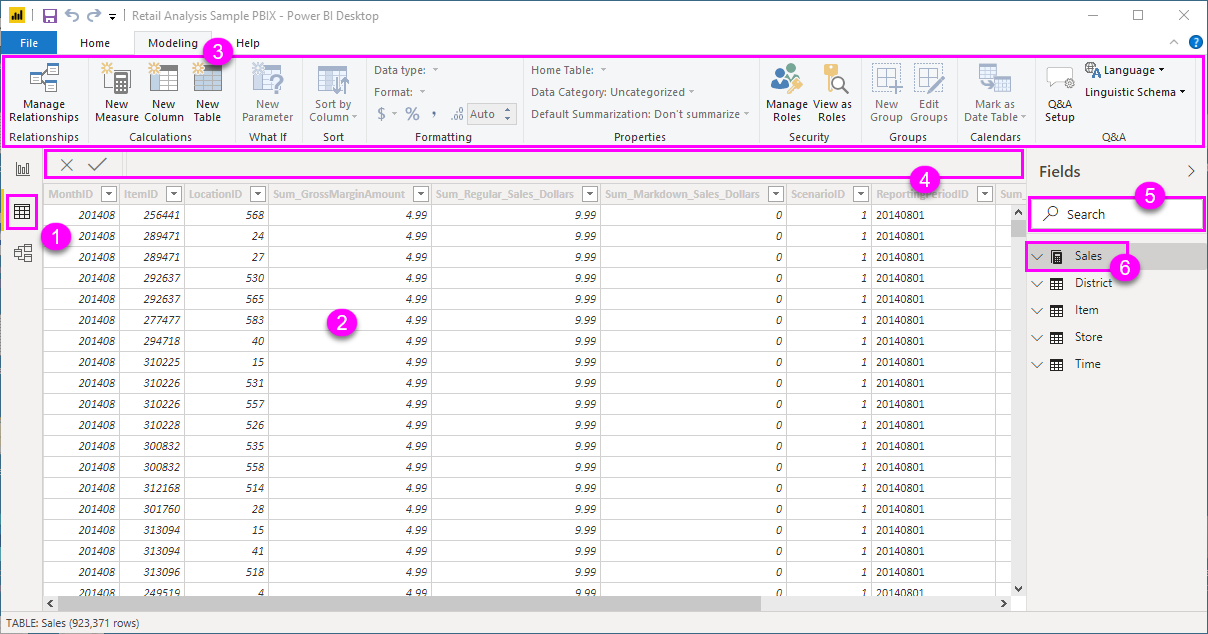
關聯性檢視
檢視食材後,再回到報表檢視,開始設計報表
![Power BI Desktop 的螢幕擷取畫面,其中顯示已選取的 [報表] 檢視。](https://docs.microsoft.com/zh-tw/power-bi/transform-model/media/desktop-query-overview/queryoverview_viewicons.png)
在 Tableau 則是以右下角的 Data source/ 工作區域(Worksheet/ Dashboard/ Story)來切換不同的檢視角度
- 資料更新(不包含排程規劃)頻率
以零售業為例,晚上十點關門的全聯,老闆要等到晚上十一點結帳後才能看到今天的最終營業額、庫存…等相關的資訊。但是問題來了,老闆只是報表的訂閱者,最新的數據,剛才有說過,是需要報表的Owner開機先按下更新Refresh按鈕,再按下發佈Publish按鈕。故,在下班時間讓人開機是有點強人所難,是否有更自動化的方法呢?有的,就是排程更新,Power BI pro 提供每張報表有8次的排程更新功能。所以下圖的設定畫面,你可以看到是在Power BI portal所進行的。
