語音合成是語音辨識與回應中很重要的環節之一,在完整環節中語音辨識的三劍客ASR,TTS,NLP 分別可以類比為人類的耳朵、嘴巴、左腦。今天要介紹的Custom Voice雖然不是什麼新產品,但是隨著機器學習(深度學習)的成熟,竟然可以讓老瓶裝上新酒後,散發出迷人的香氣,吸引更多的文人藝士來品嚐!
上次跟大家介紹厲害的Custom Vision(可以參考這一篇),這次要介紹微軟的另一個好東西Custom Voice
話說在十年前,語音辨識與回應當紅的台灣,曾經有許多企業,想要把林志玲的聲音應用在各行各業的IVR電話自動應答系統上,讓自己企業的門面更加吸引人。甚至也有廠商想要用ASR加上林志玲聲音的TTS來建置語音聊天平台,取代0204龐大且潛在的市場商機,可惜因為需要錄音幾百句至少需要二個小時而作罷。同理1999市民熱線,時任市長郝龍斌也不得不放棄這個宣揚施政績效的好機會…
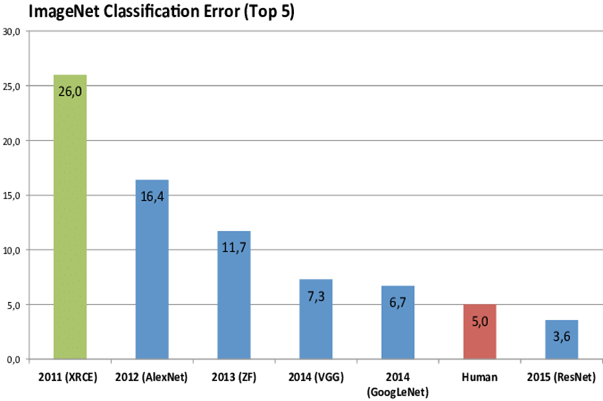
微軟2015年在 ImageNet 運用較好的深度學習方法在機器視覺項目上贏得到冠軍,接下來主辦單位在2017因為電腦已經打敗人類,所以從此停辦這個比賽,但是卻將人工智慧推進到更上一層樓的里程埤。時至今日,微軟又繼續應用深度學習加上 Sequence to Sequence 技術,實現出 end to end的語音辨識(ASR)與語音合成(TTS)。細節可以參考2019的這支影片。
