Azure HDInsight 是微軟以Open source為基礎的巨量分析解決方案,不同於其他雲端服務Provider僅是提供機房空間缺乏佈署監控與管理介面,或是沒有SLA的保障。
在完整的解決方案中,包含了 Spark、Hive、MapReduce、HBase、Storm、Kafka 和 Microsoft R 伺服器…等(雲端的特性,一直會有更新更多的服務加進來),為客戶提供了最佳化開放原始碼分析叢集、 99.9% SLA 的支援。再加上事先整合好的ISV 應用程式,實現了企業級安全性和監視功能的巨量數據分析叢集。

人與人的連結,自從網際網路問世開始出現翻天地覆的變化。換句話說:多年前種下的一個種子,造成了數年後,類比轉數位的巨變(從錄音機、CD播放器、MP3播放器、手機、跨裝置的音樂訂閱服務)、DotCom商業大爆發與泡沫化、巨量資料時代(從BBS、搜尋引擎、入口網站、社群網路)的到來。
在巨量資料的初期,Doug Cutting等人(隨後成為 Yahoo 的員工),受到 Google 分散式儲存系統架構的啟發,設計出 Hadoop 來滿足大數據的儲存 HDFS(Hadoop Distributed File System)、運算(MapReduce)、資源管理調度YARN(Yet Another Resource Negotiator)三大需求,來取代關聯式資料庫。我們以計算全台灣所有學校的學生出生地為例:
- 由於當初容器技術與微服務還不成熟,透過 HDFS 遇到單機撐不住的 10TB資料大量運算時,可以用上下層 NameNode & DataNode 的架構,以 N個 DataNode 橫向擴充的方式。達到單一NameNode 與 DataNode 配額上限時,可以再增加 NameNode 繼續擴充。另外再搭配底層自動儲存為三份的冗餘又打散的設計(類似 RAID5 的概念,而非 RAID0),來預防硬體的故障。
- 如果儲存可以進行橫向的擴充,接下來就是要解決運算資源橫向擴充的問題。所以因應而生的 YARN 就是透過上下層 Resource Manager (運算資源的調度)與 Node Manager(資源的隔離)來滿足需求。類似公司一個 IT主管負責5個維運的 IT團隊,每個 IT再負責管理 10 台實體伺服器/虛擬機/容器…
- 類似最小可行性產品 MVP(Minimum Viable Product) 的觀念,如果我們想要統計某個學校60個班級中的學生出生地,1號同學負責算台北市、2號同學負責算新北市。我們來比較一下 60個班長 v.s. 20個負責統計縣市的同學,以出生地是最終的目的,當我們要統計100 間學校時,後者是比較直覺有效地。所以分解動作,Map是把計算出生地的任務分出去給同學(任務分解),而Reduce就是把同學計算出來的數字集結起來(結果的匯總)。
微軟有一個新的 Open source部門,除了致力於推廣開源軟體(包含自家的dot net基金會),也實質地與Apache、Hortonworks在巨量資料的這個領域上面合作。
具體的成果,包含了Apache在 Hadoop 2.7版後開始支援叢集可以運行在Windows 等規格上的制訂,讓更多習慣微軟的使用者可以更容易地使用 Hadoop;以及Hortonworks Data Platform(以下簡稱HDP)的產品以HDInsight的名稱上架到Azure雲端平台後,微軟接續提供使用者維運以及相關的服務。
所以在Azure HDInsight HDI 3.5其生態系中包含的產品與最新版本如下:Hadoop 2.7.3, HBase 1.1.2, Storm 1.0.1, Spark1.6.3, R Server 9.0, Interative Hive2.1.0, Kafka (preview) Azure HDInsight HDI 3.5, Hadoop 2.7.3, HBase 1.1.2, Storm 1.0.1, Spark1.6.3, R Server 9.0, Interative Hive2.1.0(preview), Kafka (preview)
下圖是Hortonwork的Roadmap