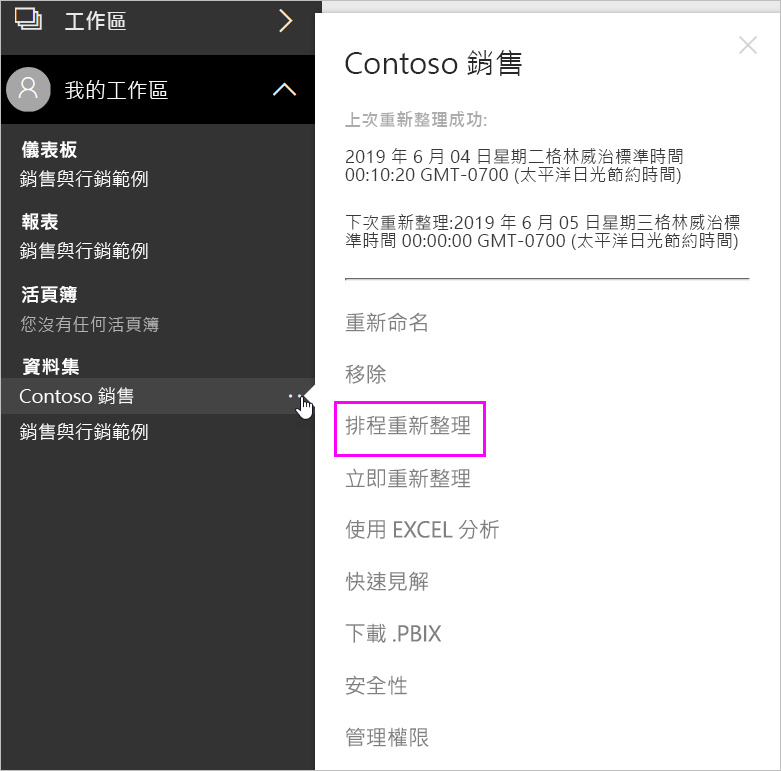
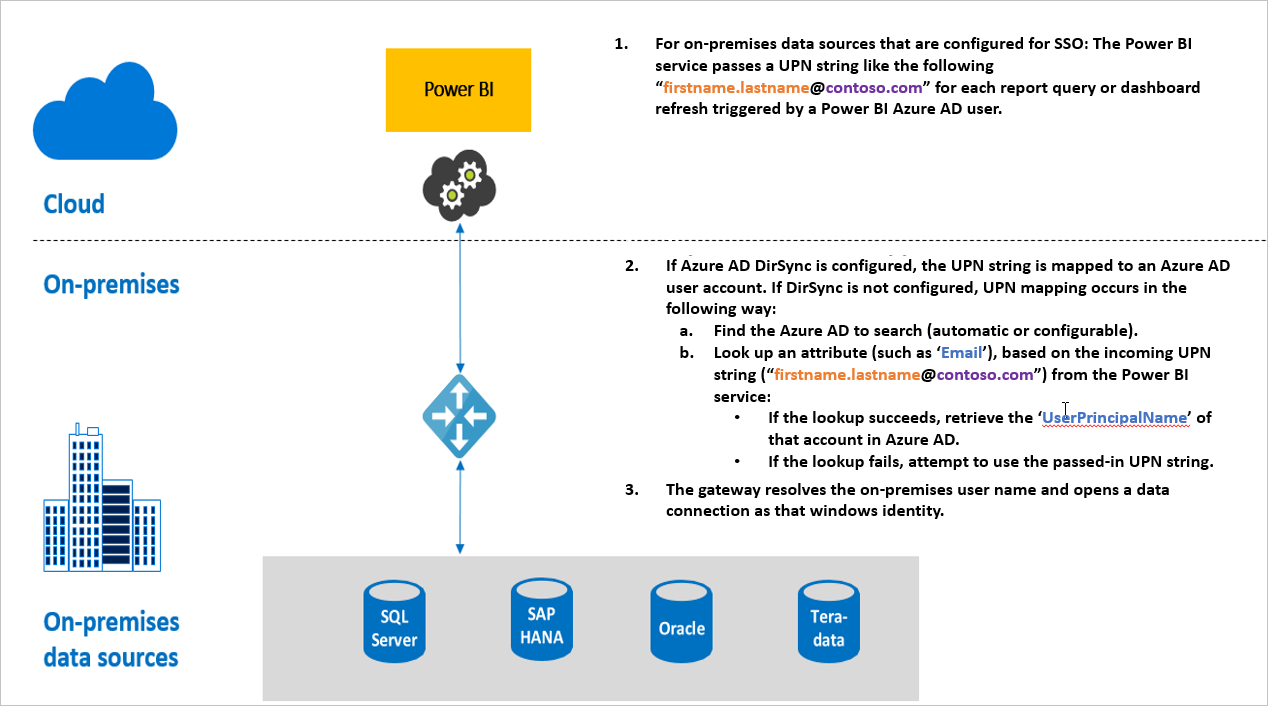
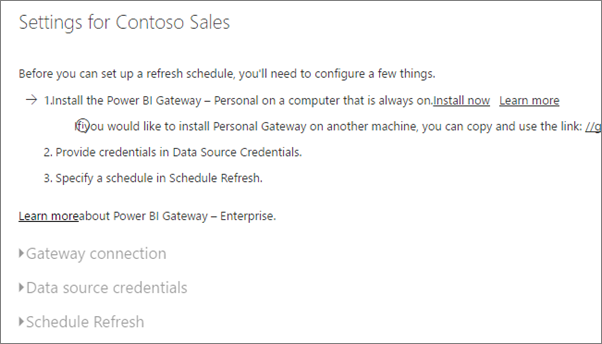
萬一我的資料是存在非雲端的儲存空間,排程更新要如何運作呢?答案是 Data gateway,所以你需要先去官網下載並且安裝。這裡有一個 Personal/ Enterprise/ 內部部署(IT用)三岔路,他們的運作原理是一樣的,是將單人/多人的 Credential 帳密(例如它對 SharePoint 可以支援匿名、基本、Windows…等驗證機制)甚至是SSO儲存在 gateway中,由它代替你去公司的資料庫(Oracle/ MS SQL/ HANA…)、NAS、SharePoint、One drive...等共享空間把資料取回,以利資料的更新(不包含報表的重新發佈)。
當帳密正確時

如果你是由IT幫你設定的內部部署 gateway畫面會如下圖

下圖是連線成功的畫面