各位可能不知道要從機械音的 TTS跨越到像真人的自然音這條路有多難走?細節可以參考李開復在2009出版的「世界因你不同」,他參加軍方舉辦的語音辨識比賽,成功應用HMM語音模型加上統計模型打敗統治多年的 Rule based,一炮而紅。隔沒多久,業界開始注意到這篇論文,除了順利地讓他進入了微軟、Apple、Google三巨頭擔任要職。Apple手機也是因為數位助理Siri功能採用了相同的技術,大賣特賣並且奠定了智慧手機的王者地位。
各位可能不知道要從機械音的 TTS跨越到像真人的自然音這條路有多難走?細節可以參考李開復在2009出版的世界因你不同,他參加軍方舉辦的語音辨識比賽,成功應用 HMM 語音模型加上統計模型打敗統治多年的 Rule based,一炮而紅。隔沒多久,業界開始注意到這篇論文,除了順利地讓他進入了微軟、Apple、Google三巨頭擔任要職。Apple手機也是因為數位助理Siri功能採用了相同的技術,大賣特賣並且奠定了智慧手機的王者地位。
但是統計模型先天上,因為在 Search engine 階段,需要展開近二萬的 phoneme (母音子音),所以僅能單次處理1~2語言,不然就是採用一邊成長一邊砍掉的策略來抑制資源不斷地的成長。一直到 RNN與LSTM深度學習應用到語音辨識與語音合成,聰明地讓電腦可以應用長短期記憶學到的留下好的權重,並且有遺忘機制可以淘汰不好的權重,取代了要把近二萬個項目展開的很耗費資源的舊方法。在大量GPU的條件下,成功地實現輸入英文,可以翻譯並合成中文、日文…等多國語言的新境界。