在開始介紹 HDInsight 之前,想跟大家說:雖然使用者可以依據自己的習慣或喜好選擇底層要採用 Linux或Windows,擁有相同的SLA保障。但是無關對錯只看什麼比較適合,以參數的最佳化以及許多Open source的原生工具可能在Windows無法運行的前題下,個人的心得還是建議選擇Linux做為叢集的底層。
接下來為大家介紹 HDInsight 生態系:
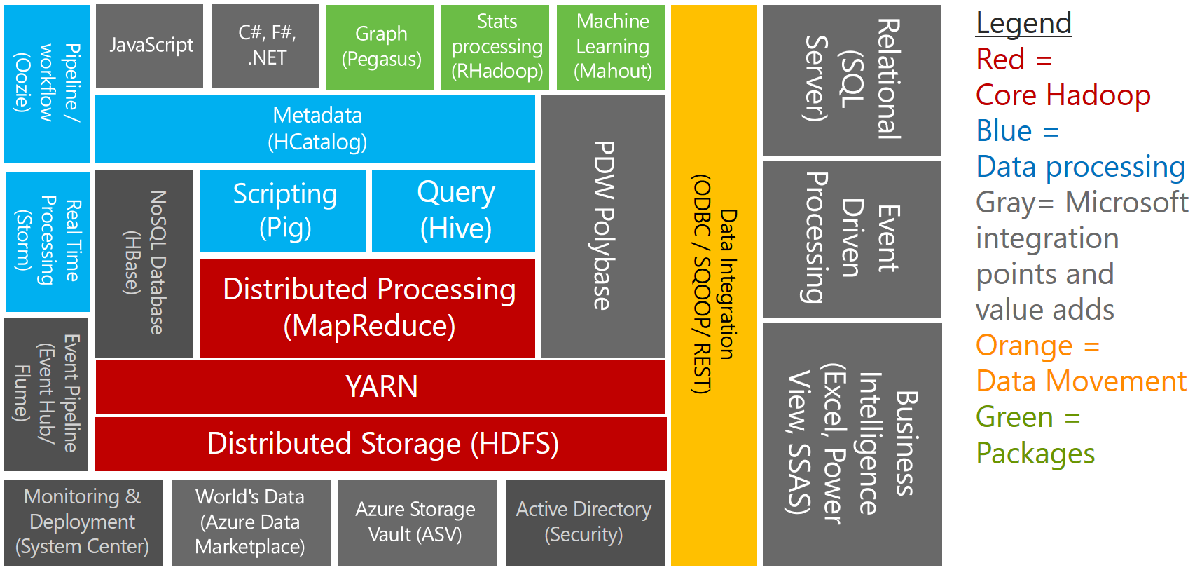
Apache Hadoop:使用 HDFS 提供可靠的資料儲存,以及提供 MapReduce 程式設計模型來進行分散式的資料分析。
Apache Spark:一種可支援In-memory處理的分散式處理架構,可大幅提升巨量資料分析應用程式的效能、與SQL存取的效能、串流資料與機器學習的效能。
Apache HBase:建置於 Hadoop 上的 NoSQL 資料庫,可針對大量非結構化及半結構化資料 (可能是數十億的資料列乘以數百萬的資料行),提供隨機存取功能和強大一致性。
Microsoft R 伺服器︰可用來裝載和管理並行、分散式 R 程序的企業級伺服器。 這項新功能可讓資料科學家、統計學家以及 R 程式設計人員隨其所需存取 HDInsight 上可調整大小的分散式分析方法。
Apache Storm:分散式、即時的運算系統,可快速處理大型的資料串流。 Storm 以受管理叢集的形式在 HDInsight 中提供。
Apache 互動式 Hive (Live Long and Process)︰更快速之互動式 Hive 查詢的記憶體內快取。 請參閱在 HDInsight 中使用互動式 Hive。
Apache Kafka ︰用來建立串流資料管線和應用程式的開放原始碼平台。 Kafka 也提供訊息佇列功能,可讓您發佈和訂閱資料串流。
已加入網域的叢集︰Active Directory 網域中加入的叢集,如此您可以控制存取並提供對資料的管理。
具指令碼動作的自訂叢集:具指令碼的叢集,該指令碼於佈建期間執行,並安裝其他元件。
在Visual Studio的 NuGet可以直接下載函式庫來開發 Microsoft .NET MapReduce API for Hadoop
當客戶問到微軟的Hadoop跟其他公有雲供應商有什麼不同?我是透過這個比喻,Hadoop的成員logo幾乎都是各種動物(有機會可以找一篇來說明Apache的專案命名與Logo的選擇,非常有趣!),所以Hadoop的管理者,可以算是個馴獸師。

在微軟的平台上,至少在底層換了37 combined committers重新改寫的最佳化元件,再加上前端節點(HeadNode)複寫、異地資料複寫、內建的待命NameNode…等HA機制的強化,所以才敢提供99.9%的SLA,不然注定是個賠錢貨。
或是你可以把它想成,微軟幫你植了37顆晶片到動物中,讓你演出更逼真更出色!
另外就是安全性,各位覺得AD安全嗎?所以在高階的Azure HDInsight就是加了AD,讓Hadoop更安全!

Apache基金會在2017/03 發布了Hadoop 2.8版,一口氣新增了2919項的更新功能或新特色。接下來等到2.8.1或2.8.2比較穩定後,就可以在微軟的Azure平台中使用到相對應的最新版本了

目前國外的成功案例比較多,在台灣,有一家叫黑丸的甜品連鎖業者,他們的仙草很厲害,甚至已經發展到國外去展店了。他們成功地應用巨量數據在經營管理,尤其是在產品的開發上可以同時滿足全球化與在地化,算是台灣之光。

**強者我同事上官林傑,他無私地寫了一篇教大家應用大數據科技在零售業的技術文章,非常值得參考!
李秉錡 Christian Lee
Once worked at Microsoft Taiwan