當你完成 gateway的佈署,接下來要再回到 Power BI portal繼續設定,排程的畫面如下,你先下拉週期,例如每天,然後繼續按照你的需求來設定時間,如果一個時間不夠,可以再按下「新增其他時間」,剛才講過,最多是八個。至於二個排程間的 Interval目前最短僅提供15分鐘。若你覺得不夠短,可以考量採用 DirectQuery或是 Streaming的方式(請參考之前的文章)
![[排定的重新整理] 對話方塊](https://docs.microsoft.com/zh-tw/power-bi/connect-data/media/refresh-scheduled-refresh/scheduled-refresh.png)
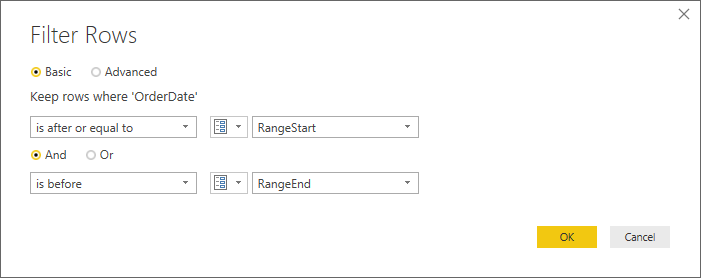
另外,若是你的資料量很大,可以採用才剛下放到 Power BI pro(之前只提供給 Premium)的 Incremental refresh功能,再搭配 RangeStart & RangeEnd 參數來更新較小範圍的資料。例如公司已經累計了十年的歷史資料,但主管僅關心最近七天的數據。官網的資訊很清楚,需要的人可以自行參考
同理在 Tableau有一個 Bridge 的產品,可以完成相同的動作,細節可以參考官網的說明