接著在世界圍棋大賽打敗人類棋王的 DeepMind,在2016年再接再勵推出了 WaveNet,它是應用了 Dilated Causal Convolution (擴展因果卷積) 的架構做特徵提取,與 Encoder Attention Decoder (Tacotron2)的架構做聲學模型,讓現在的 Google小姐有著更自然的語音合成效果。
雖然有不同學派的語音合成在發展著,但大致上它的流程不外乎就是,輸入(特徵抽取):收集聲音,透過斷詞、斷句、韻律分析、傅立葉轉換(Fourier transform)…等處理,來取得所需的音素序列 => 處理(模型運算):以聯合聲學特徵為基底,包含一般的頻譜(Spectrum)、基因頻率(F0),還有梅爾頻率倒譜系數(Mel-Cepstral Coefficients)、BAPs(Band aperiodicities)、一/二階差分(Delta)、清音(Unvoiced/Voiced flag)…等,再應用模型來學會上下文 => 輸出(Vocoder 合成):將語音特徵合成為語音波形(Wave)來輸出。下面我也幫大家整理了三大學派的比較給各位:
**更多的細節可以搜尋 VCC2020 這類的比賽,做延伸的閱讀
- 波形拼接式合成 Concatenative speech synthesis:應用預錄好的語句,把所有發音所對應的波形來建立一個資料庫。使用時直接對號入座,效果難以優化為流暢的自然語音…
- 統計參數式合成 Statistical parametric speech synthesis:應用時長模型(文本特徵) + 聲學模型(語音特徵)。包含了類似決策樹原理的 HMM 或是 BSLTM 這類的 RNN,最後再將梅爾頻率倒譜系數(Mel-Cepstral Coefficients) 的結果輸出為語音波形
- 端到端合成 Neural network based end-to-end speech synthesis:放棄了以往採用複雜語言學的聲學模型,改為降維/升維的學習,並加入 Attention 與 Residual 來突破 RNN不能平行運算的限制。將梅爾頻率倒譜系數(Mel-Cepstral Coefficients) 的結果以自回歸(例如 WaveRNN、WaveNet)或是非自回歸(例如 MelGAN、WaveGlow)的方式輸出為語音波形
科普之後,我們再將鏡頭帶回到 Azure portal上:
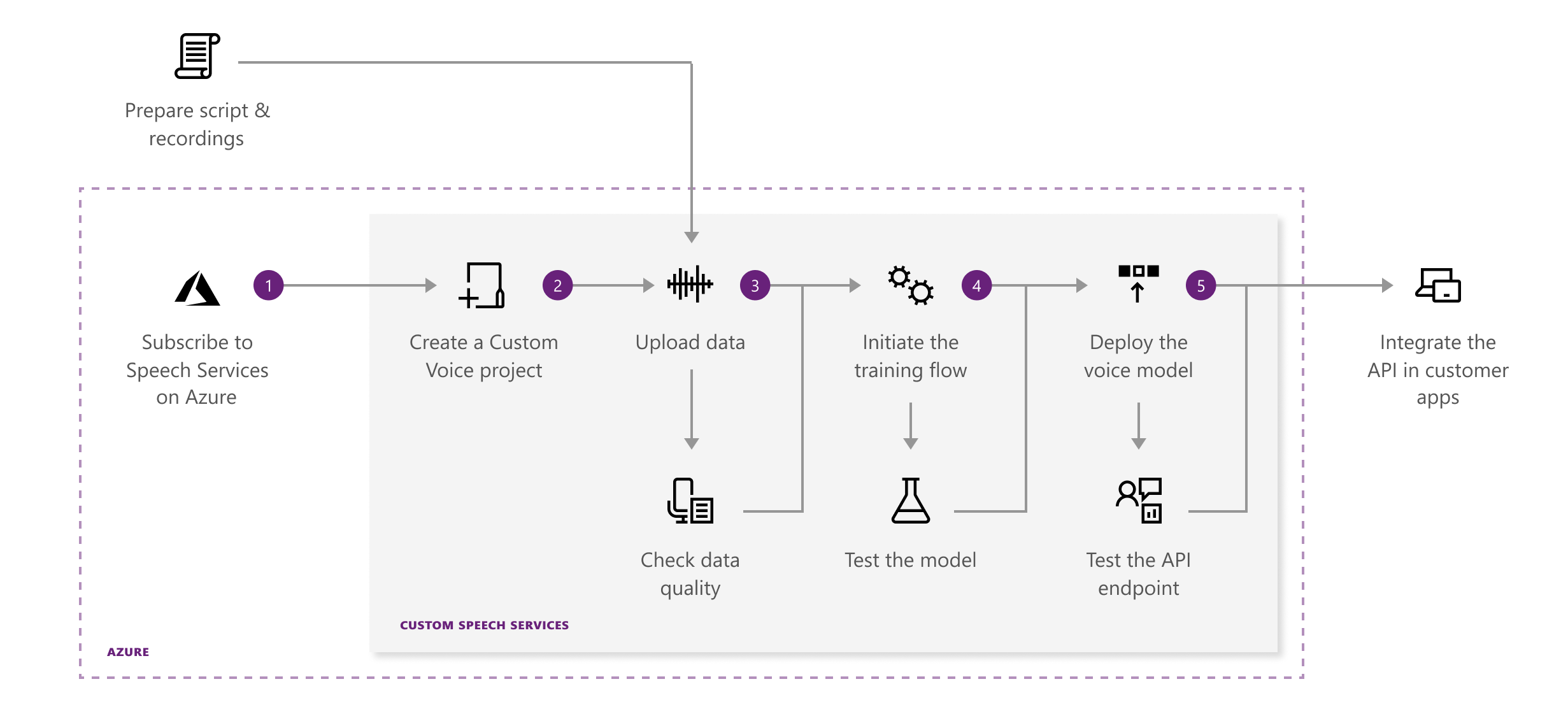
- 下圖是Custom Voice的整個流程,以下就跟我來實作一遍個人化的客製化TTS
若你還沒有用過 Azure,右邊的超連結可以協助你評估並試用 Speech Service服務
透過 Scroll bar 下滑選到語音服務,並按下取得API金鑰