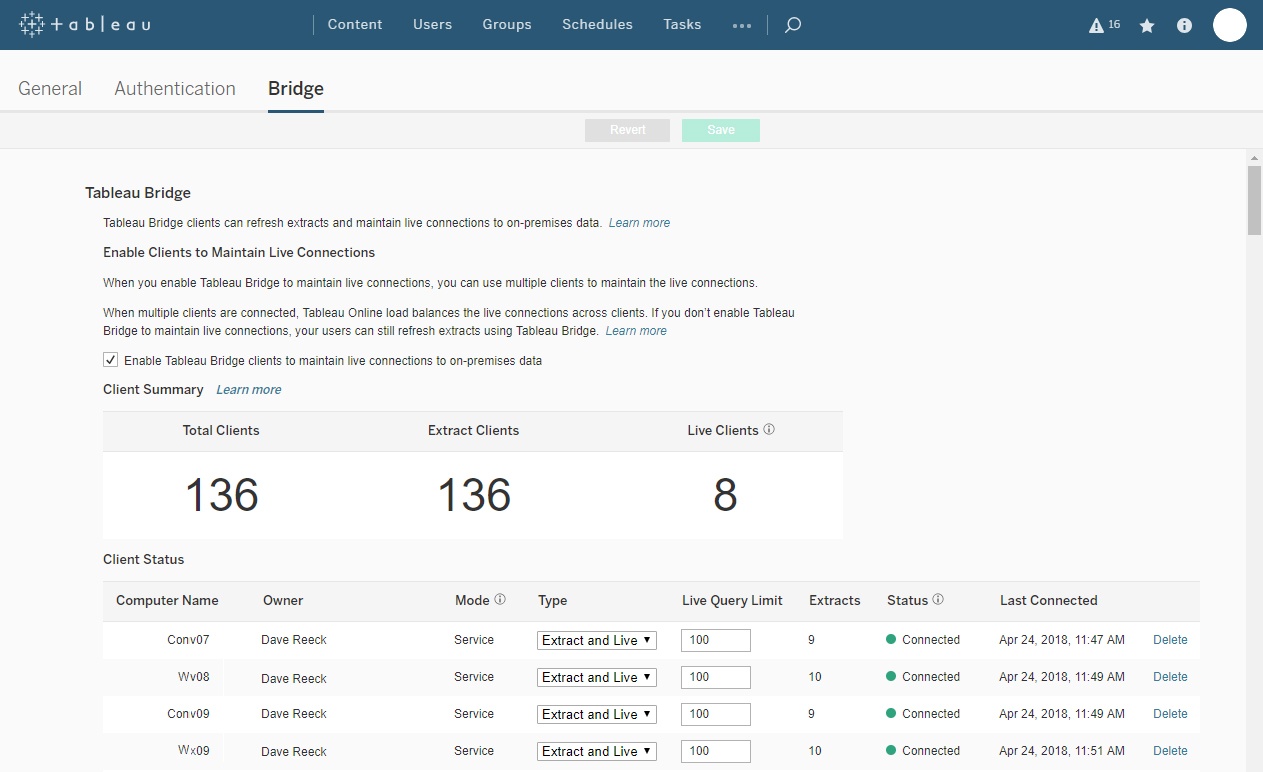
- 其他
我簡單比較一下這二大陣營在 Connect to data source 設計理念的不同,首先 Power BI 是集中管理的概念,從左邊三個頁籤中的 Model 頁籤開始編輯 Schema,它有支援混合模式,例如你有一個 SQL Server中的 A Table 連到 Excel的 B sheet (假設他們是有 Key 值關聯的),並且自由決定 A Table 要用 DirectQuery B sheet 要用 Import,如下圖,在 Desktop 開發完報表後,預設會將報表的資料源 as a data source 發佈上去,如果你想增加 C Table 至既有的關聯上,就是下載這份含有資料集的報表,進行編輯。或是下載資料集,把C Table加進去,然後從頭拉一張報表。
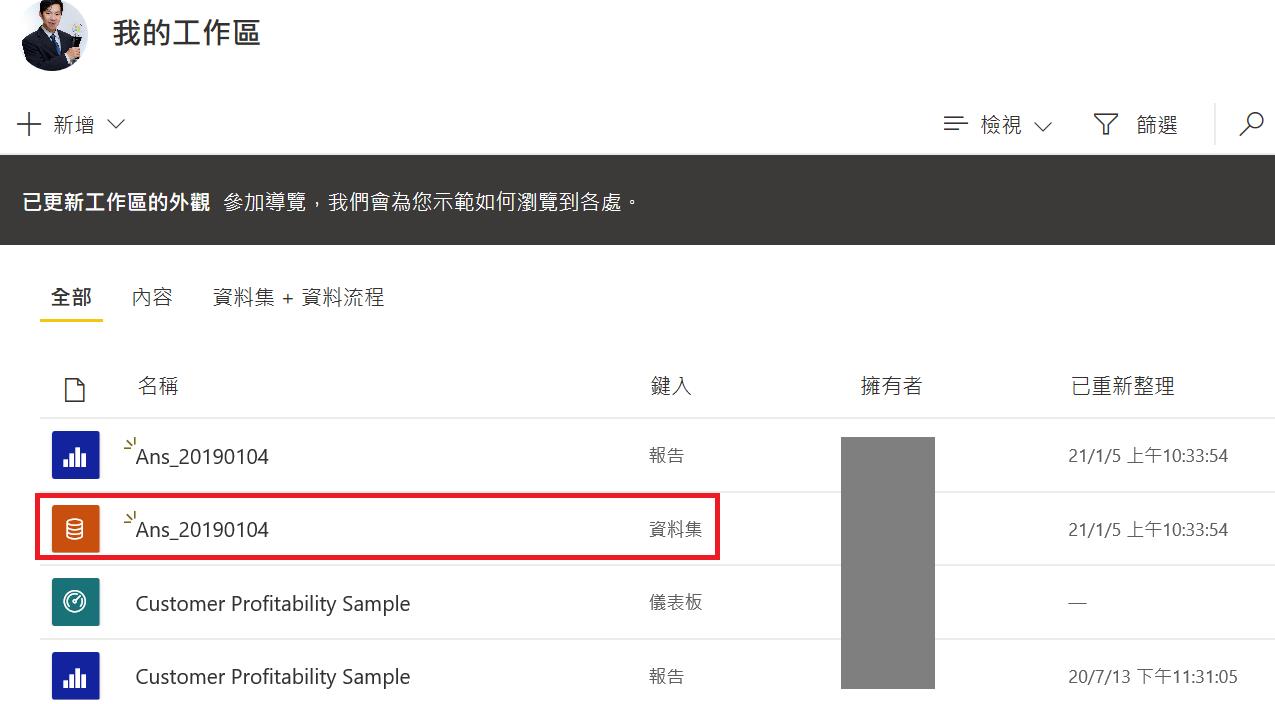
在 Tableau 中,則是將 Data source 視為一組連線(在每個連線可以將 SQL Server的 A Table 連到 Excel的 B Sheet,此時並不支援混合模式),並且分散在各個 Sheet 中。