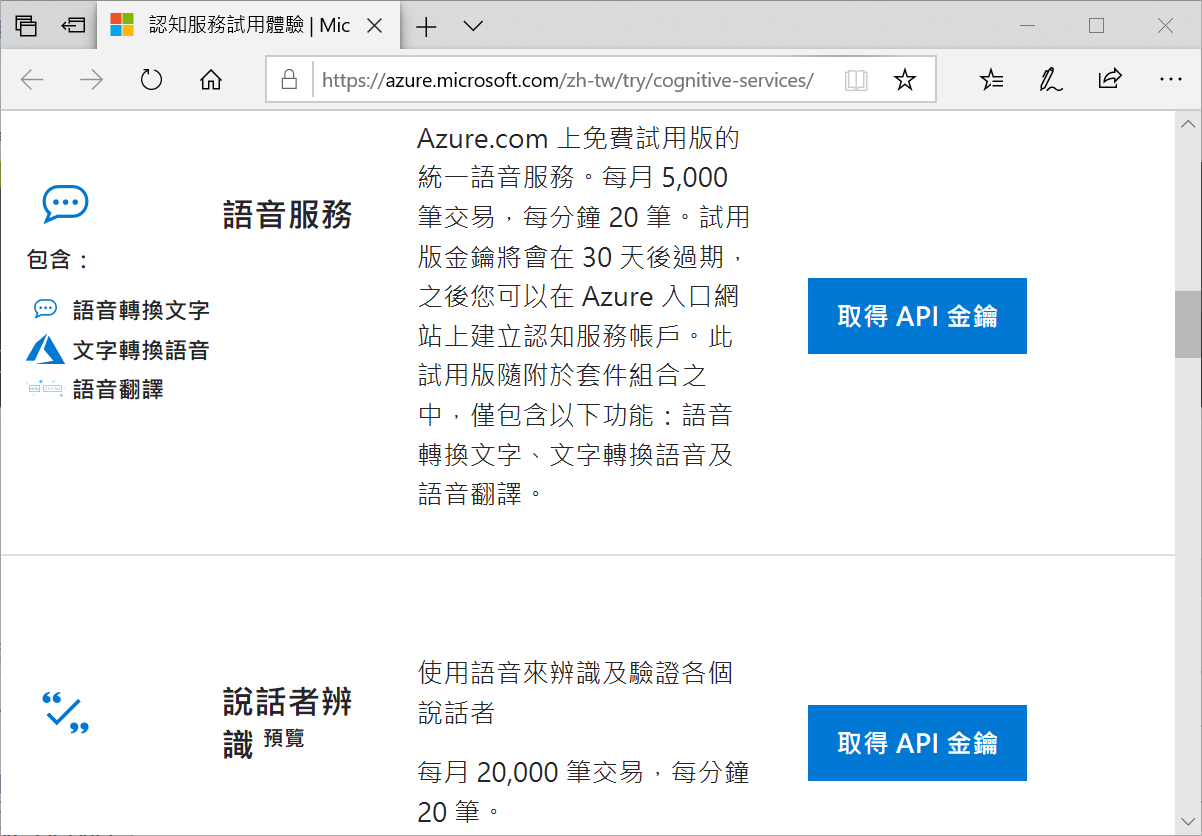
當你參考你費用的說明,按照你的條件,選擇適合你的情境開始使用
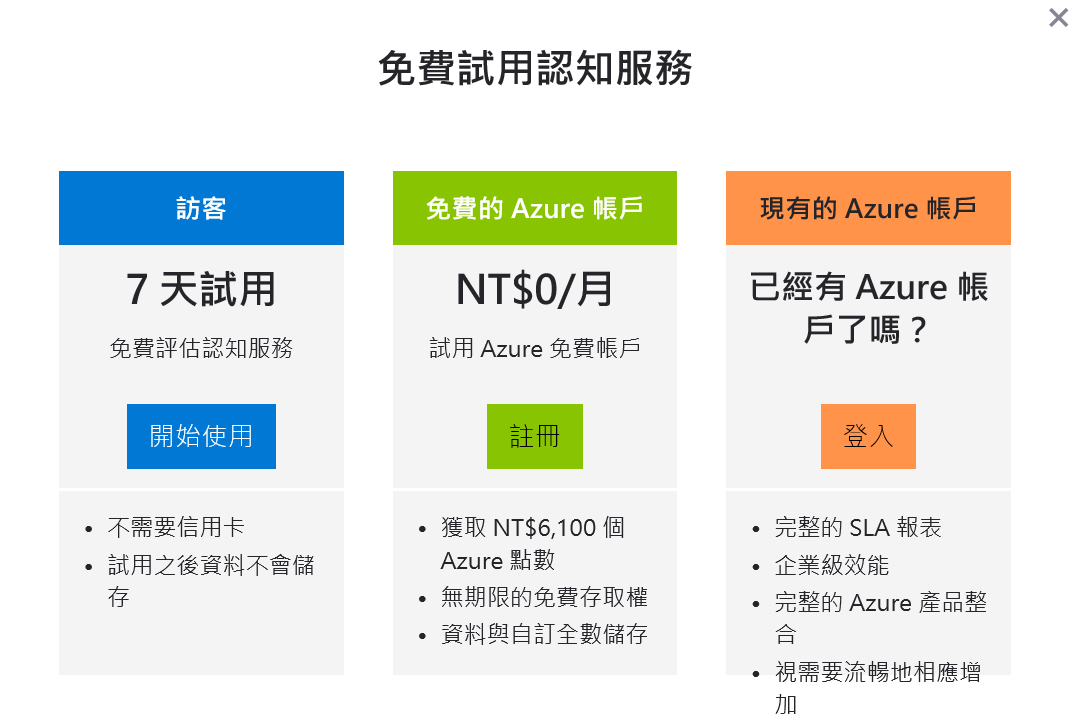
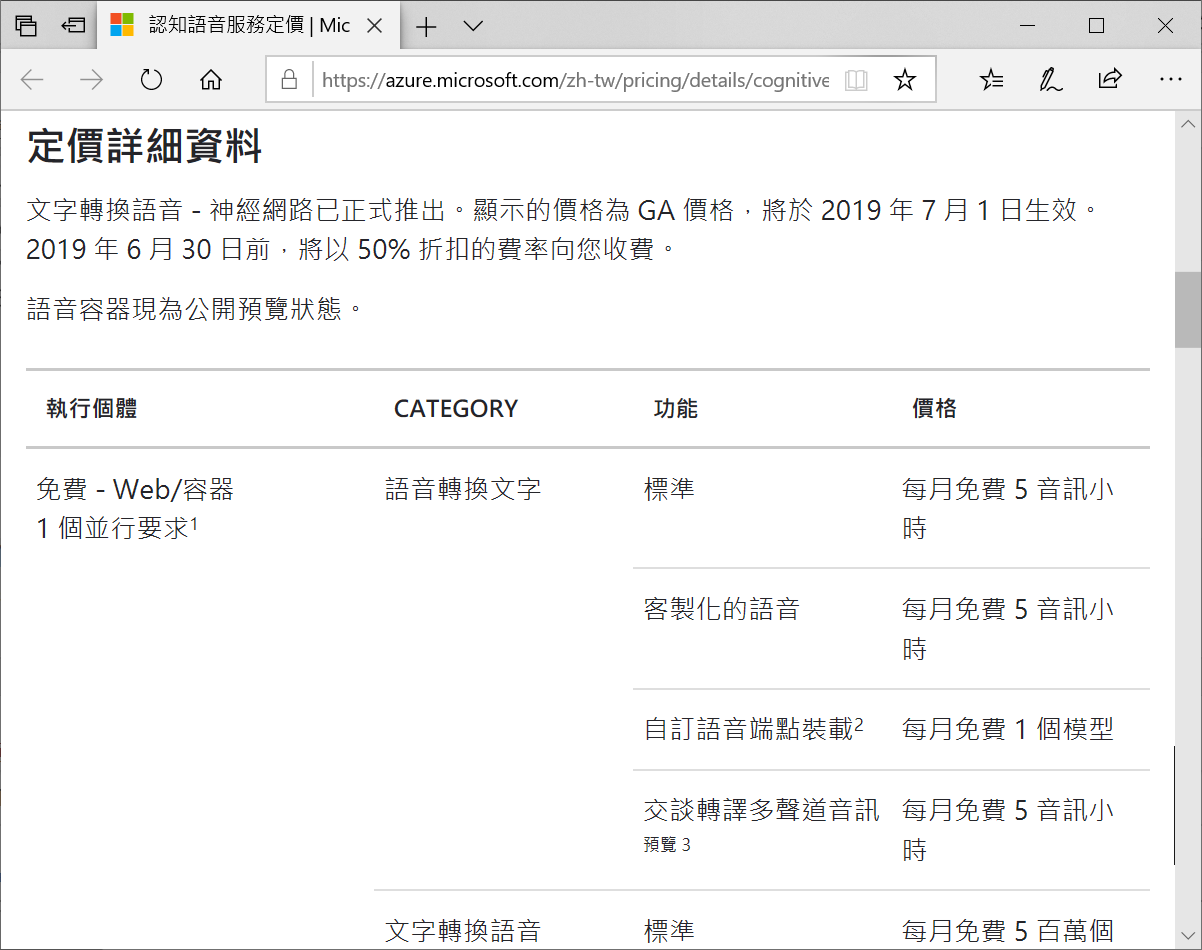
若你需要更明細的價格資訊,可以參考這個定價說明超連結。我是選東南亞(新加坡)資料中心/新台幣
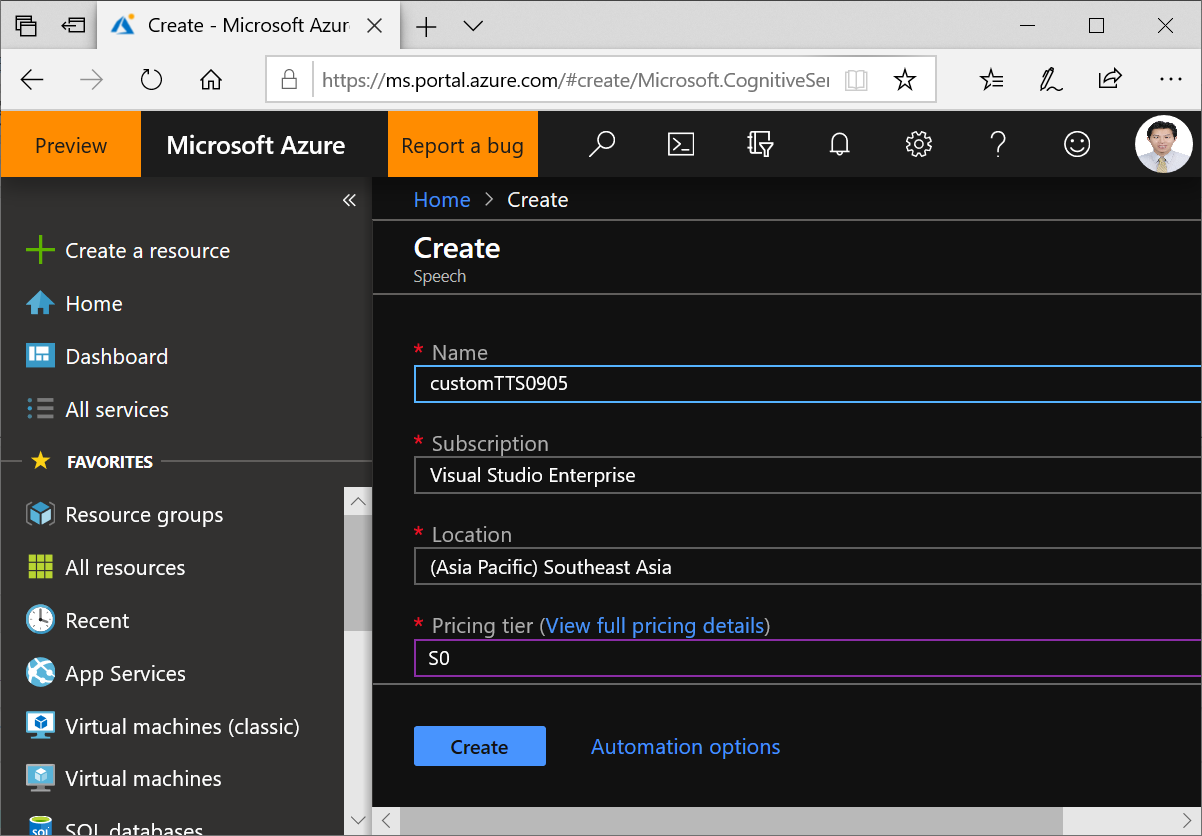
接下來你需要在Azure portal中填入專案(系統)名稱、使用訂閱(下拉)、資料中心地區(下拉)、價格(下拉),然後按下Create
等待約30秒
先切換到Speech Server網站 https://speech.microsoft.com/ 在右上角找到 Sign-in登入
登入後,就能看到剛才建立的服務
點選專案,然後再按Go to projects
用Scroll bar找到 Text-to-Speech中的 Custom Voice按下去
按下 New project
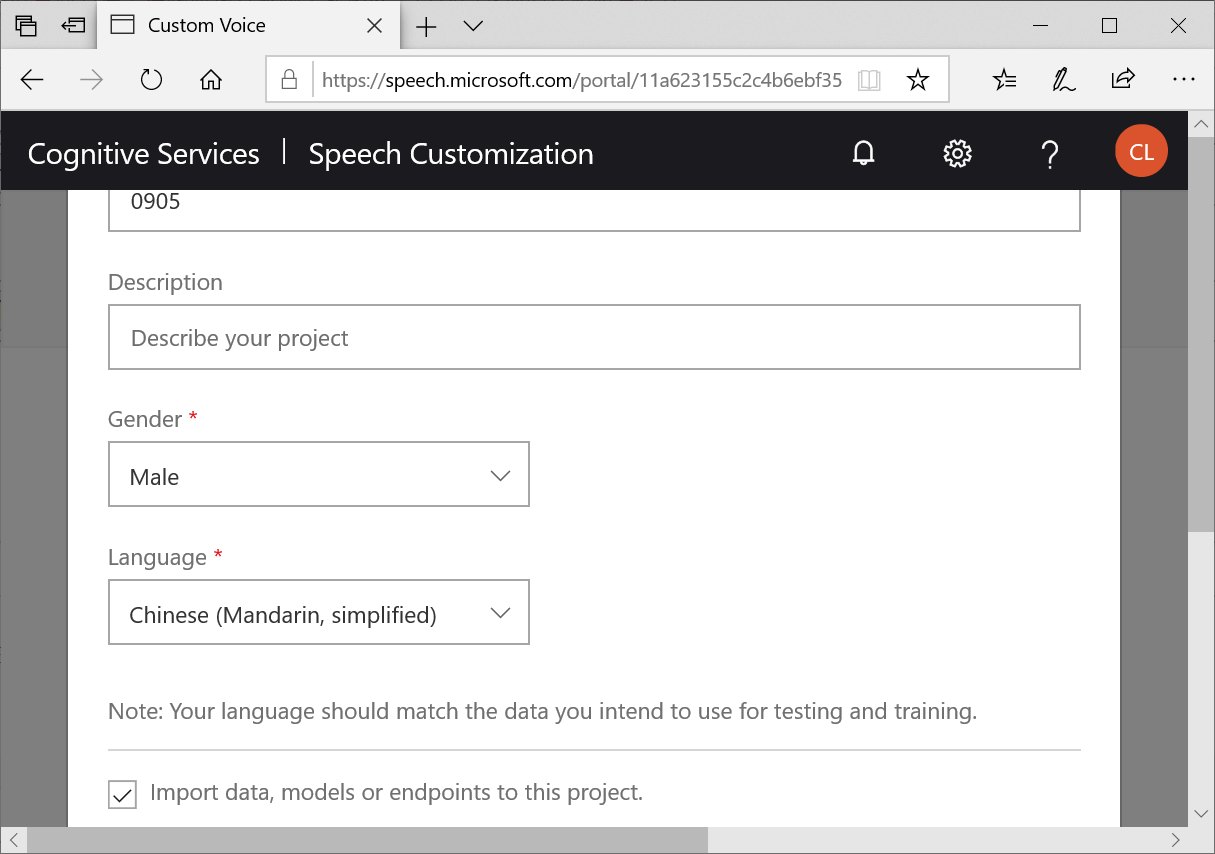
填入專案名稱、選擇性別、選擇語言(目前僅有簡體中文)
點擊新建好的專案
由 Data 頁籤進入,準備上傳音檔
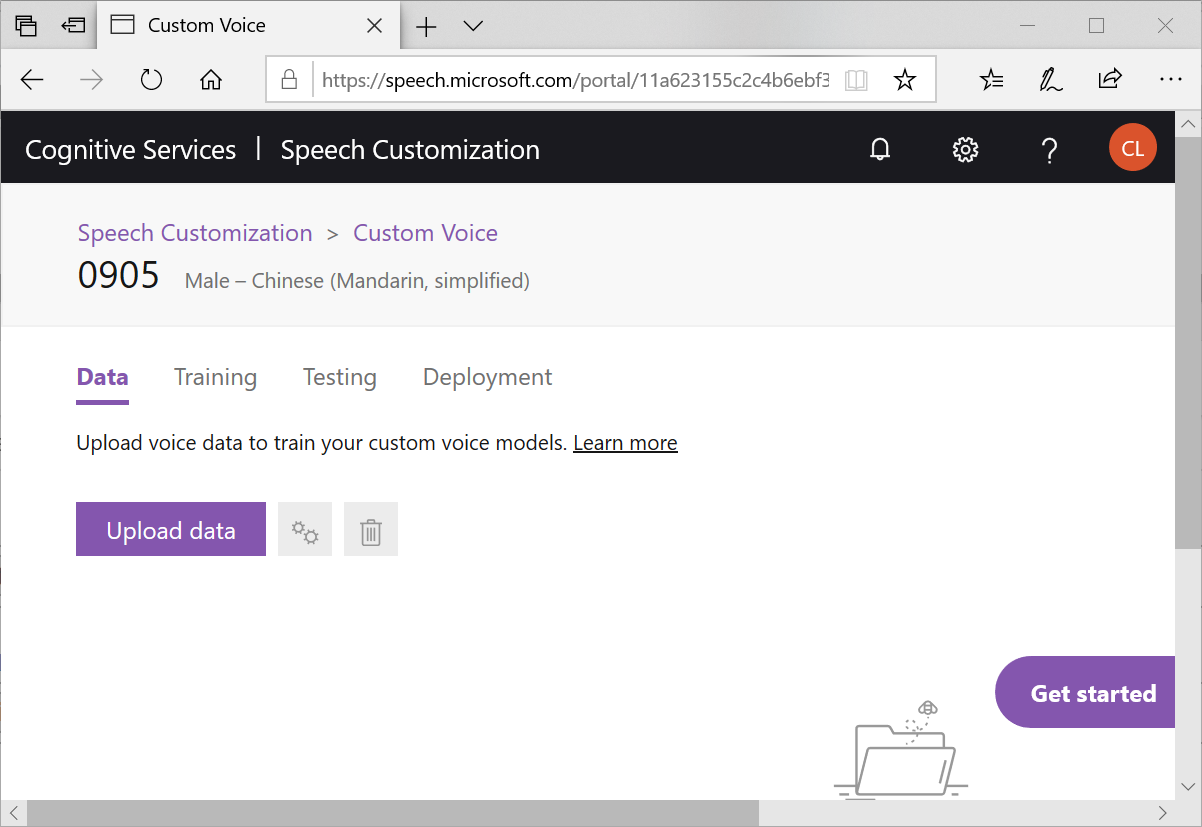
畫面中有說明,你需要準備,音檔與字稿。當你準備好就可以按下Upload
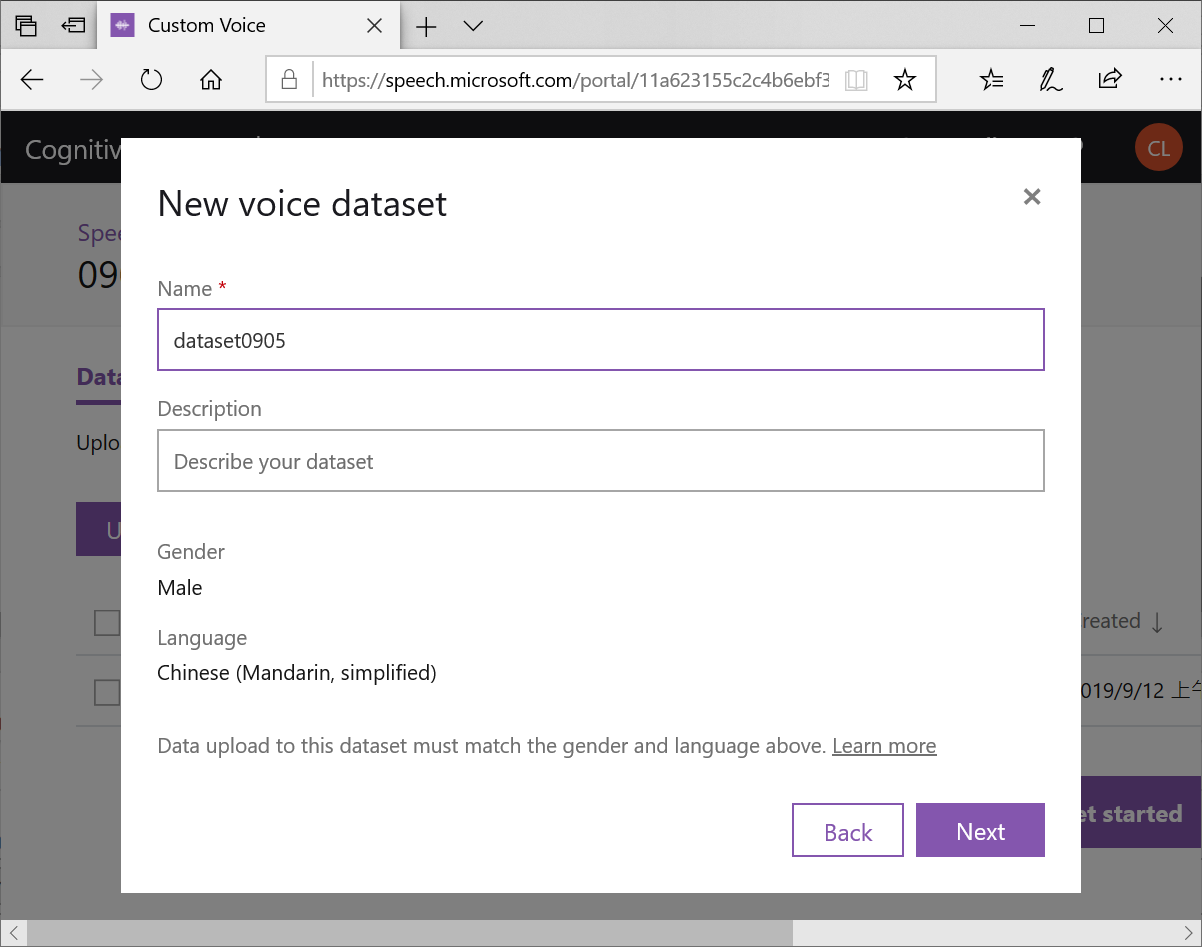
按下Next,替資料集取一個名字
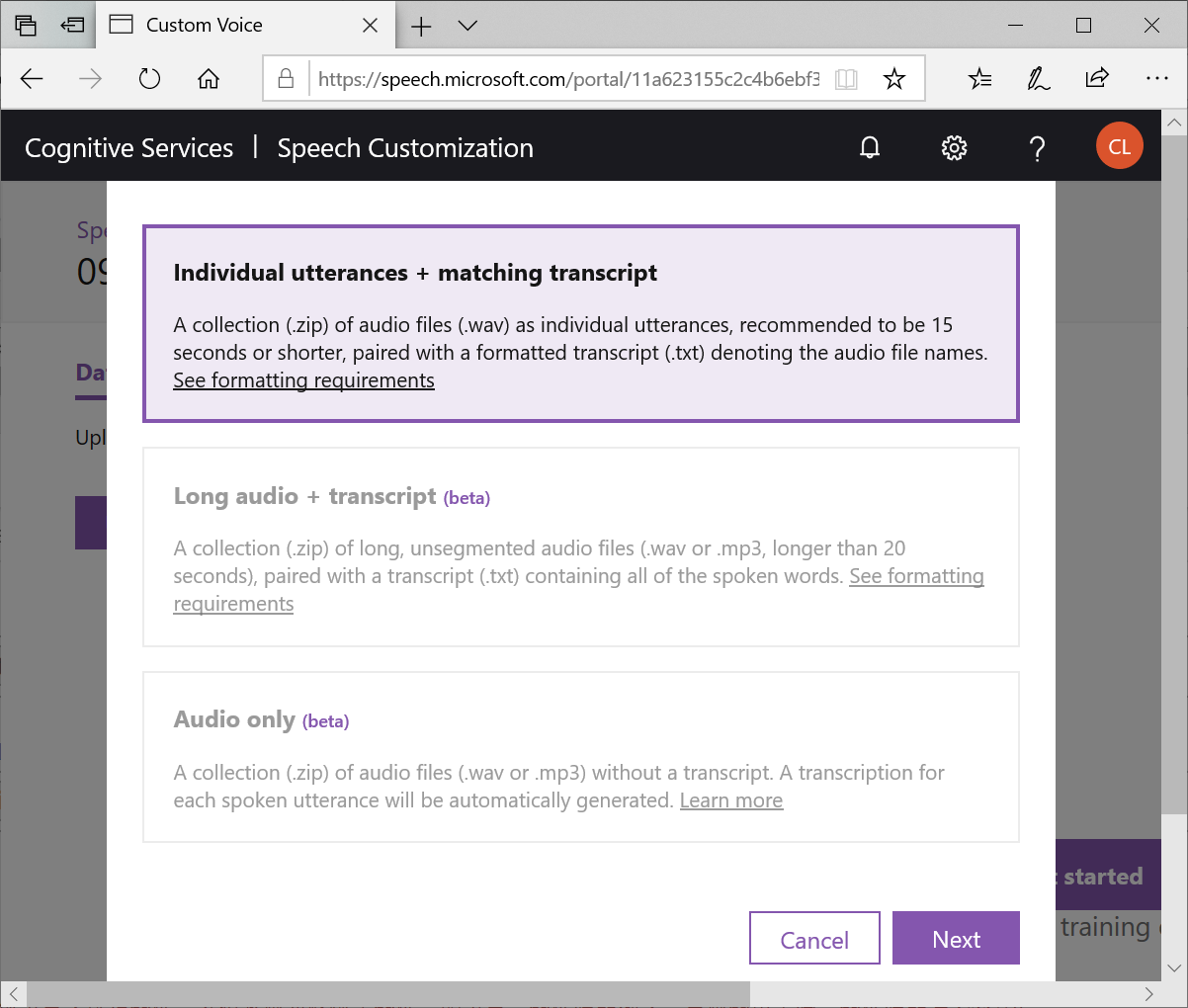
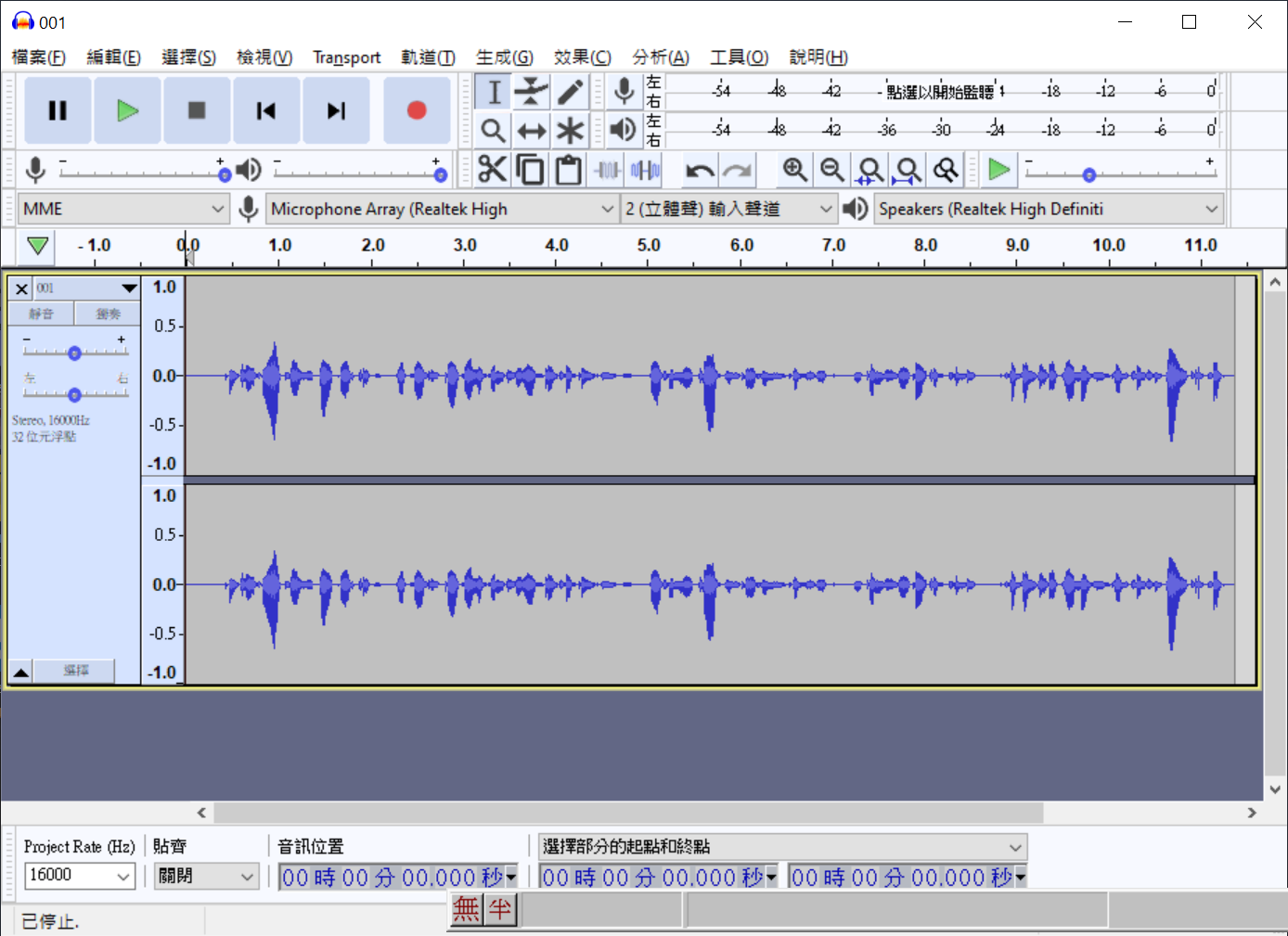
請按照說明中的格式準備檔案,細節請參考官網的說明。所以我按照了官網的建議下載了免費的錄音編輯工具Audacity,依序001.WAV~022.WAV錄製了一段新聞稿的內容,並且將其儲存為15秒之內的16K取樣率、16PCM、WAV格式的音檔,最後你還需要把他們壓縮成一個*.zip
接下來是文字稿,請注意目前只支援簡體中文,需要用Word的翻譯功能,把繁體變成簡體再貼回Notepad中
然後就可以回到Voice portal中
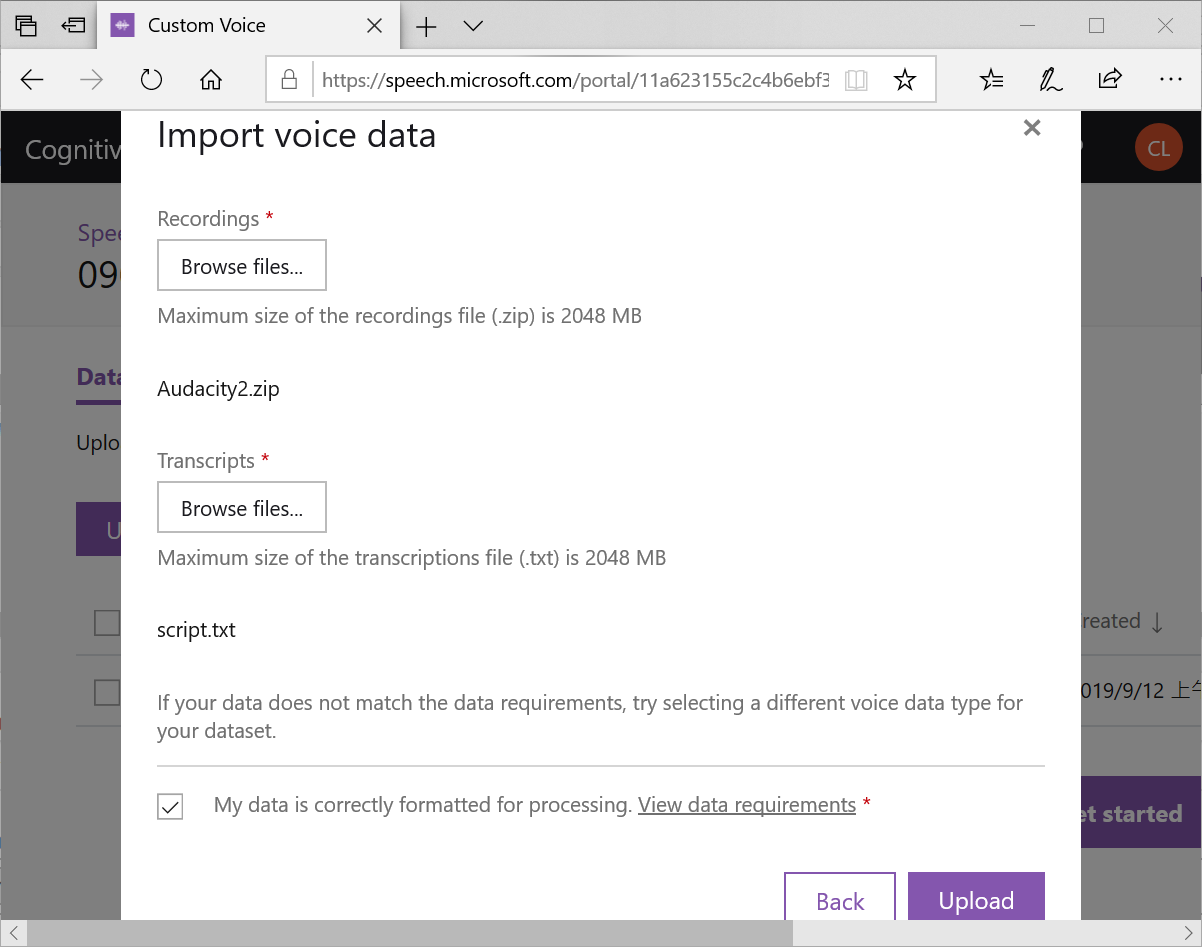
選取本機中的音檔(需事先壓縮為*.zip)與文字稿(*.txt),並且打勾,就可以按下Upload 開始上傳
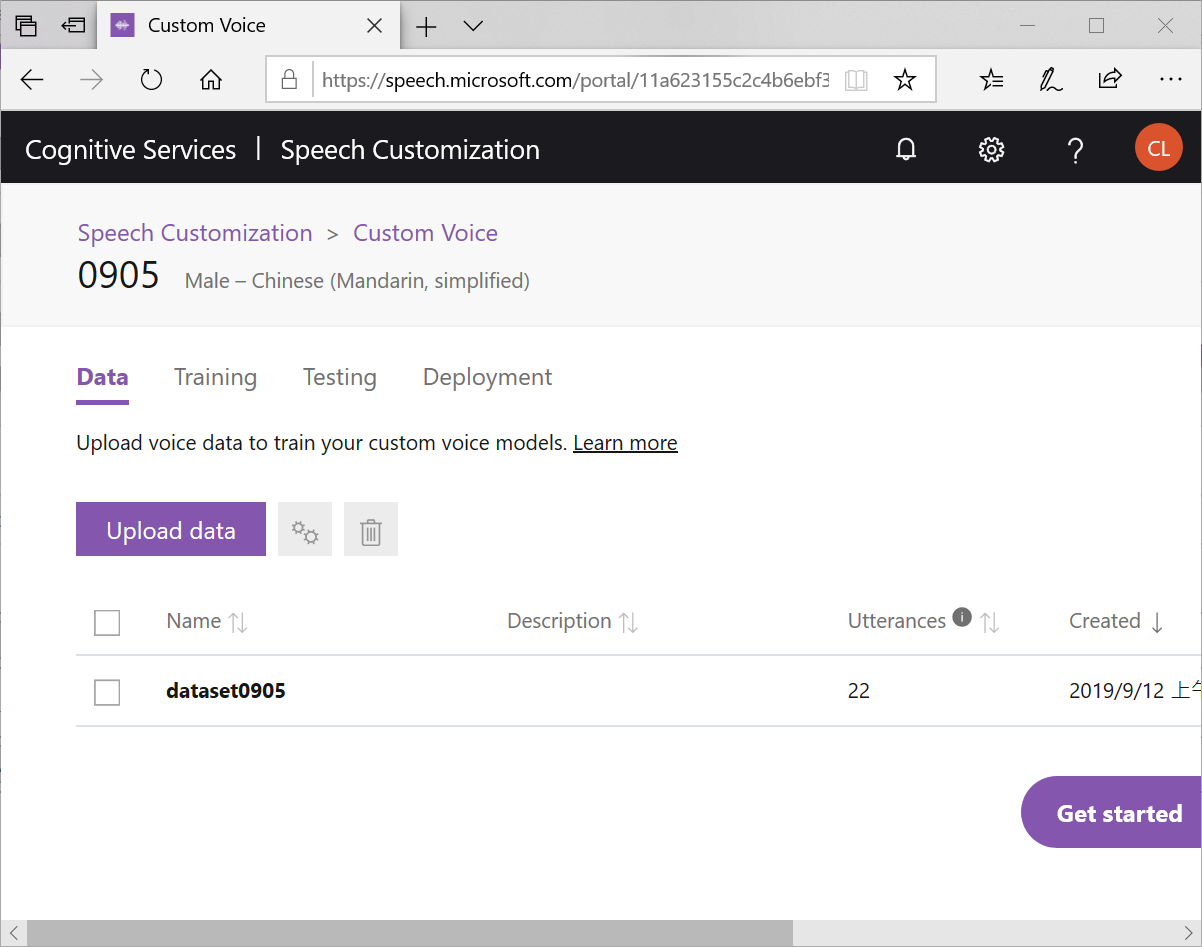
注意,需要等到Status由 Processing 變成 Succeeded後才能開始 training model喔!