以資料集來看,當它發佈至伺服器時,會將整個 Workbook中不重覆的 data source 全部都進行上傳。
以資料面來看,不同的 data source是可以進行 Data blending,例如把二邊的產品銷量做加總。
以儀表板來看,它可以支援畫面上不同的物件(Worksheet, Dashboard)是用不同的連線模式(Live, Extract) 混合模式。
另外,Extract 時是可以指定 Single table 或是 Multiple table。當資料不大時,前者可以提供資料篩選(包含了:前N筆、指定欄位、抽樣N筆…)、累加式更新…等較靈活的設定;後者則是在不提供資料篩選的條件下,運用其演算法讓分散式的儲存能夠佔最小的硬碟空間。如果想要篩選可以參考官網,了解在不同階段的 Filter 效果
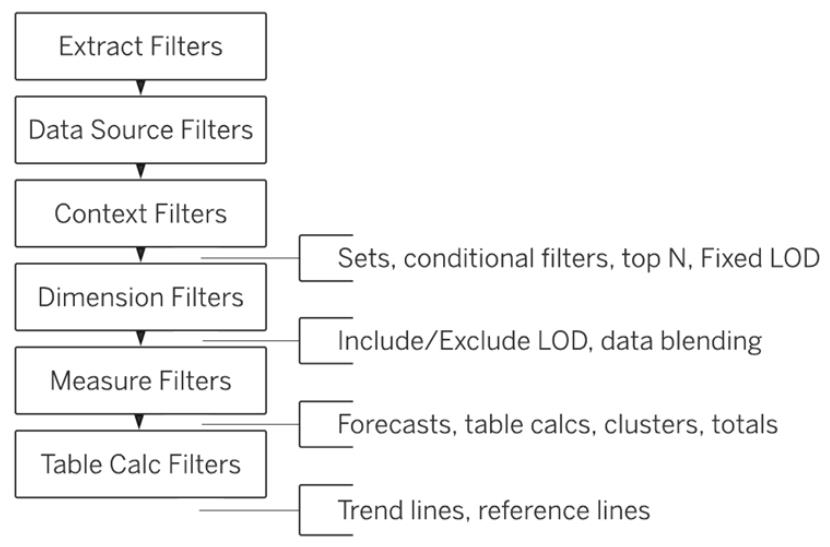
結論:新一代的 BI 工具,預先幫我們掃平各種科技壁壘,再加上大數據時代與政府開放的利基,每一個人都可以透過學習 Power BI與 Tableau 先進的報表視覺化工具,實現用數據說故事的全新里程碑…
李秉錡 Christian Lee
Once worked at Microsoft Taiwan