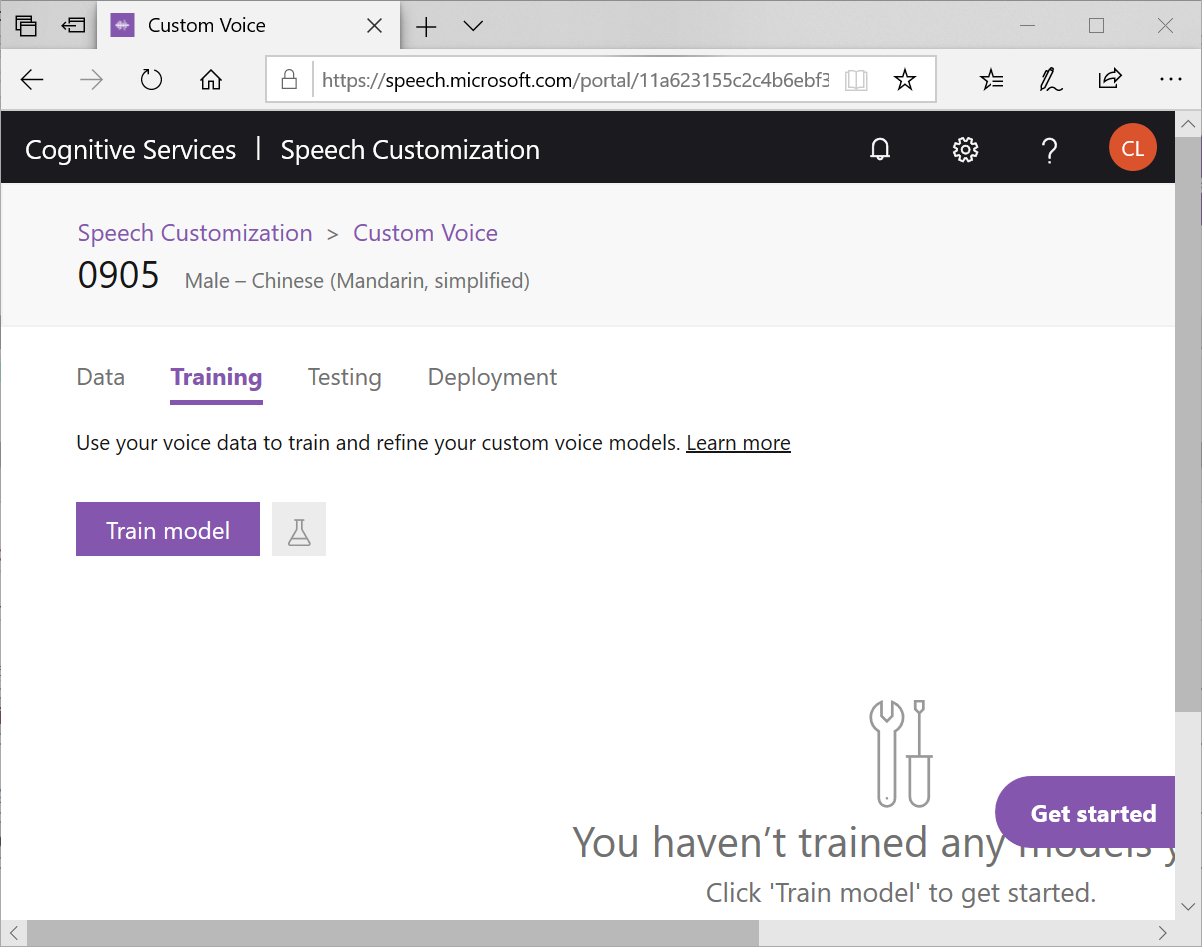
接著切到Training頁籤,按下Training
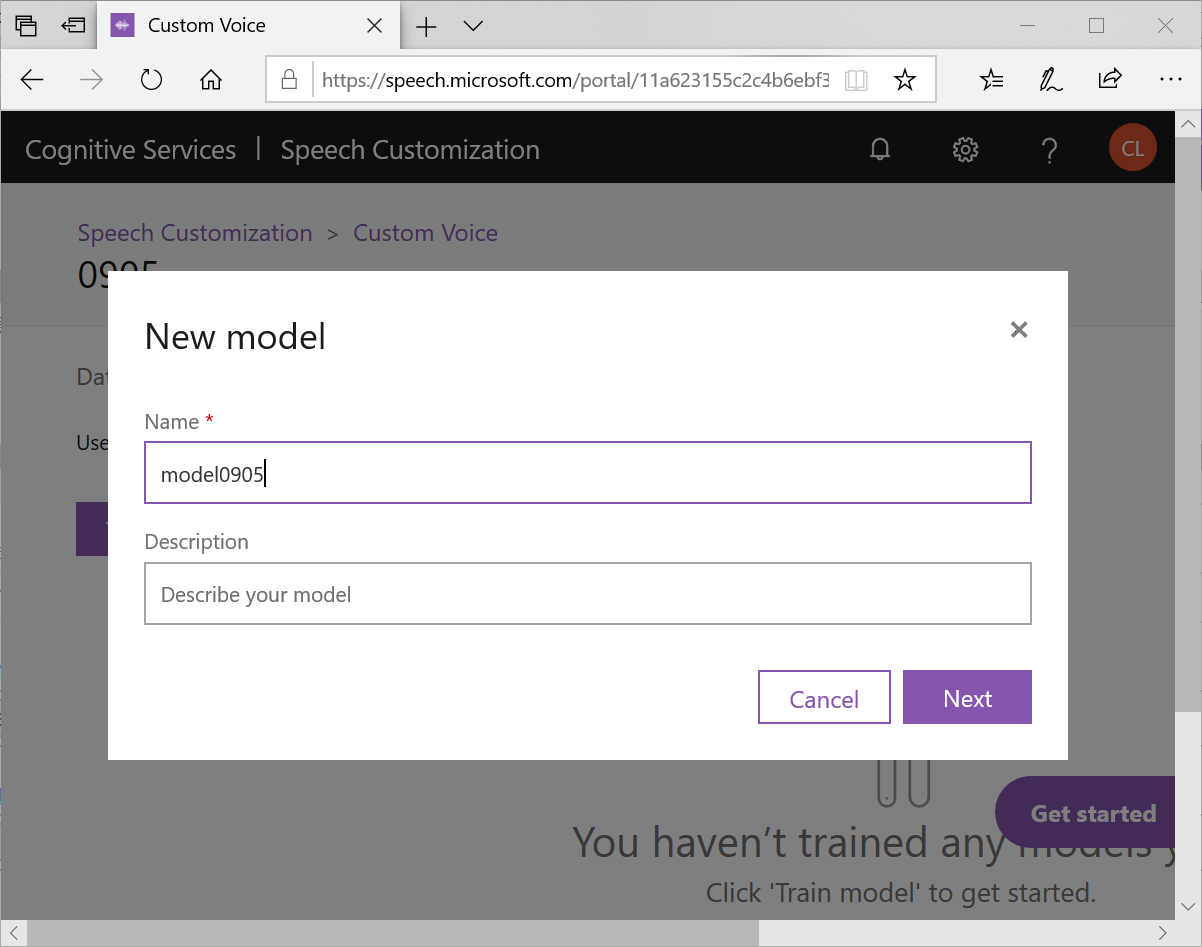
為模型取個名字,就可以按下Next
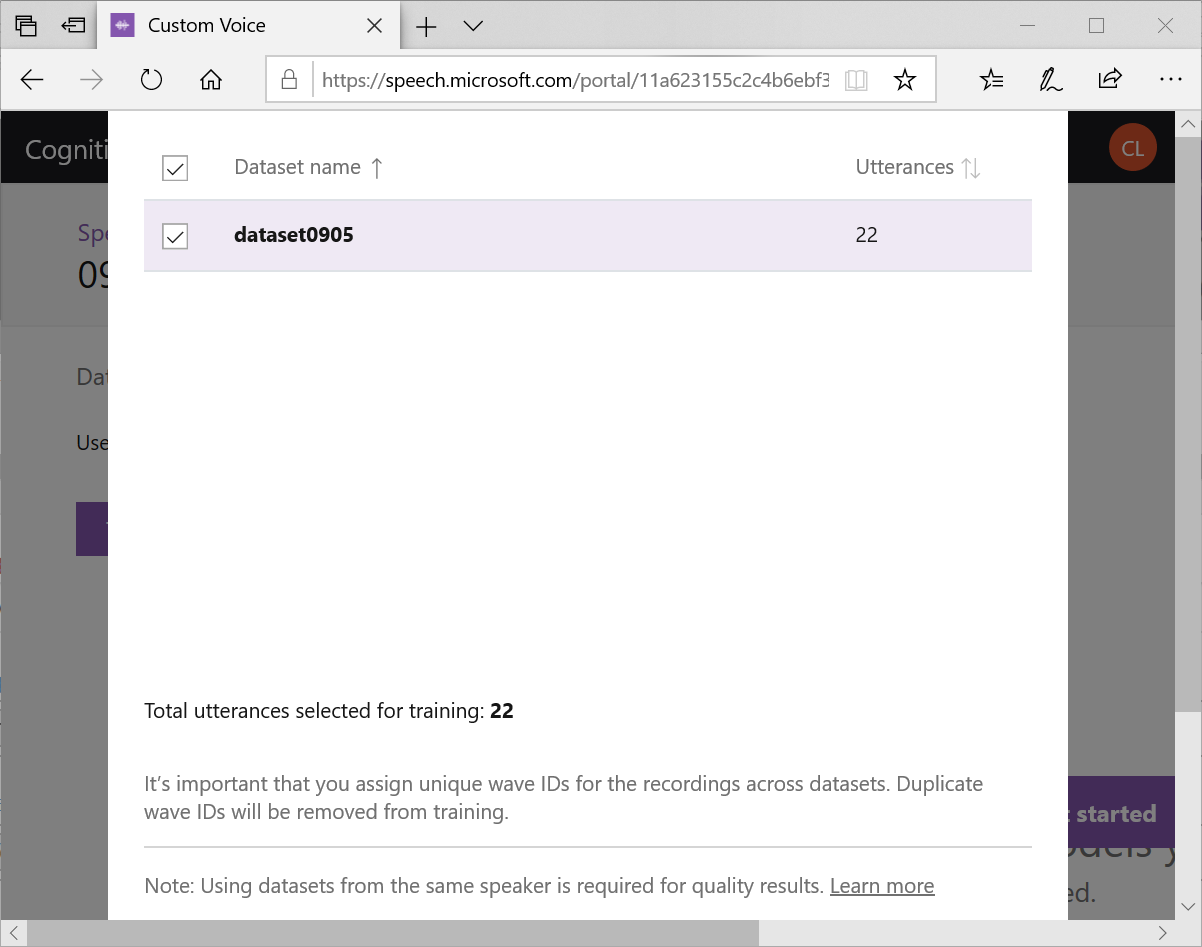
勾選剛才的dataset按下Next
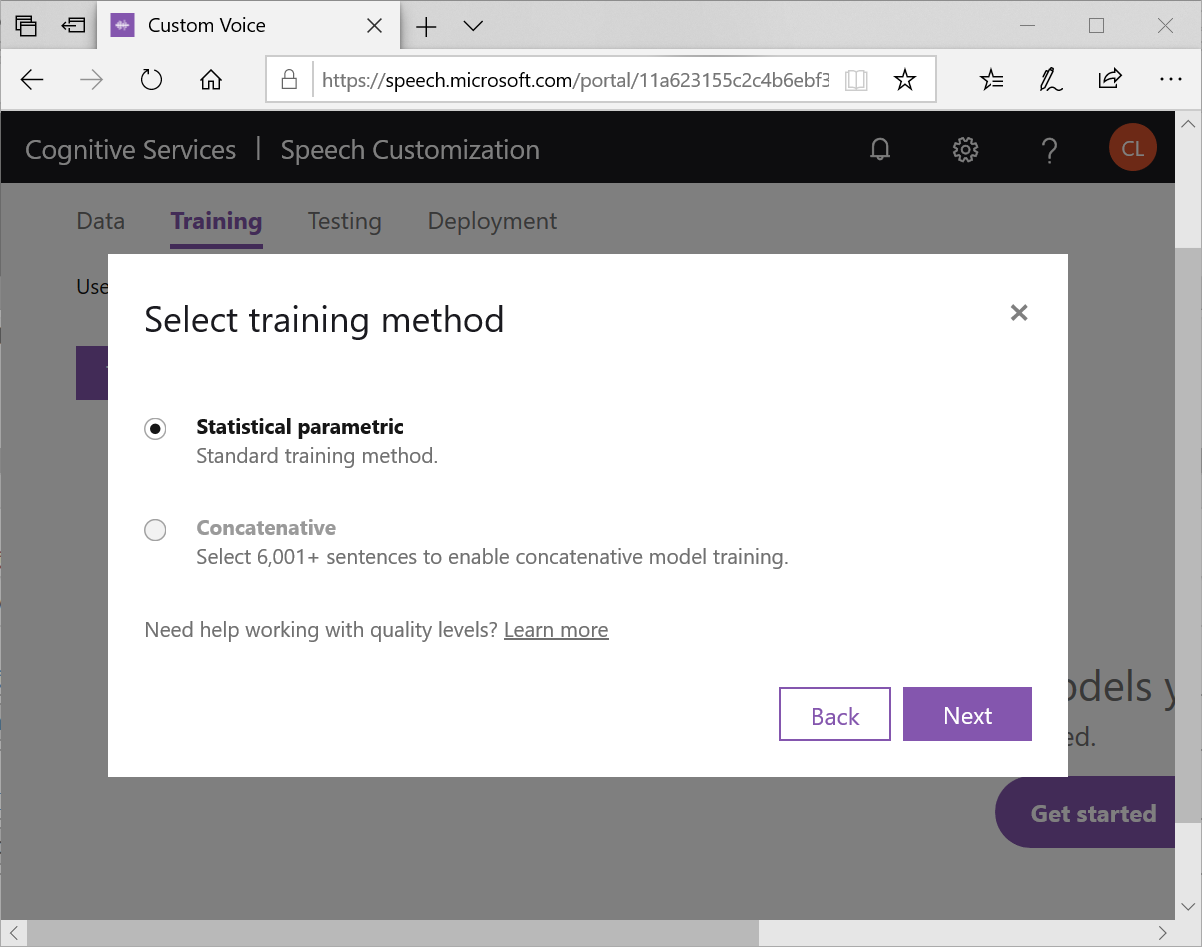
因為音檔小於6000句,所以只有標準的訓練方式 statistical parametric可以選擇,按下Next
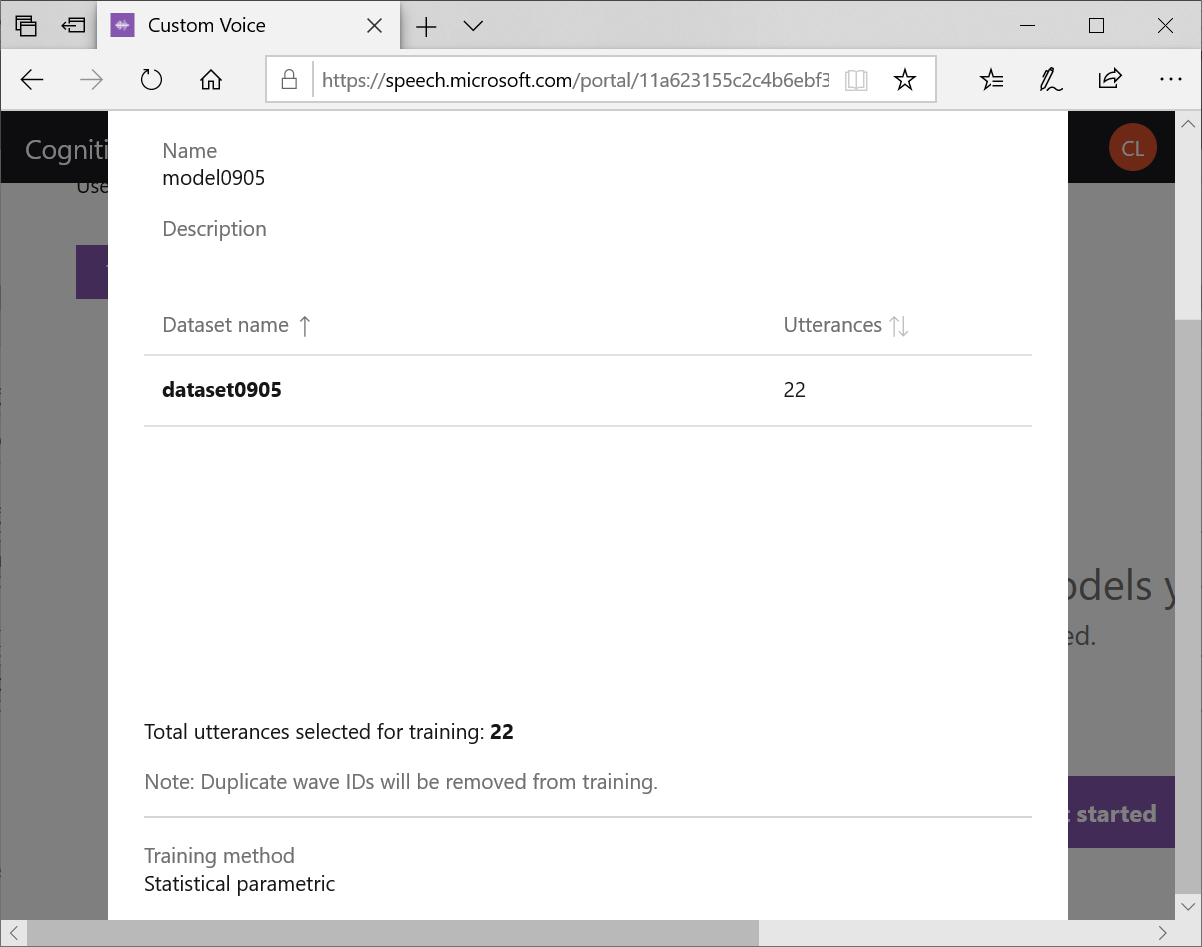
開始訓練,同上。一樣需要等到Status變成Succeeded才能進行下一步
接著切到Testing頁籤,按下Add test
選擇指定的Model
接下來,放一段新聞稿,讓電腦進行合成
等到Status變成Succeeded就可以聽看看,按下Play鍵
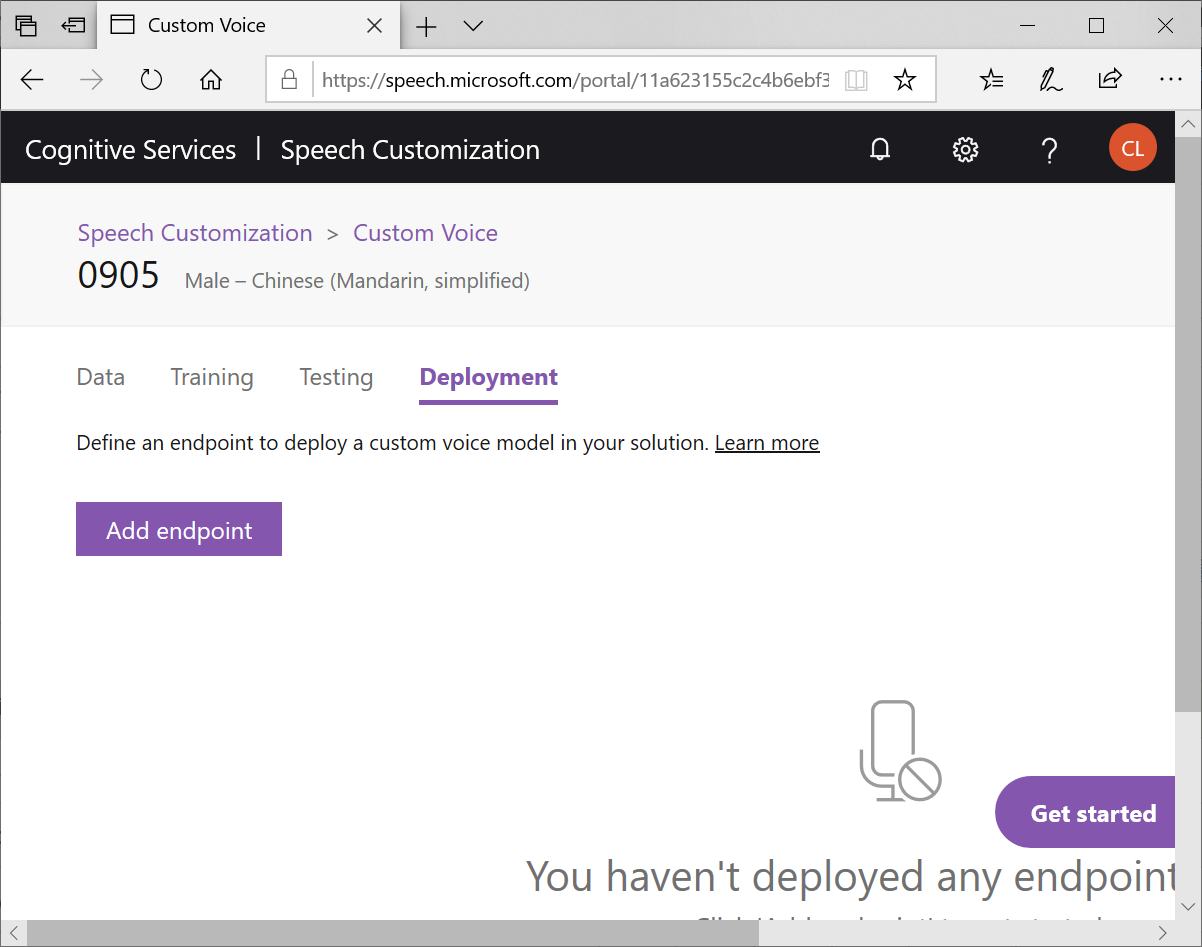
最後,我們切到Deployment頁籤,按下Add endpoint
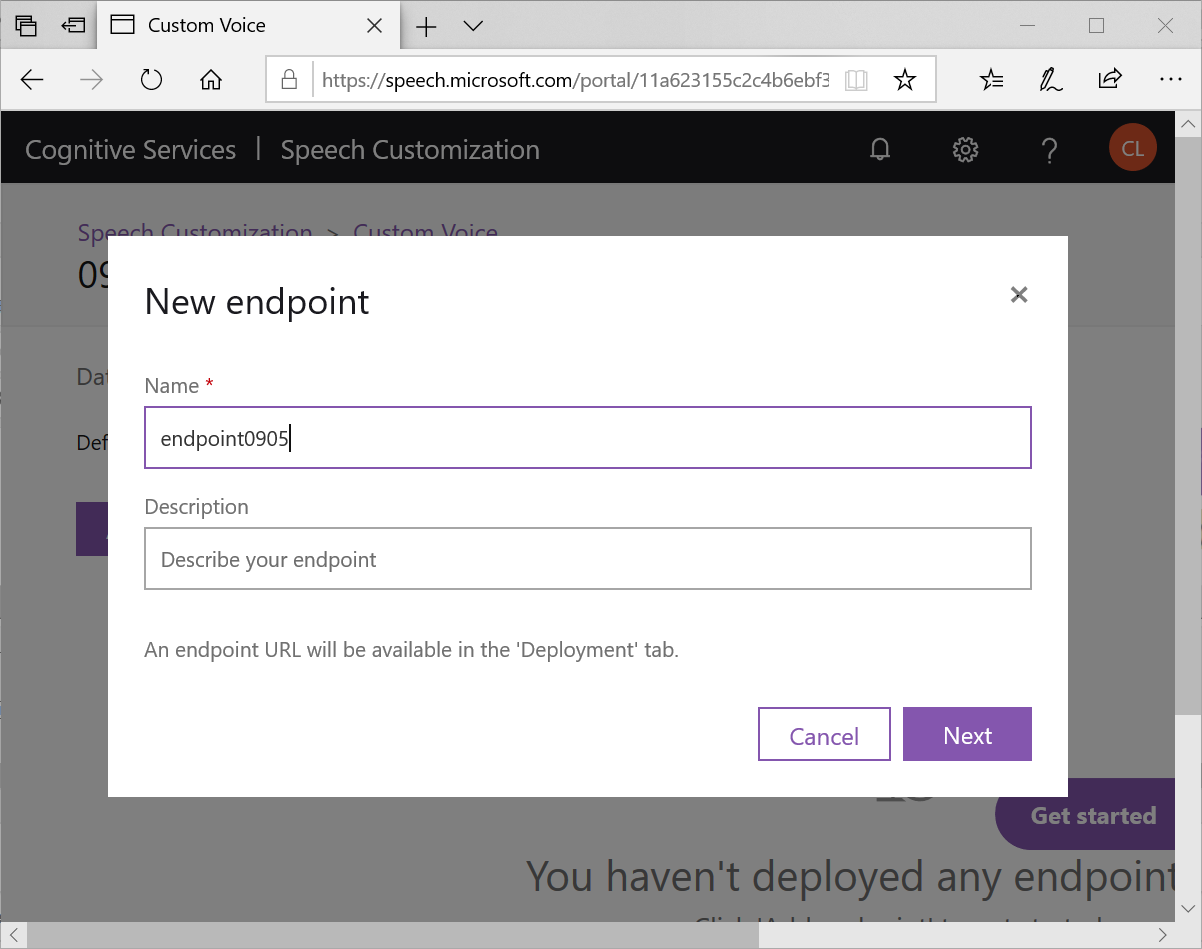
選擇指定的 Model
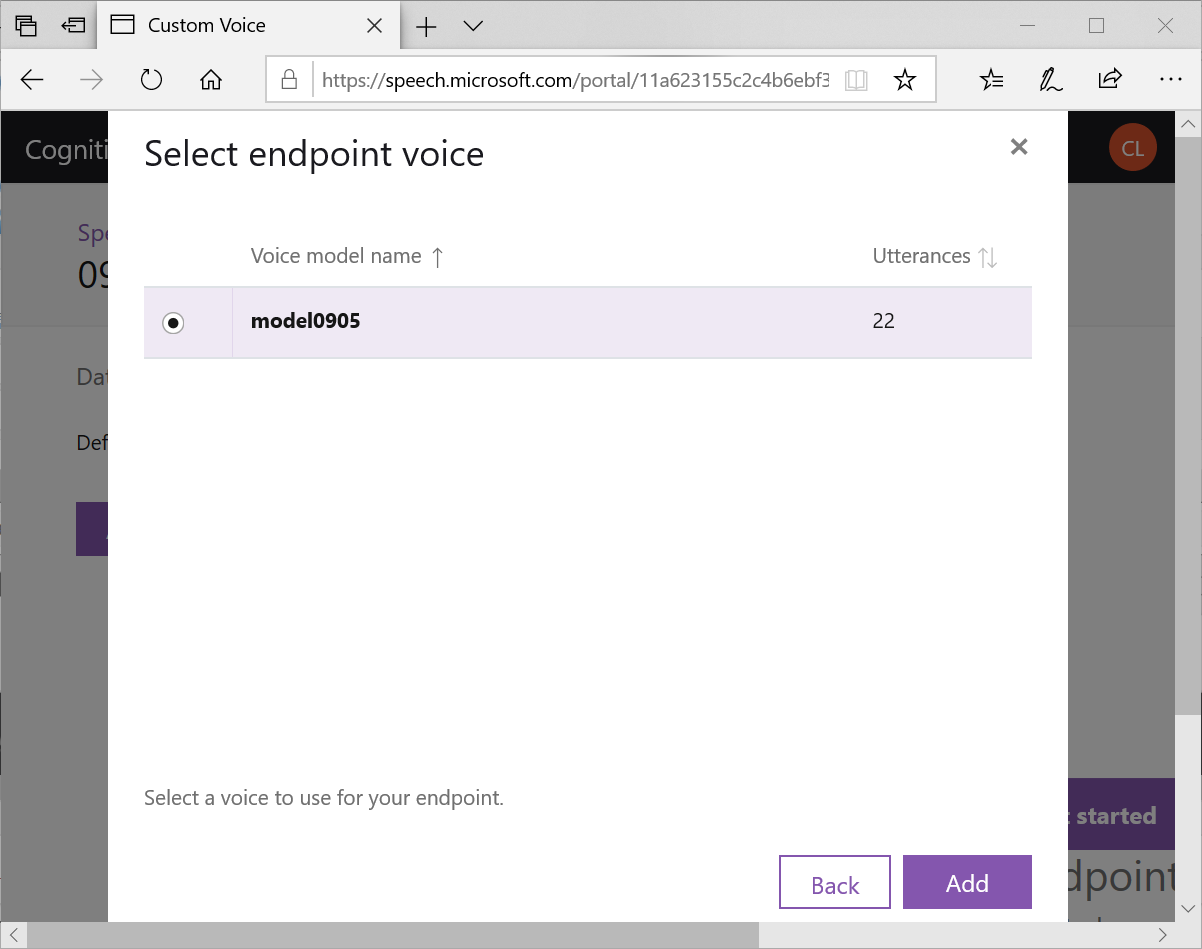
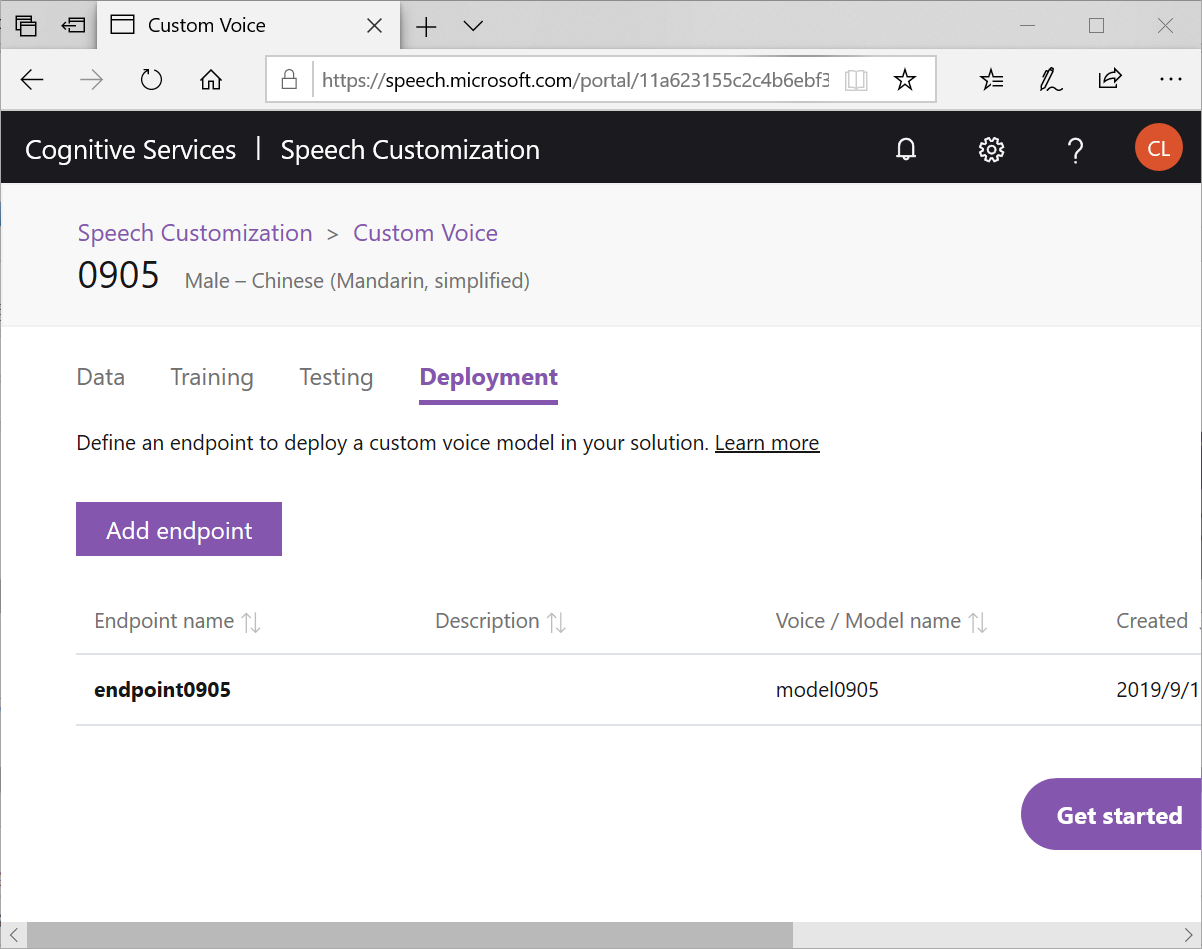
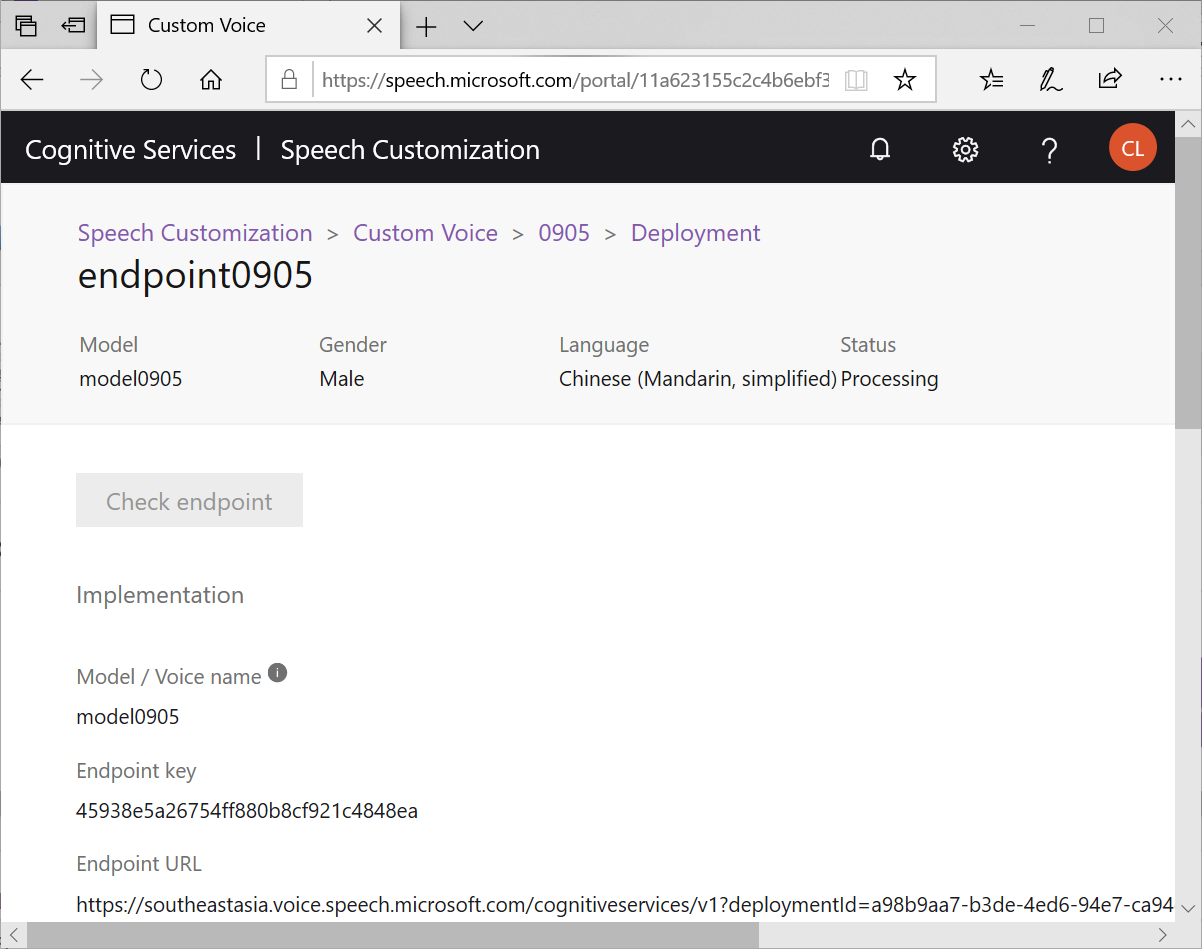
就可以讓這個模型被你的程式所呼叫,並且系統會自動生成C#,Java,Python三種範例供你使用,是不是很方便?個人覺得才22句,就已經讓 TTS有20%個人的聲音特色在裡面了,算是不錯的效果!是不是你也來試試呢?
結論:基礎於人類語言有著言簡意駭的特性,愈短的字詞中,愈是難以揣測。同理,在語音合成當中,不管是波形拼接式/統計參數式/端到端合成…哪一種方法,都是句子愈長效果愈好。
早期的語音合成,採用的是較不自然的波形拼接;接著進步到能透過上下文更聰明的統計參數式,以及搭配具有人物特性(例如繁體中文女聲 Mary, Carol, Winnie…) 的語意合成,讓死板的機械聲音開始融入角色扮演的新活力。然而,最近的端到端語音合成又更上一層樓,除了高效地平行運算,還能夠學習到更多人類的聲音特徵(例如:連音、氣音、呼吸、停頓…),讓語音合成能夠更自然、更生動。
我相信,未來的語音合成,除了現在的角色扮演,將來還可以讓相同的文字內容,指定不同的聲音性格(例如:急驚風、慢郎中、冷靜闡述、熱情奔放)來輸出,進而應用在許多的進階的場景(例如願景佈達、知識傳遞、撫慰人心、溫暖感動…等)。實現見人說人話,見鬼說鬼話的更高境界!
李秉錡 Christian Lee
Once worked at Microsoft Taiwan